




















Оглавление
- Исполнительное резюме
- Контекст и базовые принципы проектирования
- Архитектуры и топологии
- Маршрутизация, адресация, IPv4/IPv6 и DNS
- Безопасность, NAT traversal, MTU, firewall и наблюдаемость
- Отказоустойчивость и масштабирование
- Автоматизация и примеры конфигураций
- Тестирование, troubleshooting checklist, ограничения и альтернативы
- Открытые вопросы и ограничения этого отчета
- Практический вывод
Исполнительное резюме
Для сценария, где нужно связать офис с NAT и динамическим IP, облако в AWS/Azure/GCP и выделенные серверы в дата-центрах, наиболее практичная базовая архитектура — hybrid hub-and-spoke: стабильный облачный узел с публичным статическим адресом выступает хабом, а офис и часть серверов в ЦОД выступают spoke-узлами, которые сами инициируют туннель. Это хорошо сочетается с моделью WireGuard: интерфейс хранит публичные ключи peer’ов, Endpoint у peer’а может автоматически обновляться на адрес последнего корректно аутентифицированного пакета, а PersistentKeepalive держит NAT/stateful firewall mapping живым для входящего трафика через UDP. Для офиса за NAT это обычно лучший стартовый вариант. Для маршрутизации выбор зависит от масштаба. Статика подходит для 2–5 площадок и понятных префиксов. Как только появляются несколько облаков, резервные каналы, несколько дата-центров или необходимость автоматического failover, выигрывает BGP поверх WireGuard, обычно через FRR: он поддерживает полноценный BGP, interface-based peering, route-map/policy, BFD и multipath. Policy-based routing имеет смысл как дополнительный механизм — например, чтобы увести только часть трафика через туннель или разные туннели, но не как единственный способ управлять большим межсайтовым контуром. FRR сегодня активно поддерживается и прямо позиционируется как форк Quagga; Quagga на практике следует считать legacy-вариантом. С точки зрения безопасности WireGuard остается сильным выбором для site-to-site: протокол использует Noise_IK поверх UDP, ChaCha20-Poly1305, Curve25519, BLAKE2s и HKDF; handshake регулярно обновляет сессионные ключи, обеспечивая PFS, а optional PresharedKey добавляет дополнительный симметрический слой. При этом у WireGuard есть и важные ограничения: он не занимается обфускацией, не работает поверх TCP, не имеет встроенной PKI/IKE-плоскости уровня IPsec и не является “полноценной control plane-системой” сам по себе — именно поэтому для продакшн site-to-site почти всегда приходится проектировать внешние механизмы маршрутизации, HA, автоматизации и мониторинга. В облаках критично помнить, что WireGuard-хаб часто становится router appliance, а значит нужны облачно-специфичные настройки. В AWS надо отключить source/destination checks и направить нужные VPC route table на инстанс/ENI хаба; в Azure — включить IP forwarding и задать UDR, при необходимости включив форвардинг и в гостевой ОС; в GCP — включить can-ip- forward и задать кастомные static routes или next hop на instance/ILB. Без этого туннель может “подниматься”, но трафик между подсетями не пойдет. Для отказоустойчивости лучший паттерн — не пытаться “магически” балансировать один и тот же peer на несколько backend’ов, а строить несколько независимых туннелей/ интерфейсов и давать маршрутизации выбрать путь: статические маршруты с разными метриками для малого масштаба, либо BGP + BFD для среднего и крупного. UDP L4 load balancer’ы в облаках существуют и полезны, но для WireGuard они не снимают проблемы состояния peer’ов и cryptokey routing. Использовать их стоит осознанно, чаще для ingress/HA fronting хаба, а не как основную замену multi-tunnel failover. Если параметры у вас не уточнены, наиболее безопасный набор допущений для проектирования такой: Linux gateway на каждой площадке, nftables по умолчанию, статический публичный IP у облачного хаба, отдельный WireGuard интерфейс на peer при использовании BGP/eBGP, статическая адресация overlay, наблюдаемость через wg show + systemd journal + cloud flow logs, и обязательное тестирование failover до ввода в эксплуатацию. Эти допущения ниже взяты как базовый шаблон, но в каждом месте я отмечаю альтернативы.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Контекст и базовые принципы проектирования
WireGuard — это L3-туннель поверх UDP. Он не строит “соединение” в классическом смысле, а опирается на очень простой handshake и на так называемый cryptokey routing: каждому peer сопоставлен публичный ключ и набор AllowedIPs , которые одновременно определяют, какой исходный адрес от peer допустим, и какой трафик надо отправлять этому peer’у. Это одновременно делает конфигурацию WireGuard элегантной и накладывает жесткие требования на проектирование адресации и маршрутов: overlap’ы и неаккуратный дизайн prefixes превращаются не просто в routing bug, а в ошибку на уровне security/routing semantics. Практически это означает следующее. Если у вас один офис за NAT, один облачный узел с публичным IP и один или несколько dedicated-серверов, то стартовая модель почти всегда такая: офис всегда инициирует туннель на облако; cloud-hub имеет стабильный public IP; dedicated-серверы либо тоже сходятся в hub, либо строят отдельные туннели в hybrid/full-mesh контур. wg-quick может автоматически поднять интерфейс, адреса, MTU и маршруты из AllowedIPs , а при default route он использует ip rule ; но в более сложных сценариях сам же upstream рекомендует уходить на более специализированный network manager или на прямое управление через wg(8) и ip(8) . Для site-to-site малого масштаба wg-quick удобен, для medium/large желательно более явное управление. Важная operational-деталь: если peer находится за NAT или stateful firewall, а вы хотите, чтобы он мог получать входящие пакеты после долгого простоя, нужен PersistentKeepalive ; WireGuard quick start прямо рекомендует типичный интервал около 25 секунд для широкого набора firewall/NAT. На стороне хаба Endpoint для такого spoke можно и не фиксировать: после получения корректно аутентифицированных пакетов WireGuard обновит endpoint peer’а на наиболее свежий source IP:port. Именно поэтому динамический IP у офиса не мешает site-to-site, пока офис — инициатор. Если вам нужна dual-stack архитектура, WireGuard умеет и IPv4, и IPv6 на уровне адресов интерфейса, AllowedIPs и DNS-параметров wg-quick , а сам transport может идти по UDP и через IPv4, и через IPv6. На практике это позволяет либо вести чисто IPv4 overlay, либо завести dual-stack overlay поверх IPv4 underlay, либо полноценно dual-stack underlay/overlay — выбор зависит уже не от WireGuard, а от возможностей ваших сетей и cloud edge. Ниже я исхожу из следующих неуточненных, но разумных допущений: Linux 6.x/современное ядро, Debian 12 или Ubuntu 24.04 LTS, nftables как основной firewall layer, отдельный gateway/ VM на site, а не пользовательский хост, и выделенная overlay-адресация, никак не пересекающаяся с реальными LAN/VPC/DC префиксами. Если у вас MikroTik, pfSense, OPNsense или hardware appliance, архитектурная логика останется той же, но syntax и механика HA будут другими.
