




















Оглавление
- Что вообще хранится в хранилище эмбеддингов
- Вариант первый: PostgreSQL с pgvector
- Вариант второй: отдельная vector DB
- Главный компромисс: простота против специализации
- Когда лучше выбрать PostgreSQL для эмбеддингов
- Когда лучше выбрать отдельную vector DB
- Сравнение: PostgreSQL или vector DB
- Вопросы, которые стоит задать до выбора
- Частая архитектура: начать с PostgreSQL, затем вынести поиск
- Практический сценарий для RAG
- Ошибки, которые дорого обходятся
- Что выбрать для нового AI-проекта
- Рекомендация по инфраструктуре
- Итог: нет лучшей базы, есть подходящая архитектура
Эмбеддинги быстро перестали быть экспериментом из лаборатории машинного обучения. Сегодня они лежат в основе AI-поиска, чат-ботов, RAG-систем, рекомендаций, антифрода, классификации документов и внутренних ассистентов. Но как только проект выходит за пределы демо, появляется практичный вопрос: где хранить эти векторы?
На первый взгляд ответ очевиден: нужна векторная база данных. Но затем в комнате появляется PostgreSQL с расширением pgvector и спокойно напоминает, что у вас уже есть транзакции, SQL, бэкапы, роли, репликация и команда, которая умеет это сопровождать.
Выбор между отдельной vector DB и PostgreSQL для эмбеддингов не сводится к вопросу «что быстрее». Это выбор архитектуры, операционной сложности, бюджета и будущей гибкости. Хорошая новость: почти всегда можно принять разумное решение без гадания на кофейной гуще.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Что вообще хранится в хранилище эмбеддингов
Эмбеддинг - это числовое представление текста, изображения, товара, пользователя или другого объекта. Модель превращает объект в массив чисел, а система потом ищет не точное совпадение, а смысловую близость.
Например, запрос «как восстановить доступ к серверу» может быть близок к документу «сброс SSH-ключей после потери доступа», даже если слова не совпадают один в один. Для обычного поиска это неочевидная связь. Для семантического поиска - вполне рабочий сценарий.
Хранилище эмбеддингов обычно держит три типа данных:
1. сам вектор;
2. идентификатор объекта;
3. метаданные: язык, категория, владелец, дата, права доступа, версия модели, источник документа.
Именно третий пункт часто недооценивают. На тесте кажется, что достаточно сохранить массив чисел и искать ближайшие векторы. В продакшене почти всегда нужен фильтр: только документы конкретного клиента, только свежие версии, только публичные материалы, только товары в наличии, только статьи на русском языке.
Поэтому вопрос звучит не просто «где хранить векторы». Точнее так: где хранить векторы, метаданные, правила доступа и историю изменений так, чтобы это не превратилось в отдельный зоопарк?
Вариант первый: PostgreSQL с pgvector
PostgreSQL давно воспринимается не только как классическая реляционная база. С расширением pgvector он может хранить векторные поля и выполнять поиск ближайших соседей прямо внутри привычной SQL-модели. В официальной документации pgvector базовый сценарий выглядит просто: включить расширение, создать колонку типа `vector`, записать эмбеддинги и искать ближайшие записи через сортировку по расстоянию.
Это особенно удобно, если основные данные уже живут в PostgreSQL. Представьте сервис документации: таблица `documents`, таблица `users`, таблица `permissions`, таблица `document_chunks`, а рядом поле `embedding`. Не нужно синхронизировать два разных мира. Можно сделать JOIN, проверить права доступа, отфильтровать по tenant_id и вернуть результат.
Мини-пример из жизни: команда делает внутренний AI-поиск по базе знаний. Документы, пользователи и права уже лежат в PostgreSQL. Если вынести эмбеддинги в отдельную vector DB, придется поддерживать синхронизацию: документ изменился в Postgres, чанк пересчитался, вектор обновился в другой системе, права доступа тоже надо не забыть. Для небольшой или средней нагрузки pgvector часто снимает эту головную боль.