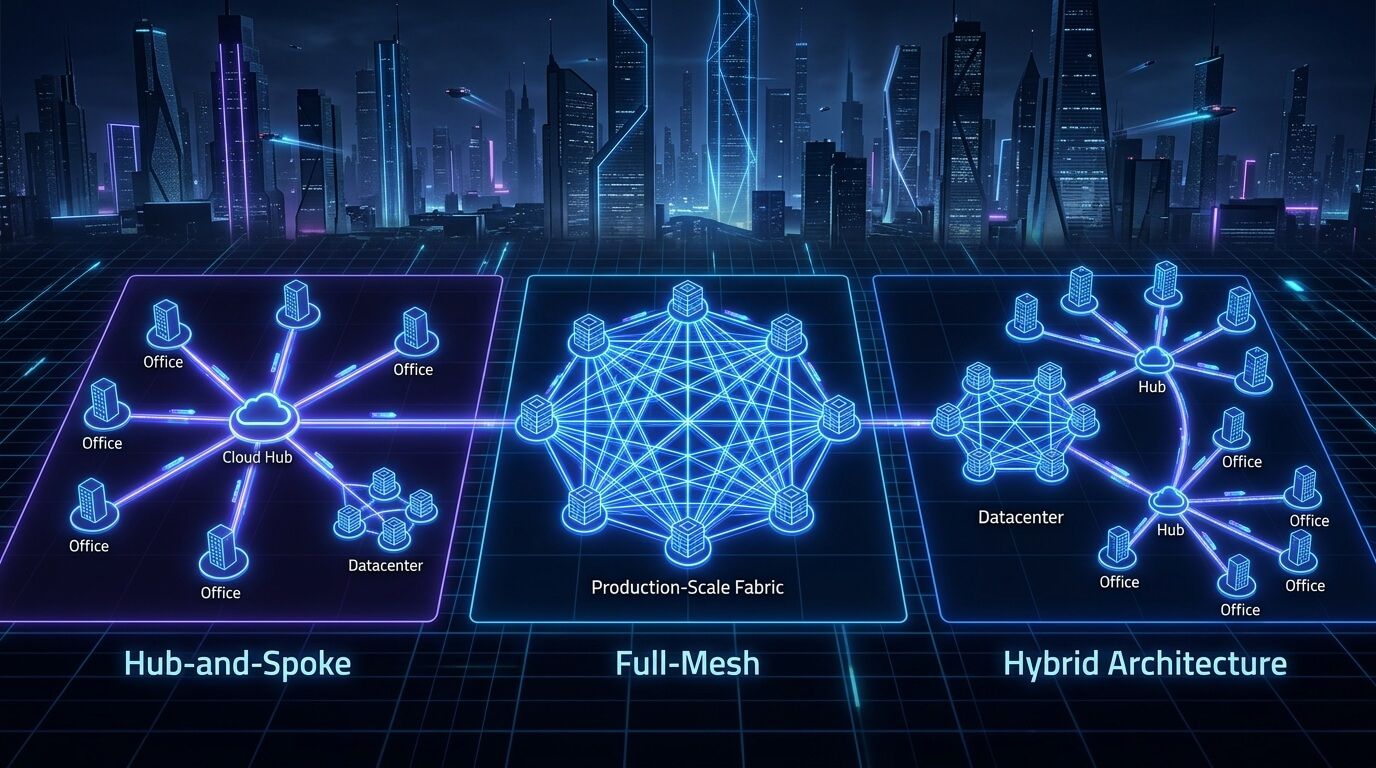
Архитектуры и топологии
Для вашего набора площадок существуют три базовые топологии: hub-and-spoke, full-mesh и hybrid. На практике “правильная” почти всегда зависит не от моды, а от трех вопросов: где есть стабильный public IP, сколько у вас площадок, и нужна ли автоматическая маршрутизация/HA. WireGuard сам по себе одинаково работает в любой из этих топологий; различаются operational properties, blast radius и сложность маршрутизации. Сравнение ниже — прикладной синтез по WireGuard semantics, поведению AllowedIPs , возможностям FRR/BGP и облачным требованиям к router appliance. Топология Когда выбирать Плюсы Минусы Практический вывод Hub-and- spoke Простая модель, Офис за NAT, 2– 10 площадок, есть один стабильный минимум публичных endpoint’ов, удобный cloud/public hub контроль ACL и логов Хаб становится точкой концентрации трафика и отказа Лучший старт для office + cloud + dedicated 3–6 крупных площадок, Лучшие path’ы,
peer’ов растетКоличество Full-mesh нужен прямой меньше hairpin квадратично, east-west traffic через hub сложнее ключи и Подходит для нескольких дата- центров, но лучше с BGP маршруты между ЦОД Есть cloud hub, но some DC/DC Hybrid или cloud/DC потоки должны идти напрямую Хороший баланс between simplicity and latency Сложнее адресный план и failover logic Обычно лучший production- вариант после пилота Ниже — типовая hub-and-spoke схема для офиса за NAT, облака и выделенных серверов. Публичный и стабильный endpoint есть только у хаба. Это самый рациональный начальный вариант для вашего запроса. flowchart LR OFFICE["Офис\nGW за NAT / динамический IP\nLAN: 172.16.10.0/24"] HUB["Cloud Hub\nстатический public IP\nOverlay: 10.200.0.1"] DED1["Dedicated DC-1\nLAN: 10.50.0.0/24"] DED2["Dedicated DC-2\nLAN: 10.60.0.0/24"] OFFICE -->|WG over UDP\nPersistentKeepalive| HUB DED1 -->|WG over UDP| HUB DED2 -->|WG over UDP| HUB Если между дата-центрами уже много взаимного east-west traffic или вам нужно избежать hairpin через hub, появляется смысл в hybrid: офис по-прежнему идет в hub, а DC↔DC или cloud↔DC критичные потоки — по прямым туннелям. Собственно, это тот момент, когда BGP поверх отдельных point-to-point WG-интерфейсов начинает окупаться. flowchart LR OFFICE["Офис\nNAT / динамический IP"] HUB["Cloud Hub"] AWS["AWS VPC"] AZ["Azure VNet"] GCP["GCP VPC"] DC1["DC-1"] DC2["DC-2"] OFFICE --> HUB AWS --> HUB AZ --> HUB GCP --> HUB DC1 --> HUB DC2 --> HUB DC1 <-->|Direct WG + BGP| DC2 AWS <-->|Direct WG + BGP| DC1 Для full-mesh между дата-центрами WireGuard технически годится, но operationally разумно либо ограничиться несколькими площадками, либо сразу принять, что вы строите не просто VPN, а небольшую routing fabric. В этом случае лучше не пытаться делать “один большой wg0 на всех” с хаотичными prefix’ами, а давать по интерфейсу на peer и поднимать поверх них eBGP/iBGP. FRR прямо поддерживает interface-based BGP peer для point-to-point связей, что очень удобно именно на таких туннелях. flowchart LR DC1["DC-1"] DC2["DC-2"] DC3["DC-3"] DC1 <-->|wg-dc1-dc2| DC2 DC1 <-->|wg-dc1-dc3| DC3 DC2 <-->|wg-dc2-dc3| DC3 Для облаков действуют разные требования к тому, чтобы хаб/шлюз вообще мог форвардить межсетевой трафик. В AWS у инстансов по умолчанию включены source/destination checks; для
router/NAT appliance их надо отключить и направить route tables через него. В Azure нужны UDR и
IP forwarding; в GCP — can-ip-forward и custom routes, а в более развитых схемах возможенILB как next hop для hub-and-spoke appliance patterns. Это влияет не на WireGuard-конфиг как таковой, а на то, почему “туннель жив, но packets не маршрутизируются”.
Маршрутизация, адресация, IPv4/IPv6 и DNS
Статическая маршрутизация Для небольшого контура statics — абсолютно нормальный выбор. Upstream wg-quick умеет выводить маршруты напрямую из AllowedIPs и добавлять их в routing table; если в AllowedIPs попадает 0.0.0.0/0 или ::/0 , он даже использует ip rule для корректного override default route. Это удобно для простых сценариев, но в большом site-to-site это же свойство означает, что дизайн prefixes должен быть дисциплинированным, а туннельная адресация не должна пересекаться с рабочими подсетями. Под статическую схему удобнее всего брать либо отдельную overlay-сеть для всех peer’ов, либо point-to-point подсети per tunnel. Для малого числа площадок я бы рекомендовал простой адресный план такого типа: • • • overlay IPv4: 10.200.0.0/24 overlay IPv6 ULA: fd42:200::/64 реальные LAN/VPC/DC prefixes анонсируются как AllowedIPs только там, где они реально нужны Это не требование WireGuard, а operational best practice: так проще читать конфиги, ловить ошибки маршрутизации и позже перейти на BGP без полной пересборки схемы. Семантически это полностью согласуется с тем, как AllowedIPs и Address описаны в wg(8) и wg- quick(8) . BGP через FRR Как только у вас начинаются резервные хабы, несколько облаков, несколько dedicated-гейтов или желание автоматического failover, BGP становится естественным следующим шагом. BGP по RFC 4271 обменивается reachability information и policy; FRR реализует полноценный BGP, route-maps, интерфейсных peer’ов, BFD и multipath/static ECMP-механики. В production для WireGuard это обычно самый аккуратный способ отделить туннель как transport от маршрутизации как control plane. FRR особенно хорошо ложится на WireGuard, если вы делаете по одному WG-интерфейсу на
peer, а не один общий интерфейс для всего мира. Документация FRR прямо описываетneighbor PEER interface ... remote-as ... для interface-based BGP peer’ов на point-to- point соединениях. Это позволяет строить довольно чистую модель: wg-dc1-dc2 — point-to- point transport, поверх него BGP-соседство, а дальше уже route-policy, prefix-lists, communities, MED/local-pref и прочее. Для failover BFD поверх BGP полезен почти всегда. FRR рассматривает BFD как lightweight fault- detection protocol с низкой латентностью, который отлично работает и поверх туннелей, где link- state сам по себе не всегда отражает фактическую готовность dataplane. В связке WireGuard + FRR + BFD получается именно то, чего WireGuard “из коробки” сам не дает: быстрый routing reconvergence, а не просто “туннель жив/не жив”. Policy-based routing PBR имеет смысл там, где вам нужно завести через туннель не всю площадку, а только часть трафика: например, только админский SSH/RDP, только backup network, только prefixes конкретных приложений, или разные виды трафика через разные хабы. wg-quick(8) сам показывает пример policy routing через Table = ... и PostUp = ip rule ... , а FRR имеет полноценный PBR-блок для Linux, в котором можно матчить source/destination IP, порты, DSCP и mark. Важно только не подменять PBR нормальную межсайтовую маршрутизацию: для общего reachability fabric он слабее BGP, а для больших схем еще и хуже объясняется в эксплуатации. Сравнение подходов к маршрутизации Сводная таблица ниже — практический выбор для site-to-site на WireGuard. Она опирается на semantics wg-quick / wg , RFC 4271 и возможности FRR. Подход Когда подходит Преимущества Ограничения Рекомендация Статические маршруты До ~5 площадок, мало изменений Самый простой, понятен без routing Ручной failover, ручное Отличный пилот и малый suite добавление прод BGP через Multi-site, multi- маршрутов, policy, FRR cloud, HA, DR failover, масштабируемость Auto-learn PBR Частичная маршрутизация, selective traffic steering Гибко для прикладных потоков IPv4, IPv6 и DNS prefixes Сложнее конфиг и Лучший production для эксплуатация medium/large Не решает Использовать общий routing как fabric дополнение WireGuard нативно поддерживает IPv4 и IPv6 и в адресах интерфейса, и в AllowedIPs , и в DNS- параметрах wg-quick . Это дает три рабочих варианта: чисто IPv4 overlay, dual-stack overlay на IPv4 underlay и полноценный dual-stack underlay/overlay. Если вы не уверены, что на всем пути корректно работает PMTUD и IPv6 path стабильный, лучше начать с IPv4-underlay и, при необходимости, добавить IPv6 overlays позже. С DNS у WireGuard есть важное ограничение: сам протокол не является сервисом сервис- дискавери. У wg-quick есть DNS= — то есть удобный клиентский механизм установки DNS servers/search domains через resolvconf , но site-to-site name resolution все равно нужно проектировать отдельно. Практически это значит: либо используете собственные резолверы, доступные через туннель, либо делаете conditional forwarding/split DNS между площадками. Полагаться на “магический” DNS от WireGuard не стоит; этого уровня control plane в нем нет.