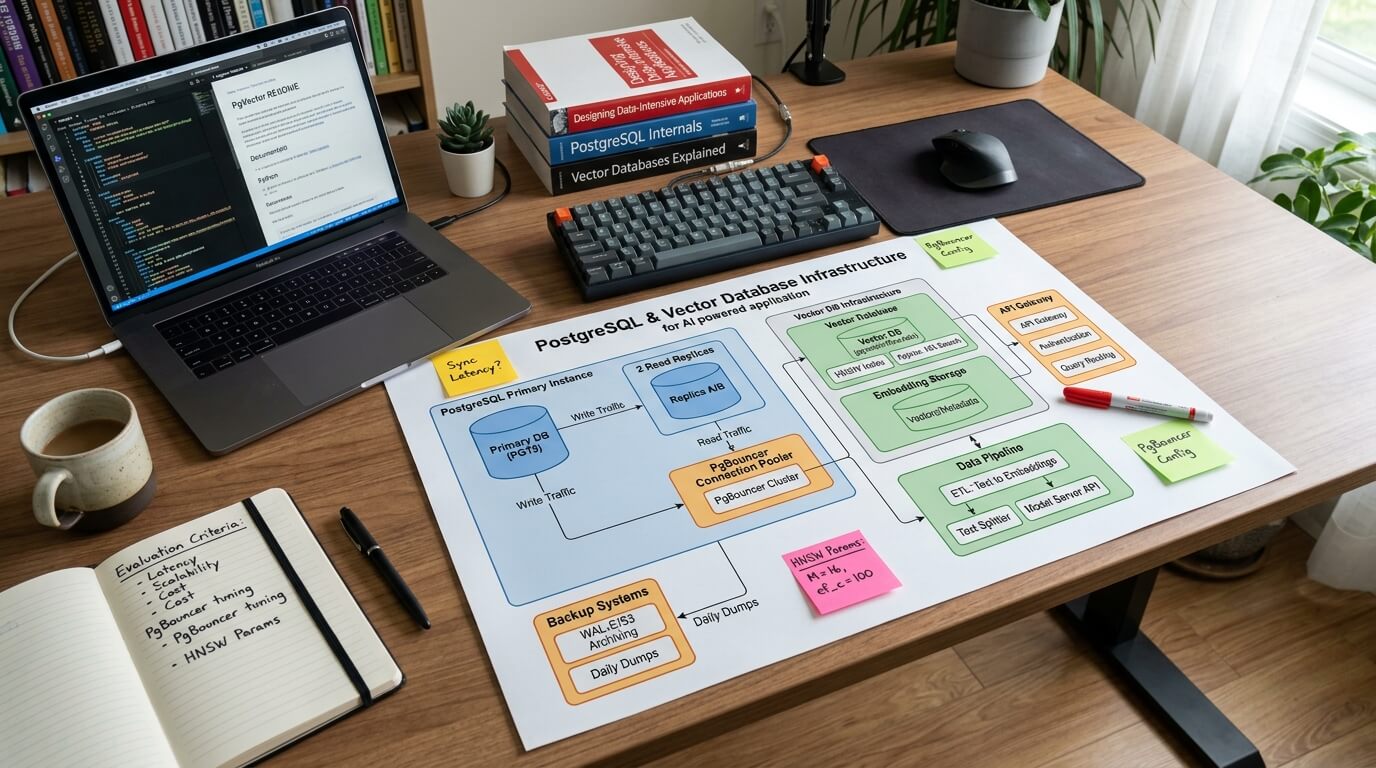
Почему PostgreSQL выглядит так привлекательно
Главный плюс PostgreSQL - не в том, что он «умеет векторы». Главный плюс в том, что он уже умеет быть базой данных.
У вас есть транзакции. Есть привычные бэкапы. Есть роли и доступы. Есть миграции схемы. Есть мониторинг. Есть репликация. Есть SQL, который понимает большая часть команды. Для бизнеса это не мелочи, а страховочная сетка.
Если эмбеддинги являются частью основного продукта, а не отдельным поисковым движком, PostgreSQL дает очень естественную модель. Карточка товара, описание, цена, склад, embedding и статус публикации могут жить рядом. Когда товар удален или скрыт, его вектор не остается «призраком» в отдельном индексе.
Хорошая аналогия: PostgreSQL с pgvector - это не отдельный спортивный автомобиль для одной задачи, а надежный универсал. Он не всегда выиграет гонку на прямой, зато в него удобно загрузить всю инфраструктуру проекта.