Безопасность, NAT traversal, MTU, firewall и наблюдаемость
Криптография, ключи и rekeying WireGuard использует Noise_IK handshake, ChaCha20-Poly1305 для шифрования, Curve25519 для ECDH, BLAKE2s для hashing, SipHash24 и HKDF. Handshake периодически обновляет сессионные ключи, а whitepaper дает конкретные ориентиры по таймерам: Rekey-After-Time 120 секунд, Reject-After-Time 180 секунд, Keepalive-Timeout 10 секунд, Rekey-Timeout 5 секунд. Для практической эксплуатации это означает две вещи: во-первых, протокол действительно рассчитан на частую ротацию session keys; во-вторых, если вы видите sporadic packet loss или кратковременные path changes, WireGuard обычно переживает это хорошо именно за счет простой timer state machine. PresharedKey в WireGuard не обязателен, но upstream пишет прямо: он добавляет симметрический слой к уже существующей public-key cryptography и может использоваться как дополнительный слой для post-quantum resistance. В проде для site-to-site я рассматриваю PSK как опцию “усиления без большого operational cost”, особенно когда peer’ов немного и вы готовы хранить еще один секрет на пару peer’ов. NAT traversal и офис с динамическим IP WireGuard “тихий” по умолчанию: он не шлет лишний трафик, пока нечего отправлять. Для
peer’ов за NAT это отлично до тех пор, пока им не нужно принимать входящие пакеты последолгого простоя. Тогда нужен PersistentKeepalive , который шлет authenticated empty packets, чтобы NAT/stateful firewall не закрыл mapping. Quick Start прямо рекомендует ориентироваться на 25 секунд как sensible interval для широкого набора firewall’ов. В сочетании с тем, что Endpoint может автоматически обновляться на most recent authenticated source IP:port, это и делает возможным production-сценарий “офис с динамическим IP как spoke”. Но есть принципиальная граница. WireGuard не является NAT traversal framework уровня Tailscale/ DERP: если обе стороны за жестким NAT/CGNAT и ни у одной нет достижимого стабильного ingress endpoint, вам нужен либо промежуточный хаб с публичным IP, либо иной overlay/control plane. WireGuard как протокол решает keepalive/manual peering очень хорошо, но не закрывает весь класс проблем peer discovery и relay. Это уже либо архитектура с hub, либо другой продуктовый слой. MTU и производительность
wg-quick умеет автоматически вычислять MTU по endpoint addresses или default route и прямопишет, что это “обычно разумный выбор”. Для production site-to-site мой практический совет на этой базе такой: сначала оставьте auto MTU, затем измерьте реальный path ping -M do / tracepath , и только если видите fragmentation, blackhole PMTUD или резкое падение throughput на длинных потоках, фиксируйте меньший MTU вручную. Это надежнее, чем заранее “магически” выставлять одно число на все сайты. Официальная performance page WireGuard сама предупреждает, что опубликованные benchmark’и “old, crusty, and not super well conducted”, а whitepaper подчеркивает, что производительность сильно зависит от kernel datapath, offload’ов и пакетной обработки. Поэтому универсальных “ожидаемых Mbps” для вас без реального железа и RTT я не даю. Верный подход — мерить свой path: iperf3 single stream и parallel streams, CPU usage на обоих концах, packet loss, MSS/MTU behavior, latency under load. Firewall и DDoS WireGuard сам по себе не “прячет” трафик от DPI и не решает весь класс volumetric DDoS. Его сильная сторона — простая и надежная криптография, а не обфускация; это прямо указано в разделе Known Limitations. На уровне самого протокола есть защита от части resource exhaustion через mac1/mac2 и cookie reply messages при load conditions, но upstream также честно пишет, что до момента, пока mac2 не “включится”, ECDH still costs CPU. Поэтому production-защита должна быть многоуровневой: OS firewall, cloud firewall objects/SG/NSG, rate-limiting where possible и, для публичных хабов, нормальный upstream edge filtering у провайдера или облака. Для облака это означает минимум следующее: в AWS security groups открывают только нужный UDP и управленческий доступ; в Azure NSG фильтрует inbound/outbound на NIC/subnet; в GCP VPC firewall rules применяются на уровне сети/VM tags. То есть WireGuard-порт должен существовать не “в вакууме”, а внутри общей модели security policy cloud environment. Мониторинг и логирование На хосте базовые источники истины — это wg show , wg showconf , wg show all dump , ip route , ip rule , ss -ulpn , journalctl -u wg-quick@<iface> , tcpdump , а на Linux при необходимости — dynamic debug kernel module в dmesg . wg(8) прямо перечисляет runtime- информацию, включая endpoints , allowed-ips , latest-handshakes , transfer-rx/tx и persistent-keepalive , а quickstart и manpage дают способ включить debug output. Это уровни мониторинга “снизу вверх”: сначала tunnel state, потом kernel routing, потом packet visibility. В облаках поверх этого нужны flow logs. В AWS это VPC Flow Logs, которые умеют писать IP traffic metadata для VPC/subnet/ENI в CloudWatch Logs, S3 или Firehose. В GCP полезны одновременно VPC firewall logs и, где нужно, Connectivity/route visibility. В Azure в 2026 году важно учитывать, что NSG Flow Logs идут к retirement, а рекомендованный актуальный механизм — Virtual Network Flow Logs в Network Watcher. Если вы строите observability на Azure сейчас, имеет смысл уже не закладываться на NSG flow logs как на основное решение.
Отказоустойчивость и масштабирование
Самая частая ошибка при проектировании HA для WireGuard — ожидание, что его можно балансировать так же, как stateless UDP-сервис. На практике у WireGuard есть состояние peer’ов, runtime-learned endpoint, mapping public key ↔ AllowedIPs и kernel session state. Из wg(8) видно, что у peer’а один Endpoint , а не список endpoint’ов, поэтому high availability обычно строят не так, чтобы “один peer magically ходил в два backend-а”, а так, чтобы было два независимых peer/интерфейса/туннеля, а выбор активного пути делала маршрутизация. Это центральный architectural principle для production site-to-site на WireGuard. Для маленькой схемы достаточно active-standby: два cloud hubs, два туннеля из офиса, приоритетные статические маршруты или FRR static multipath/blackhole fallback. FRR documentation описывает multiple nexthop static route и multipath behavior, так что даже без динамического протокола можно сделать предсказуемый failover. Для схем побольше лучше сразу идти в BGP+BFD: тогда route withdrawal и reconvergence происходят автоматически, без ручной смены primary peer. Когда нужен публичный highly-available ingress в облаке, load balancer’ы могут быть полезны, но с оговорками. AWS NLB работает на L4, умеет UDP и preserves source IP; Azure Load Balancer сохраняет original source IP, но по умолчанию распределяет потоки по 5-tuple hash, причем новый session с другим source port может пойти на другой backend; GCP external passthrough NLB передает UDP packets “как есть”, а ILB/target instances могут использоваться в appliance-like next hop patterns. Сетевой смысл такой: как front-door это полезно, но для WireGuard active/active за LB operationally хрупко, особенно если backend’ы не синхронизируют full peer state и маршруты. Я бы использовал LB лишь там, где это реально закрывает edge resiliency, а сам failover peer’ов все равно делал бы multi-tunnel routing’ом. Статический публичный IP у хаба тоже остается важным элементом HA. В AWS Elastic IP можно быстро remap’ить между инстансами; в Azure public IP остается закреплен за resource до отвязки/ удаления; в GCP статический external IP резервируется и назначается instance’у. Для большинства enterprise-design’ов это проще и надежнее, чем пытаться заставить офисный NAT’d peer динамически догадаться, куда переподключаться после cloud-side failover. Обычно делают либо floating/static public IP, либо DNS name с контролируемым TTL и резервным endpoint’ом. С точки зрения масштаба подход обычно такой: • до 5 площадок — statics, один hub, минимум moving parts; • 5–20 площадок — hybrid, FRR/BGP, BFD, отдельные inter-site tunnels; • 20+ площадок — чаще уже стоит смотреть не только на “голый WireGuard”, но и на более полноценную control plane-надстройку или managed overlay, если команда эксплуатации небольшая.

Автоматизация и примеры конфигураций
Ниже примеры конфигов сознательно сделаны для Linux gateways, потому что именно такой baseline лучше всего переносится между bare metal, VM в AWS/Azure/GCP и dedicated servers. Если вы используете wg-quick , имейте в виду: это, по словам upstream, “simple script for simple needs”; для очень сложных сетевых стеков можно уйти на wg + ip , NetworkManager, systemd- networkd или собственную оркестрацию. Но как reference-format wg0.conf он по-прежнему удобен. Сценарий офис → hub в облаке Этот сценарий — базовый для офиса за NAT/динамическим IP. Облачный хаб имеет статический public IPv4, офисный gateway инициирует туннель, а на хабе Endpoint для офиса можно не задавать: он будет learned dynamically после первого корректного пакета. PersistentKeepalive стоит на офисной стороне. Для примера возьмем: • • • • • Office LAN: 172.16.10.0/24 Cloud VPC subnet behind hub: 10.10.0.0/16 Overlay: 10.200.0.0/24 Hub overlay IP: 10.200.0.1/24 Office overlay IP: 10.200.0.10/24 Cloud hub: /etc/wireguard/wg-office1.conf
[Interface]
Address = 10.200.0.1/24
ListenPort = 51820
PrivateKey = HUB_PRIVATE_KEY
# Для явного управления route tables можно использовать Table = off
# и настраивать маршруты / rules отдельно.
PostUp = sysctl -w net.ipv4.ip_forward=1
PostUp = sysctl -w net.ipv6.conf.all.forwarding=1
PostUp = nft -f /etc/nftables.d/wireguard-site-to-site.nft
PostDown = nft delete table inet wg-s2s
[Peer]
# Office gateway
PublicKey = OFFICE_PUBLIC_KEY
PresharedKey = OFFICE_HUB_PSK
AllowedIPs = 10.200.0.10/32, 172.16.10.0/24Office gateway: /etc/wireguard/wg0.conf
[Interface]
Address = 10.200.0.10/24
PrivateKey = OFFICE_PRIVATE_KEYDNS = 10.10.0.53
PostUp = sysctl -w net.ipv4.ip_forward=1
PostUp = sysctl -w net.ipv6.conf.all.forwarding=1
PostUp = nft -f /etc/nftables.d/wireguard-office.nft
PostDown = nft delete table inet wg-office
[Peer]
PublicKey = HUB_PUBLIC_KEY
PresharedKey = OFFICE_HUB_PSK
Endpoint = hub-vpn.example.net:51820
AllowedIPs = 10.10.0.0/16, 10.200.0.1/32