Индексы: HNSW и IVFFlat без лишней магии
pgvector поддерживает приближенный поиск ближайших соседей через индексы HNSW и IVFFlat. В документации указано, что HNSW обычно дает более сильный баланс скорости и полноты выдачи, но требует больше памяти и дольше строится. IVFFlat, наоборот, быстрее строится и потребляет меньше памяти, но чаще уступает HNSW по соотношению speed/recall.
На практике это означает простую вещь: если корпус данных уже не крошечный, «просто положить вектор в колонку» недостаточно. Индексы надо выбирать, строить, тестировать и настраивать.
Например, для RAG-поиска по документации компании HNSW часто будет хорошей стартовой точкой. Пользователь задает вопрос, система должна быстро найти релевантные фрагменты и передать их в LLM. Лучше немного дольше построить индекс, чем каждый раз ждать медленный поиск.
IVFFlat может быть уместен там, где данные загружаются большими пачками, индекс регулярно пересобирается, а требования к памяти жестче. Например, ночная загрузка каталога товаров с последующим поиском в течение дня.

Сильная сторона PostgreSQL: данные и векторы в одном месте
Векторный поиск редко живет сам по себе. Обычно он отвечает на вопрос: «Найди похожее, но с учетом условий».
Похожее, но только для этого клиента.
Похожее, но только среди активных документов.
Похожее, но только в категории «инфраструктура».
Похожее, но только если пользователь имеет право это видеть.
В PostgreSQL такие условия естественно выражаются через SQL. Можно комбинировать обычные индексы, фильтры, JOIN и векторное расстояние. Документация pgvector отдельно показывает сценарии с `WHERE` и рекомендует использовать обычные индексы PostgreSQL для фильтрующих колонок, а в некоторых случаях - partial indexing или partitioning.
Это важный момент. Многие проблемы AI-поиска возникают не из-за слабой модели, а из-за грязной логики вокруг данных. Если пользователь видит не тот документ, это не «ошибка эмбеддинга». Это ошибка архитектуры доступа.
PostgreSQL помогает держать эту логику ближе к источнику истины.
Вариант второй: отдельная vector DB
Отдельная vector DB - это специализированная система, построенная вокруг векторного поиска. К таким решениям относятся, например, Qdrant, Weaviate, Pinecone, Milvus и другие платформы.
Их сильная сторона понятна: они проектировались именно под хранение векторов, быстрый ANN-поиск, масштабирование индексов, фильтрацию по метаданным, гибридный поиск, распределенную архитектуру и AI-нагрузки.
Если PostgreSQL с pgvector - универсал, то отдельная vector DB - это инструмент из специализированной мастерской. Он создан для конкретного класса задач и часто быстрее раскрывается на больших объемах.

Когда vector DB действительно к месту
Отдельная векторная база данных особенно полезна, когда векторов много, запросов много, задержки важны, а поиск становится отдельным продуктовым контуром.
Например, маркетплейс делает поиск по миллионам товаров. Пользователь вводит не точное название, а «легкий ноутбук для поездок с хорошей батареей». Система должна учитывать смысл, характеристики, фильтры, поведенческие сигналы и, возможно, гибридный поиск по ключевым словам. Здесь vector DB начинает выглядеть не как усложнение, а как нормальная инженерная инвестиция.
Еще один пример - SaaS-платформа с AI-ассистентом для тысяч компаний. У каждого клиента свои документы, свои права, свои обновления. Нагрузка растет, индексы становятся большими, команда хочет масштабировать поиск независимо от основной базы. В такой ситуации отдельный слой под векторный поиск помогает не превращать основной PostgreSQL в перегруженный комбайн.
Гибридный поиск как отдельный аргумент
Чистый семантический поиск хорош, но он не всегда достаточно точен. Иногда пользователь ищет конкретный артикул, ошибку, имя метода, номер тикета или юридический термин. В таких случаях классический лексический поиск может быть важнее «смысла».
Поэтому в продакшене часто используют hybrid search - комбинацию семантического и ключевого поиска. Pinecone в своей документации описывает подходы с dense и sparse vectors, включая вариант с одним индексом и вариант с отдельными индексами, которые затем объединяются на стороне приложения. Weaviate описывает hybrid search как объединение vector search и keyword search на базе BM25F с настраиваемыми весами и методом слияния результатов.
Почему это важно? Потому что пользовательский поиск редко бывает «чистым». Сегодня человек спрашивает: «как настроить резервное копирование». Завтра он вводит «ERR_SSL_PROTOCOL_ERROR». Послезавтра - точное имя функции из кода. Хорошая поисковая система должна уверенно работать во всех трех режимах.