PersistentKeepalive = 25В этом примере офис инициирует туннель на FQDN хаба. Это нормальный паттерн, потому что Endpoint в WireGuard может быть hostname, а resolver retries контролируются переменной WG_ENDPOINT_RESOLUTION_RETRIES . На хабе AllowedIPs включают и overlay-/32, и офисную LAN-подсеть; это нужно и для security semantics incoming source filtering, и для routing decision на outgoing traffic. nftables на cloud hub: /etc/nftables.d/wireguard-site-to-site.nft table inet wg-s2s { chain input { type filter hook input priority 0; policy drop; iif "lo" accept ct state established,related accept udp dport 51820 accept tcp dport 22 ip saddr { 198.51.100.10/32 } accept
ip protocol icmp acceptip6 nexthdr icmpv6 accept } chain forward { type filter hook forward priority 0; policy drop; ct state established,related accept iifname "wg-office1" oifname "eth0" ip saddr 172.16.10.0/24 ip daddr 10.10.0.0/16 accept iifname "eth0" oifname "wg-office1" ip saddr 10.10.0.0/16 ip daddr 172.16.10.0/24 accept } }
iptables-legacy эквивалент
iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -i lo -j ACCEPT
iptables -A INPUT -p udp --dport 51820 -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -s 198.51.100.10/32 -j ACCEPT
iptables -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -i wg-office1 -o eth0 -s 172.16.10.0/24 -d 10.10.0.0/16 -j ACCEPT
iptables -A FORWARD -i eth0 -o wg-office1 -s 10.10.0.0/16 -d 172.16.10.0/24 -j ACCEPT systemd Обычно пакет уже ставит wg-quick@.service , который upstream публикует как стандартный unit с ExecStart=/usr/bin/wg-quick up %i , ExecStop=/usr/bin/wg-quick down %i , ExecReload=/usr/bin/wg syncconf ... и WG_ENDPOINT_RESOLUTION_RETRIES=infinity . На практике для запуска хватает: systemctl enable --now wg-quick@wg0 или wg-quick@wg- office1 . Cloud routing/security requirements Для этого сценария WireGuard-конфига недостаточно: хаб должен работать как router appliance внутри cloud network. Облако Что обязательно сделать Минимальный пример правила Отключить source/destination checks; в route table AWS VPC/subnet добавить маршрут 172.16.10.0/24 -> ENI/instance hub ; открыть UDP 51820 в SG SG ingress: UDP/51820 from 0.0.0.0/0 ; SSH только с admin CIDR Облако Что обязательно сделать Минимальный пример правила Azure GCP Включить IP forwarding; настроить UDR 172.16.10.0/24 -> Virtual appliance <hub private IP> ; убедиться, что форвардинг включен и в ОС NSG inbound: UDP 51820 allow; Mgmt only from admin CIDR Включить can-ip-forward ; создать custom static route 172.16.10.0/24 -> next-hop instance hub ; разрешить UDP 51820 в VPC firewall ingress allow udp:51820 target-tags= wireguard-hub Эти требования следуют из официальных cloud-документов о NAT/router instances, UDR/IP forwarding и next-hop instances. Без них overlay поднимется, но inter-subnet forwarding не заработает. Сценарий облако → dedicated server с BGP через FRR Для cloud↔dedicated я рекомендую уже не статику, а BGP, особенно если dedicated — это gateway в отдельный rack/VRF/DC. Возьмем point-to-point overlay 10.201.0.0/31 и отдельный интерфейс
wg-cloud-dc1 .Cloud side: /etc/wireguard/wg-cloud-dc1.conf
[Interface]
Address = 10.201.0.0/31
ListenPort = 51821
PrivateKey = CLOUD_PRIVATE_KEYTable = off
PostUp = ip link set dev %i mtu 1420 || true
PostUp = ip route add 10.201.0.1/32 dev %i
PostDown = ip route del 10.201.0.1/32 dev %i
[Peer]
PublicKey = DC1_PUBLIC_KEY
PresharedKey = CLOUD_DC1_PSK
Endpoint = dc1-edge.example.net:51821
AllowedIPs = 10.201.0.1/32
PersistentKeepalive = 25Dedicated side: /etc/wireguard/wg-dc1-cloud.conf
[Interface]
Address = 10.201.0.1/31
ListenPort = 51821
PrivateKey = DC1_PRIVATE_KEYTable = off
PostUp = ip route add 10.201.0.0/32 dev %i
PostDown = ip route del 10.201.0.0/32 dev %i
[Peer]
PublicKey = CLOUD_PUBLIC_KEY
PresharedKey = CLOUD_DC1_PSK
Endpoint = cloud-hub.example.net:51821
AllowedIPs = 10.201.0.0/32
PersistentKeepalive = 25Здесь Table = off нужен для того, чтобы WireGuard не “подменял” вашу routing policy своими auto routes. Это типичный production-паттерн при использовании FRR/BGP поверх туннеля: transport поднимается WireGuard’ом, а маршруты решает FRR. Возможность полностью отключить route creation у wg-quick документирована upstream. FRR на cloud side: /etc/frr/frr.conf frr version 10 frr defaults traditional hostname cloud-hub service integrated-vtysh-config
router bgp 65010bgp router-id 10.201.0.0 no bgp ebgp-requires-policy neighbor 10.201.0.1 remote-as 65101 neighbor 10.201.0.1 description dc1-over-wireguard ! address-family ipv4 unicast network 10.10.0.0/16 neighbor 10.201.0.1 activate neighbor 10.201.0.1 soft-reconfiguration inbound exit-address-family bfd profile fast transmit-interval 300 receive-interval 300 detect-multiplier 3 !
peer 10.201.0.1 profile fastFRR на dedicated side frr version 10 frr defaults traditional hostname dc1-edge service integrated-vtysh-config
router bgp 65101bgp router-id 10.201.0.1 no bgp ebgp-requires-policy neighbor 10.201.0.0 remote-as 65010 ! address-family ipv4 unicast network 10.50.0.0/24 neighbor 10.201.0.0 activate neighbor 10.201.0.0 soft-reconfiguration inbound exit-address-family bfd profile fast transmit-interval 300 receive-interval 300 detect-multiplier 3 !
peer 10.201.0.0 profile fastЭто не единственный корректный FRR-вариант, но operationally он очень хорош: WireGuard занимается только point-to-point transport, а BGP — обменом prefixes. Если позже появится резервный cloud hub или второй dedicated edge, вы добавите еще один интерфейс и еще одно соседство, а не будете переписывать всю схему. FRR documentation покрывает interface-based peering, route-maps, soft-reconfiguration, BFD и policy tools именно под такие сценарии. Сценарий full-mesh между дата-центрами Для full-mesh между тремя ЦОД я бы делал по интерфейсу на соседний ЦОД. Ниже пример только для DC1; на DC2/DC3 конфиг зеркалится. DC1: /etc/wireguard/wg-dc1-dc2.conf
[Interface]
Address = 10.210.12.0/31
ListenPort = 51830
PrivateKey = DC1_DC2_PRIVATETable = off
[Peer]
PublicKey = DC2_DC1_PUBLIC
PresharedKey = DC1_DC2_PSK
Endpoint = dc2-edge.example.net:51830
AllowedIPs = 10.210.12.1/32
PersistentKeepalive = 25DC1: /etc/wireguard/wg-dc1-dc3.conf
[Interface]
Address = 10.210.13.0/31
ListenPort = 51831
PrivateKey = DC1_DC3_PRIVATETable = off
[Peer]
PublicKey = DC3_DC1_PUBLIC
PresharedKey = DC1_DC3_PSK
Endpoint = dc3-edge.example.net:51831
AllowedIPs = 10.210.13.1/32
PersistentKeepalive = 25DC1: FRR frr version 10 frr defaults traditional hostname dc1
router bgp 65101bgp router-id 10.210.12.0 no bgp ebgp-requires-policy neighbor 10.210.12.1 remote-as 65102 neighbor 10.210.13.1 remote-as 65103 address-family ipv4 unicast network 10.51.0.0/24 neighbor 10.210.12.1 activate neighbor 10.210.13.1 activate exit-address-family bfd profile fast transmit-interval 300 receive-interval 300 detect-multiplier 3
peer 10.210.12.1 profile fast
peer 10.210.13.1 profile fastЕсли таких сайтов станет больше трех-шести, full-mesh быстро упрется в рост количества peer’ов и ключей. Тогда topology лучше переводить в hybrid с route reflectors или с cloud-hub/core fabric, а не плодить линию NxN дальше. Это уже не техническое ограничение WireGuard как пакетоносителя, а operational cost. Шаблон Ansible playbook Ansible подходит здесь почти идеально: apt для пакетов, template для wg0.conf / frr.conf , service для systemd. Это все официально поддерживаемые core-модули. --- - name: Deploy WireGuard and FRR gateway hosts: wg_gateways become: true vars: wg_iface: wg0 tasks: - name: Install packages ansible.builtin.apt: name: - wireguard - wireguard-tools - frr - nftables state: present update_cache: true - name: Enable IPv4 forwarding ansible.builtin.copy: dest: /etc/sysctl.d/99-wireguard.conf content: |
net.ipv4.ip_forward=1
net.ipv6.conf.all.forwarding=1mode: "0644" - name: Apply sysctl ansible.builtin.command: sysctl --system changed_when: true - name: Render WireGuard config ansible.builtin.template: src: templates/wg0.conf.j2 dest: "/etc/wireguard/{{ wg_iface }}.conf" owner: root group: root mode: "0600" - name: Render nftables config ansible.builtin.template: src: templates/wg-nftables.nft.j2 dest: /etc/nftables.d/wg-site.nft owner: root group: root mode: "0644" - name: Render FRR config ansible.builtin.template: src: templates/frr.conf.j2 dest: /etc/frr/frr.conf owner: frr group: frr mode: "0640" notify: restart frr - name: Enable nftables ansible.builtin.service: name: nftables enabled: true state: started - name: Enable WireGuard ansible.builtin.service: name: "wg-quick@{{ wg_iface }}" enabled: true state: started handlers: - name: restart frr ansible.builtin.service: name: frr state: restarted Шаблон Terraform module Terraform здесь полезен не для генерации самих ключей, а для облачной обвязки: VM, static public IP, SG/NSG/firewall, route table entries, tags, metadata/user-data. HashiCorp прямо определяет module как reusable collection of resources managed together — это ровно ваш случай.
# modules/wireguard-hub/variables.tfvariable "name" {} variable "region" {} variable "public_udp_port" { type = number default = 51820 } variable "admin_cidrs" { type = list(string) } variable "office_prefixes" { type = list(string) } variable "user_data" { type = string } AWS-ориентированный пример main.tf resource "aws_security_group" "wg_hub" { name = "${var.name}-wg-hub" description = "WireGuard hub" ingress { from_port = var.public_udp_port to_port = var.public_udp_port
protocol= "udp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port to_port = 22 = 22
protocol= "tcp" cidr_blocks = var.admin_cidrs } egress { from_port to_port = 0 = 0
protocol= "-1" cidr_blocks = ["0.0.0.0/0"] } } resource "aws_eip" "wg_hub" { domain = "vpc" }
# instance / eni / route resources deliberately omitted here
# attach EIP, disable source_dest_check, add routes for office prefixesЭто не complete module “под apply без правок”, а каркас: в AWS вы добавите instance, ENI, route table entries и source_dest_check = false ; в Azure — azurerm_public_ip , NSG и UDR; в GCP — static external IP, firewall rule, can_ip_forward = true и custom routes. Но именно так и стоит проектировать Terraform здесь: reusable cross-cloud patterns + provider-specific children. Cloud-init шаблон В cloud-init теперь есть даже официальный пример WireGuard tunnel configuration с readiness probes. Это удобно для hub VM в облаке, особенно когда instance должна поднять tunnel до post- boot automation.
#cloud-configpackage_update: true packages: - wireguard - wireguard-tools - nftables write_files: - path: /etc/wireguard/wg0.conf permissions: "0600" content: |
[Interface]
Address = 10.200.0.1/24
ListenPort = 51820
PrivateKey = HUB_PRIVATE_KEY
[Peer]
PublicKey = OFFICE_PUBLIC_KEY
PresharedKey = OFFICE_HUB_PSK
AllowedIPs = 10.200.0.10/32, 172.16.10.0/24runcmd: - sysctl -w net.ipv4.ip_forward=1 - sysctl -w net.ipv6.conf.all.forwarding=1 - systemctl enable --now wg-quick@wg0 - systemctl enable --now nftables Тестирование, troubleshooting checklist, ограничения и альтернативы Команды диагностики Эти команды закрывают почти весь day-2 ops цикл для WireGuard site-to-site. Их смысл опирается на official wg(8) , wg-quick(8) , FRR docs и cloud flow logging tooling. Что проверить Команда Что вы хотите увидеть Состояние peer’ов
WGМашиночитаемый dump
wg showЕсть peer, endpoint, свежий handshake, растущие tx/rx counters
wg show all dumpТабличный вывод для автоматических health-checks Конфиг интерфейса
wg showconf wg0Совпадает с ожидаемыми keys/ AllowedIPs Состояние интерфейса Маршруты
ip addr show wg0Адрес интерфейса поднят
ip route / ip -6route Есть нужные prefixes и next-hop logic Policy rules
ip ruleRoute policy корректна, если используется Table= /PBR UDP socket
ss -ulpn | grep 51820Процесс слушает нужный port Firewall counters Проверка path MTU
nft list ruleset /
iptables -nvL