Можно ли сделать гибридный поиск вокруг PostgreSQL? Да, можно. Но специализированные vector DB часто дают такие сценарии более готовыми и удобными, особенно если поиск - центральная часть продукта.
Отдельная vector DB лучше масштабируется как сервис
Когда векторный поиск становится самостоятельной нагрузкой, у него появляются свои требования:
• отдельное масштабирование чтения;
• быстрые массовые вставки;
• перестроение индексов;
• контроль recall и latency;
• квантование;
• шардинг;
• снапшоты;
• отдельный мониторинг;
• независимые релизы поискового слоя.
Qdrant, например, позиционируется как AI-native vector search engine и в документации отдельно выделяет управление векторами, payload, коллекциями, индексированием, quantization, multitenancy, hybrid queries и large-scale search.
В простом проекте это может выглядеть как лишний набор слов. В большом проекте это уже ежедневная эксплуатация.
Главный компромисс: простота против специализации
Выбор между PostgreSQL и отдельной vector DB похож на выбор между кухней дома и профессиональной кухней ресторана.
Если вы готовите для семьи, домашняя кухня удобнее. Все под рукой, не нужно арендовать отдельное помещение, покупать промышленные плиты и нанимать администратора. Если же вы обслуживаете сотни заказов в час, домашняя кухня быстро станет узким местом.
PostgreSQL хорош, когда векторный поиск тесно связан с основными данными и нагрузка остается управляемой.
Vector DB хороша, когда поиск становится отдельным высоконагруженным сервисом, который нужно масштабировать и настраивать независимо.
Самая частая ошибка - выбирать технологию не под текущую задачу, а под красивую архитектурную картинку. Команда слышит «AI», сразу ставит отдельную vector DB, затем месяцами решает синхронизацию, права доступа, дублирование метаданных и миграции. Или наоборот: упорно держит десятки миллионов векторов в PostgreSQL, хотя поиск уже давно живет собственной жизнью и мешает основной базе.
Нормальная архитектура не обязана быть модной. Она должна выдерживать вашу нагрузку, вашу команду и ваш бюджет.
Рост корпуса и типичный выбор
Упрощённая шкала: не замена benchmark, а ориентир для архитектурного разговора.
Реальные пороги зависят от размерности, фильтров, QPS и железа — измеряйте на своих данных.
Когда лучше выбрать PostgreSQL для эмбеддингов
PostgreSQL с pgvector часто будет разумным выбором, если проект только выходит в продакшен или находится на стадии уверенного MVP.
Особенно если:
• основные данные уже находятся в PostgreSQL;
• векторов пока не десятки и не сотни миллионов;
• команда хорошо знает SQL и PostgreSQL;
• нужны сложные фильтры по бизнес-данным;
• важны транзакции и согласованность;
• не хочется добавлять еще один сервис в инфраструктуру;
• RAG-система обслуживает ограниченный корпус документов;
• поиск не является самым тяжелым компонентом продукта.
Представим компанию, которая делает AI-помощника по внутренним регламентам. Есть 50 000 документов, они разбиты на чанки, каждый чанк имеет embedding, source_id, language, department_id, access_level и версию. Пользователь задает вопрос, система ищет релевантные чанки с учетом прав.
Для такой задачи PostgreSQL может быть не просто достаточным, а очень удобным. Все правила доступа рядом. Все изменения документов проходят через одну базу. Бэкап один. Миграции понятны. Команда не тратит время на синхронизацию двух хранилищ.
Тут pgvector работает как хороший встроенный инструмент. Не пытается быть отдельной вселенной, а аккуратно расширяет уже знакомую базу.
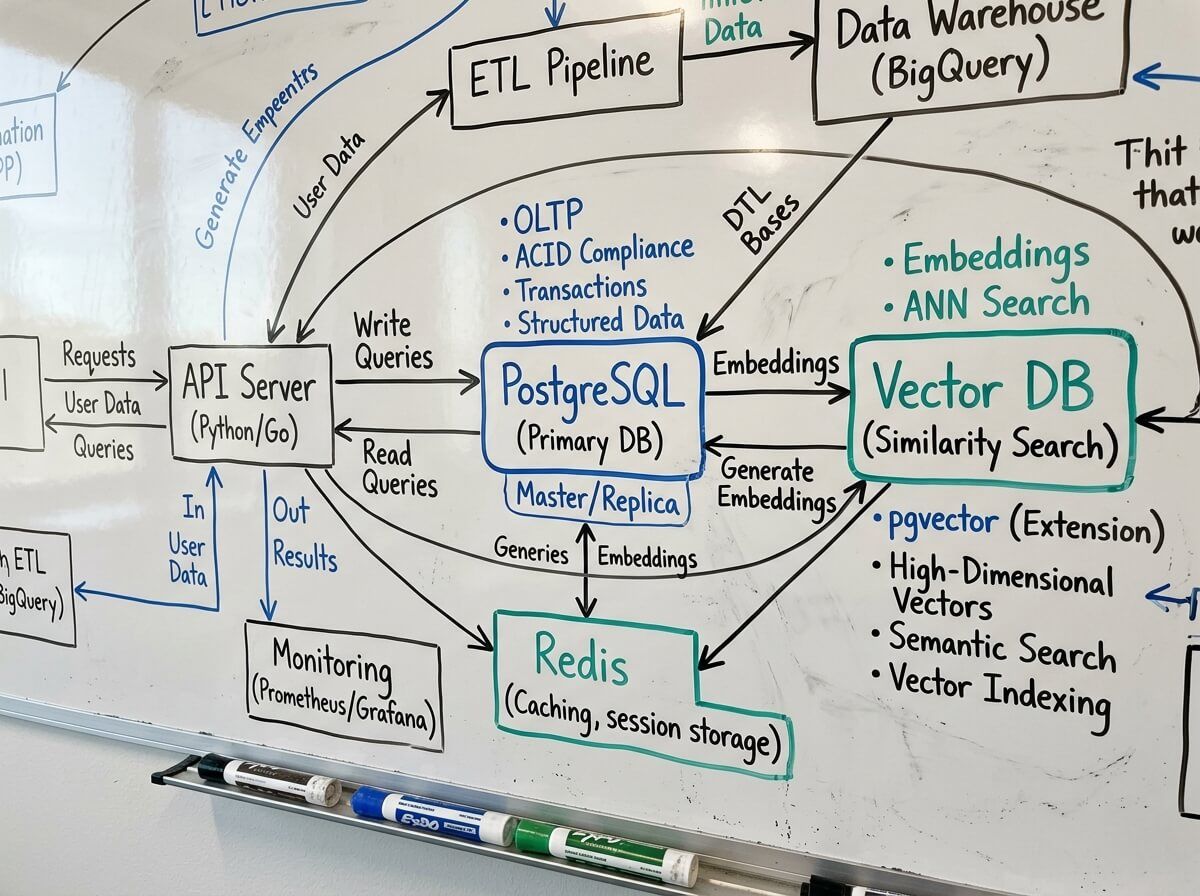
PostgreSQL особенно хорош для RAG на старте
RAG-пайплайн обычно состоит из нескольких шагов: загрузить документ, разбить на чанки, посчитать эмбеддинги, сохранить, найти похожие фрагменты, передать их в модель, вернуть ответ.
На раннем этапе главная задача - не выжать последние миллисекунды. Главная задача - сделать систему предсказуемой, проверяемой и безопасной.
PostgreSQL помогает быстро ответить на практичные вопросы:
• какой документ породил этот чанк;
• какой моделью был создан embedding;
• когда он был обновлен;
• кто имеет доступ к источнику;
• какие чанки надо пересчитать после изменения документа;
• какую версию индекса сейчас использует приложение.
Если эти ответы разбросаны между несколькими системами, отладка становится неприятной. Когда они лежат в одной базе, команда быстрее понимает, что происходит.
Где PostgreSQL может начать упираться в потолок
У PostgreSQL тоже есть границы. Он не становится бесконечно масштабируемой vector DB только потому, что установлен pgvector.
Проблемы обычно проявляются постепенно. Сначала запросы чуть медленнее. Потом индекс занимает все больше памяти. Потом массовая загрузка векторов мешает обычным операциям. Потом аналитика, поиск и продуктовые транзакции начинают конкурировать за ресурсы. В какой-то момент база данных, которая была «одним удобным центром», превращается в перегруженный перекресток.