ping -M do -s ...<overlay-ip> Пакеты попадают в правильные правила Нет неожиданных fragmentation failures Packet visibility
tcpdump -ni any udpport 51820 Видны handshakes/transport packets Что проверить Команда Что вы хотите увидеть BGP summary BFD vtysh -c "show bgp summary" Соседство Established vtysh -c "show bfd
Peer Up, таймеры соответствуютpeers" ожиданию Troubleshooting checklist Ниже checklist дан в том порядке, в котором реально стоит дебажить: от transport к routing, а не наоборот. Это экономит часы. Команды и expected behavior опираются на official wg / wg-quick , FRR show-команды и cloud observability docs. Шаг Проверка Команда Если не так Transport Хост слушает UDP порт
ss -ulpnHandshake Есть latest handshake
wg show
Peer за NATNAT поддерживает
wg show + tcpdumpmapping
WG interfaceUP и с адресом Prefix есть в RIB
InterfaceRoutes
ip addr show wg0
ip route , ip ruleПроверить service/unit и firewall input Проверить public key, PSK, endpoint, DNS- resolve, внешний firewall Добавить/проверить PersistentKeepalive = 25 на NATed стороне Проверить wg- quick@wg0 и syntax conf Исправить AllowedIPs , Table , cloud route tables Forwarding Включен IP forwarding
sysctl net.ipv4.ip_forward
net.ipv6.conf.all.forwardingВключить sysctl OS firewall FORWARD не режет трафик
nft list ruleset / iptables-nvL Разрешить inter-zone forwarding Cloud firewall
Routerappliance mode SG/NSG/VPC firewall позволяют cloud logs / console UDP и inter- subnet flows AWS/Azure/ GCP разрешают форвардинг console / CLI Исправить rules, tags, NSG bindings AWS: disable source/dest check; Azure: IP forwarding + UDR; GCP: can-ip-forward + routes Шаг Проверка Команда Если не так BGP Session Established vtysh -c "show bgp summary" source, policy, tcp/179 Проверить loopback/ BFD
Peer Upvtysh -c "show bfd peers" Performance Нет MTU/CPU bottleneck iperf3 , ping , top , mpstat Checklist развертывания over tunnel Проверить timers и reachability по overlay Снизить MTU, проверить offload/CPU saturation Это короткий пред-прод checklist. Он особенно полезен, когда you automate deployment and want a deterministic acceptance gate. Этап Что должно быть сделано Примечание Адресный план Overlay ranges, site LAN/VPC/DC ranges, no overlap Зафиксировать в Git/CMDB Ключи Private/public keys, optional PSK, rotation Хранить как secret, не в CLI policy history Cloud edge Static public IP / DNS name для hub Упростит failover и NATed spokes
Routerappliance AWS/Azure/GCP forwarding settings Часто забывают на пилоте Firewall OS + cloud rules на UDP/51820 и mgmt ICMP/ICMPv6 не блокировать без причины Статика или FRR/BGP выбраны Table = off при external осознанно route control Routing DNS Logging Решено, как будет работать межсайтовое name resolution
wg show , journald, cloud flow logsвключены HA Проверен failover primary hub/peer Split DNS/forwarders, если нужно Azure: уже лучше VNet Flow Logs Не “на бумаге”, а реальным отключением Performance Есть baseline iperf3 + latency under load Сохранять regression baseline Timeline развертывания gantt title Базовый rollout site-to-site на WireGuard dateFormat YYYY-MM-DD section Design Адресный план и ACL :a1, 2026-05-08, 2d Выбор топологии и HA :a2, after a1, 2d section Build Cloud hub и public IP :b1, after a2, 1d WireGuard transport :b2, after b1, 1d Route tables / UDR / can-ip-forward :b3, after b2, 1d section Control plane Static routes или FRR/BGP :c1, after b3, 2d BFD и failover policy :c2, after c1, 1d section Validation Functional tests :d1, after c2, 1d MTU / throughput / latency :d2, after d1, 1d Failover drills :d3, after d2, 1d section Operations Monitoring / flow logs :e1, after d3, 1d Key rotation runbook :e2, after e1, 1d Ограничения WireGuard Для site-to-site важно не переоценивать WireGuard. Официальный список limitations прямо говорит: протокол не ориентирован на обфускацию, не поддерживает TCP mode, имеет trade- offs вокруг roaming, identity hiding при компрометации responder private key и не является post- quantum secure по умолчанию без PSK/внешнего слоя. Отдельно upstream упоминает и проблемы с routing loops detection. Это не делает WireGuard плохим — это просто означает, что он идеален как простая, быстрая, криптографически сильная data plane, но не как полная сеть “из коробки”. Альтернативы Сравнение ниже полезно не в духе “что лучше вообще”, а в духе “что лучше для этого класса задач”. Оно основано на WireGuard official docs, IPsec RFC 4301/7296 и официальных Tailscale docs о WireGuard-based overlay и subnet/site-to-site patterns. Технология Сильные стороны Слабые стороны Когда выбирать WireGuard Простая конфигурация, современная криптография, высокая производительность, малый codebase Нет встроенной Linux-heavy site-to- control plane/PKI/ site, self-managed discovery/relay VPN fabric Зрелый стандарт, сильная IPsec/IKEv2 интероперабельность, hardware/ vendor ecosystem WireGuard + control plane, SSO, Tailscale NAT traversal, subnet routers, ACL, логирование Сложнее конфиг, больше operational overhead Vendor/service dependency или свой control-plane вариант Enterprise interop, hardware firewalls, vendor ecosystems Когда важнее скорость внедрения и удобство ops, чем “голый” self-managed transport IPsec по RFC 4301/7296 остается лучшим выбором там, где вам нужна максимальная совместимость с enterprise/firewall-vendor экосистемой, строгая стандартизация и IKE/SA control plane “как часть стека”. Tailscale интересен там, где вы хотите оставить криптографическую data plane WireGuard, но отдать наружу пользовательскую идентичность, NAT traversal, subnet router orchestration и policy plane.
Тестирование, troubleshooting checklist, ограничения и альтернативы
Открытые вопросы и ограничения этого отчета
В вашем запросе не были заданы конкретные ОС, firewall platform, ASN/prefix plan, required throughput/latency SLO и точное количество площадок, поэтому примеры даны как production- oriented Linux reference design, а не как готовая drop-in конфигурация под один конкретный инвентарь. Там, где выбор принципиально зависит от этих параметров — например, full-mesh vs hybrid, static vs BGP, fixed MTU vs auto, active-standby vs multi-active — я дал не одну “истину”, а несколько рабочих вариантов. Русскоязычные полезные материалы по теме существуют, но я использовал их только как вторичный слой; основные выводы в отчете привязаны к официальной документации WireGuard, RFC, FRR и cloud-provider guides. Из русскоязычного слоя особенно полезны практические статьи Timeweb по WireGuard и переводы/материалы по RFC/BGP, но архитектурные решения я бы все равно закреплял по первичным источникам.