Признаки, что пора внимательно смотреть в сторону отдельной vector DB:
• корпус растет до десятков миллионов векторов и дальше;
• поиск требует стабильно низкой задержки;
• векторные запросы начинают влиять на основную OLTP-нагрузку;
• нужно масштабировать поиск независимо от основной базы;
• требуется сложный hybrid search или reranking pipeline;
• команда часто перестраивает индексы;
• появляются разные embedding-модели и несколько поисковых представлений;
• один и тот же поиск обслуживает много продуктов или клиентов.
Это не значит, что PostgreSQL «плохой». Это значит, что роль изменилась. Молоток не становится плохим, когда вам нужен станок.
Когда лучше выбрать отдельную vector DB
Отдельная vector DB оправдана, когда векторный поиск - не вспомогательная функция, а часть ядра продукта.
Например:
• AI-поиск в большом каталоге;
• рекомендации по поведению пользователей;
• поиск по изображениям;
• enterprise RAG по миллионам документов;
• code search;
• персонализация контента;
• real-time matching;
• поиск похожих событий в логах;
• антифрод на основе похожих паттернов.
В таких системах хранилище эмбеддингов становится самостоятельной инфраструктурой. Его надо масштабировать, наблюдать, оптимизировать и обновлять без страха сломать основную транзакционную базу.
Еще один аргумент - организационный. Если над поиском работает отдельная команда, ей может быть удобнее владеть отдельным сервисом. Они настраивают индексы, меняют модели, тестируют качество выдачи, проводят A/B-тесты. Основная продуктовая база при этом живет своей жизнью.

Vector DB полезна, когда поиск надо развивать быстро
Семантический поиск редко остается в первой версии. Обычно все начинается с простого nearest neighbor search. Затем появляются фильтры. Потом hybrid search. Потом reranking. Потом отдельные индексы под разные языки. Потом разные модели для коротких и длинных запросов. Потом оценка качества на golden dataset.
Если продукт активно развивается в эту сторону, специализированная vector DB может ускорить эксперименты. Не потому, что PostgreSQL ничего не умеет, а потому что векторные базы часто предлагают больше готовых механизмов вокруг AI retrieval.
Условный пример: команда делает поиск по базе юридических документов. Пользователи часто вводят точные номера статей, но также задают длинные вопросы естественным языком. Здесь нужен гибридный поиск, контроль весов, возможно reranking и отдельные пайплайны обновления. Под такую задачу vector DB может лечь естественнее, чем попытка собрать все из SQL, полнотекстового поиска и кастомной логики.
Сравнение: PostgreSQL или vector DB
Ниже - практичное сравнение без фанатизма.
Главный вывод из таблицы простой: PostgreSQL выигрывает там, где важна близость к основным данным. Vector DB выигрывает там, где важна специализация поиска.
Вопросы, которые стоит задать до выбора
Перед тем как выбирать базу, полезно задать несколько неприятно конкретных вопросов. Они быстро охлаждают архитектурный энтузиазм и возвращают разговор к реальности.
Сколько векторов будет через год?
Не сегодня в демо. Не после первой загрузки. Именно через год нормального использования.
Если сейчас 100 000 чанков, а через год ожидается 800 000, PostgreSQL выглядит спокойно. Если сейчас 5 миллионов, а через год может быть 200 миллионов, лучше сразу проектировать отдельный поисковый слой или хотя бы оставить путь к миграции.
Как часто данные обновляются?
Одно дело - статичная база знаний, которая обновляется раз в неделю. Другое - поток событий, товаров, сообщений или пользовательских действий, где новые эмбеддинги появляются каждую минуту.
Чем интенсивнее запись и обновление, тем важнее понимать, как база строит и обслуживает индексы.
Насколько сложны фильтры?
Если фильтры простые: язык, категория, дата - с ними справятся оба подхода.
Если фильтры завязаны на сложную бизнес-логику, права доступа, роли, организации, статусы, подписки и внутренние связи, PostgreSQL начинает выглядеть гораздо привлекательнее. Вынести это в отдельную vector DB можно, но придется аккуратно дублировать метаданные и следить, чтобы они не расходились.
Что важнее: latency или простота?
Иногда дополнительные 30-50 миллисекунд не играют роли. Например, внутренний помощник отвечает за 3 секунды, потому что основное время уходит на LLM. В таком случае усложнять инфраструктуру ради микровыигрыша в поиске не всегда разумно.
А вот если семантический поиск стоит в пользовательском интерфейсе каталога и должен ощущаться мгновенным, задержки уже критичны. Там отдельная vector DB может дать больше пространства для оптимизации.
Кто будет это поддерживать?
Это самый недооцененный вопрос.
Выбор технологии - это не только benchmark. Это дежурства, обновления, алерты, бэкапы, восстановление, миграции, отладка, документация и обучение команды.
Если в команде сильная PostgreSQL-экспертиза, а vector DB никто не сопровождал, старт с pgvector может быть разумнее. Если же есть команда поиска или ML-platform, отдельная vector DB будет вполне естественным инструментом.
Частая архитектура: начать с PostgreSQL, затем вынести поиск
Для многих проектов лучший путь не бинарный, а эволюционный.
Сначала эмбеддинги хранятся в PostgreSQL. Команда быстро запускает RAG или семантический поиск, проверяет продуктовую гипотезу, собирает реальные запросы, понимает объемы и качество выдачи.
Затем, если нагрузка растет, векторный поиск выносится в отдельную vector DB. PostgreSQL остается источником истины для документов, пользователей, прав и бизнес-сущностей. Vector DB становится быстрым поисковым индексом.
Это похоже на классическую историю с поисковыми движками. Многие продукты начинают с поиска внутри основной базы, а потом выносят его в Elasticsearch или OpenSearch, когда появляется настоящая потребность. С векторами логика похожая.
Важно только заранее не загнать себя в угол.

Как оставить путь к миграции открытым
Даже если вы выбираете PostgreSQL, не стоит размазывать работу с эмбеддингами по всему коду. Лучше сразу сделать отдельный слой доступа:
• сервис или модуль `EmbeddingStore`;
• явные методы `upsert`, `delete`, `search`;
• хранение версии embedding-модели;
• отдельная таблица для чанков;
• нормальная схема метаданных;
• логика пересчета эмбеддингов;
• тестовый набор запросов для оценки качества.
Тогда при переезде на vector DB вы меняете реализацию хранилища, а не переписываете весь продукт.
Простой пример: сегодня `EmbeddingStore.search()` ходит в PostgreSQL. Через год он может ходить в Qdrant, Weaviate или Pinecone. Для остального приложения это остается тем же интерфейсом: запрос на входе, список найденных объектов на выходе.
Такой подход дает спокойствие. Вы не обязаны угадать будущее идеально. Достаточно не закрывать себе двери.
Практический сценарий для RAG
Допустим, вы строите RAG-систему для технической документации.
На старте у вас 10 000 документов. Каждый разбивается на чанки, получается 200 000-500 000 эмбеддингов. Пользователей немного, запросы идут десятками в минуту, права доступа важны, документы уже хранятся в PostgreSQL.
Здесь PostgreSQL с pgvector выглядит логично. Вы быстро запускаете систему, храните чанки рядом с документами, фильтруете по правам, делаете бэкапы привычным способом и не добавляете новый сервис.
Через год проект вырос. Документов уже миллионы, появились несколько команд, отдельный публичный поиск, разные embedding-модели, гибридный поиск, регулярный reranking и жесткие требования к latency.
На этом этапе можно вынести векторный индекс в отдельную vector DB. PostgreSQL остается главным источником данных, а vector DB отвечает за быстрый retrieval.
Такой путь обычно здоровее, чем попытка сразу построить «идеальную AI-инфраструктуру» без реальных данных. Архитектура должна расти вместе с продуктом, а не опережать его на три квартала.
Ошибки, которые дорого обходятся
Ошибка 1. Хранить только вектор и забыть про метаданные
Вектор без метаданных - как книга без обложки, автора и полки в библиотеке. Может быть полезной, но найти и правильно использовать ее трудно.
Всегда храните source_id, chunk_id, model_version, timestamps, язык, tenant_id, статус и признаки доступа. Минимальный набор зависит от продукта, но пустым он почти никогда не бывает.
Ошибка 2. Не версионировать embedding-модель
Сегодня вы используете одну модель. Через полгода появляется новая: дешевле, быстрее, качественнее или лучше работает на вашем языке.
Если не хранить версию модели, будет трудно понять, какие векторы надо пересчитать и можно ли сравнивать старые эмбеддинги с новыми. Векторное пространство у разных моделей может отличаться. Смешивать их без контроля - все равно что мерить температуру частью в Цельсиях, частью в Фаренгейтах.
Ошибка 3. Выбирать базу без реального benchmark
Чужие результаты производительности полезны только как ориентир. Ваши данные, фильтры, размеры векторов, модель, железо, concurrency и требования к recall могут дать другую картину.
Сделайте небольшой benchmark на своих данных. Не на случайных векторах, а на реальных чанках, документах или товарах. Проверьте latency, качество выдачи, потребление памяти, скорость обновления и поведение под фильтрами.
Ошибка 4. Дублировать права доступа без контроля
Если права живут в PostgreSQL, а в vector DB вы кладете их копию, появляется риск рассинхронизации. Документ уже закрыт, но поисковый индекс все еще возвращает его фрагменты.
Для RAG это особенно опасно: модель может процитировать пользователю то, что он не должен видеть. Поэтому доступы надо проектировать очень внимательно. Иногда безопаснее делать vector search по кандидатам, а финальную проверку прав - в основной базе.
Ошибка 5. Считать vector DB заменой основной базы
Vector DB - это не универсальная замена PostgreSQL. Она решает задачу similarity search и связанные сценарии retrieval. Но заказы, платежи, пользователи, роли, транзакции и системные события обычно лучше держать в основной БД.
Здоровая архитектура часто выглядит так: PostgreSQL хранит истину, vector DB хранит поисковое представление. Это разные роли, и смешивать их не стоит.

Что выбрать для нового AI-проекта
Если нужен короткий ориентир, можно использовать такую схему.
Выбирайте PostgreSQL с pgvector, если:
• проект новый или среднего размера;
• данные уже в PostgreSQL;
• важна простая эксплуатация;
• поиск тесно связан с бизнес-логикой;
• права доступа и фильтры важнее экстремальной скорости;
• команда хочет быстрее выйти в продакшен.
Выбирайте отдельную vector DB, если:
• поиск является ядром продукта;
• объемы векторов быстро растут;
• нужна независимая масштабируемость;
• есть сложный hybrid search;
• важны низкая latency и высокий throughput;
• команда готова сопровождать отдельный сервис;
• планируются эксперименты с несколькими индексами и моделями.
А если сомневаетесь, чаще всего разумно начать с PostgreSQL, но спроектировать код так, чтобы потом можно было вынести retrieval в отдельный слой. Это не компромисс из слабости. Это нормальная инженерная осторожность.
Рекомендация по инфраструктуре
Для AI-поиска важна не только база, но и сервер, на котором она работает. Векторные индексы любят память, быстрые диски и предсказуемую производительность. Особенно если речь идет о PostgreSQL с HNSW, где размер индекса и настройки памяти напрямую влияют на поведение системы.
Для небольшого RAG-проекта можно начать с аккуратно настроенного VPS или выделенного сервера с запасом RAM. Для более тяжелой нагрузки лучше сразу думать о выделенных ресурсах, NVMe и мониторинге. Векторный поиск плохо чувствует себя там, где соседние процессы внезапно забирают CPU, память или I/O.
Практичная стратегия такая:
1. начать с понятной конфигурации;
2. собрать реальные метрики;
3. измерить latency и recall;
4. посмотреть на рост индексов;
5. масштабировать не по ощущениям, а по данным.
Это звучит менее эффектно, чем «сразу поставим самую мощную систему», зато обычно экономит деньги и нервы.
Итог: нет лучшей базы, есть подходящая архитектура
В споре «vector DB или PostgreSQL» нет универсального победителя.
PostgreSQL с pgvector отлично подходит, когда эмбеддинги являются частью основной модели данных, а команде важны простота, SQL, транзакции, права доступа и быстрая доставка продукта. Это сильный выбор для многих RAG-систем, внутренних AI-поисков и проектов на ранней или средней стадии.
Отдельная vector DB выигрывает, когда поиск становится самостоятельным высоконагруженным сервисом. Большие объемы, низкая задержка, гибридный поиск, независимое масштабирование и активные эксперименты с retrieval - все это аргументы в ее пользу.
Самый практичный путь часто находится посередине: начать с PostgreSQL, не усложнять инфраструктуру раньше времени, но держать слой эмбеддингов достаточно чистым, чтобы при росте нагрузки вынести его в специализированную vector DB.
Хорошая архитектура не пытается угадать будущее идеально. Она дает проекту уверенно стартовать сегодня и спокойно вырасти завтра.




