




















Оглавление
- Что такое корпоративная нейросеть на практике
- Почему нельзя просто открыть сотрудникам доступ к публичному AI
- Какие данные особенно чувствительны для AI-проектов
- Правовая рамка: о чем важно помнить в России
- Отдельно о защищенном доступе и требованиях к контенту
- Как выглядит архитектура корпоративной нейросети
- Где развернуть корпоративный AI
- Пошаговый план запуска корпоративной нейросети
- Какие документы нужны для безопасного запуска
- Типичные ошибки при внедрении корпоративного AI
- Как понять, что корпоративная нейросеть работает хорошо
- Почему инфраструктура важна не меньше модели
- Практический сценарий: внутренний AI-помощник для службы поддержки
- Что лучше не делать в публичной статье и маркетинге
- Чек-лист перед запуском корпоративной нейросети
- Итог
Нейросети уже не выглядят как игрушка для энтузиастов. Они отвечают клиентам, помогают искать документы, пишут черновики писем, анализируют обращения, подсказывают инженерам и экономят часы ручной работы. Но вместе с пользой быстро появляется неудобный вопрос: что именно сотрудники отправляют в AI и куда после этого уходят данные?
Для бизнеса это не мелочь из раздела «потом разберемся». В запрос к нейросети легко случайно вставить договор, коммерческое предложение, выгрузку из CRM, персональные данные клиента или внутреннюю инструкцию. Один неосторожный промпт - и информация оказывается за пределами привычного контура контроля.
Поэтому компании все чаще смотрят в сторону корпоративных нейросетей. Не просто публичного чата «для всех случаев», а внутренней AI-системы, которая работает с нужными документами, соблюдает права доступа и не превращает безопасность в лотерею.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Что такое корпоративная нейросеть на практике
Корпоративная нейросеть - это AI-система, развернутая под задачи конкретной компании. Она может отвечать на вопросы сотрудников, искать информацию в базе знаний, помогать службе поддержки, анализировать документы или готовить черновики рабочих материалов.
Главная разница между такой системой и обычным публичным AI-сервисом - контроль.
Компания сама решает, где хранится база знаний, какие документы доступны модели, кто может задавать запросы, какие действия логируются и какие данные запрещено отправлять в обработку.
Представьте внутреннего консультанта, который знает регламенты, инструкции, тарифы, SLA, технические ограничения и историю типовых обращений. Но при этом не болтает лишнего, не выходит за рамки прав доступа и не передает документы неизвестно куда.
Вот это и есть хорошая корпоративная нейросеть.

Почему нельзя просто открыть сотрудникам доступ к публичному AI
Самый простой путь кажется очевидным: дать команде доступ к популярному AI-инструменту и попросить «не вставлять ничего секретного». На бумаге звучит нормально. В реальной работе - почти всегда дает сбой.
Сотрудник поддержки хочет быстрее ответить клиенту и копирует в чат весь тикет. Юрист просит сократить договор и вставляет текст с реквизитами. Менеджер по продажам просит улучшить коммерческое предложение и случайно отправляет туда условия для крупного клиента.
Никто не хотел нарушать правила. Просто людям нужно было решить задачу быстро.
Проблема в том, что публичный AI-сервис обычно находится вне инфраструктуры компании. Нужно отдельно проверять условия обработки данных, место хранения, политику логирования, возможность использования запросов для улучшения моделей, юрисдикцию и договорные гарантии.
Для бытовых задач это может быть терпимо. Для клиентских данных, коммерческой тайны и внутренних документов - уже нет.
Какие данные особенно чувствительны для AI-проектов
Перед развертыванием нейросети стоит честно ответить на простой вопрос: с какими данными она будет работать?
Не «примерно с документами», а конкретно.
Персональные данные
Это ФИО, телефоны, email-адреса, IP-адреса, паспортные данные, платежная информация, сведения о сотрудниках, клиентах и партнерах. Российский 152-ФЗ определяет персональные данные как любую информацию, относящуюся к прямо или косвенно определенному физическому лицу, а обработку - как широкий набор действий: сбор, запись, хранение, использование, передачу, обезличивание, удаление и другие операции.
Мини-пример: если AI-ассистент анализирует обращения клиентов из CRM, он почти наверняка сталкивается с персональными данными. Даже если задача звучит безобидно - «сгруппировать жалобы по темам».

Коммерческая тайна
Сюда попадают цены, маржинальность, условия с поставщиками, внутренние процессы, список ключевых клиентов, планы развития, закрытые презентации и финансовые расчеты.
Такие данные могут быть не персональными, но их утечка все равно болезненна. Иногда один файл с условиями для крупного клиента стоит дороже, чем десятки обычных документов.
Техническая информация
Исходный код, API-ключи, схемы инфраструктуры, логи, конфигурации серверов, внутренние адреса, настройки доступа.
Здесь особенно опасна привычка «просто спросить AI, где ошибка». Разработчик вставляет лог целиком, а в нем случайно остается токен, пароль или адрес внутреннего сервиса.
Внутренние регламенты
На первый взгляд, это не самые рискованные документы. Но если в них описаны процедуры безопасности, маршруты согласований, роли администраторов и внутренние ограничения, их тоже нельзя бездумно отдавать в общий доступ.
Хорошее правило: если документ нельзя отправить случайному подрядчику по почте, его нельзя без контроля отправлять и в AI.
Правовая рамка: о чем важно помнить в России
Корпоративная нейросеть не существует отдельно от законодательства. Если она обрабатывает персональные данные, она становится частью более широкой системы обработки данных компании.
В России ключевую роль играет 152-ФЗ «О персональных данных». Для AI-проекта особенно важны несколько принципов: наличие цели обработки, ограничение состава данных, безопасность, контроль доступа, учет операций и удаление данных, когда они больше не нужны.
Если компания собирает персональные данные граждан РФ через интернет, нужно учитывать и требование локализации: запись, систематизация, накопление, хранение, уточнение и извлечение таких данных должны выполняться с использованием баз данных, находящихся на территории РФ, за установленными законом исключениями.
На практике это значит: перед запуском внутреннего AI нужно понять, где находятся документы, индексы, векторные базы, логи запросов, резервные копии и административные панели.
AI - это не только модель. Это еще и вся инфраструктура вокруг нее.

Отдельно о защищенном доступе и требованиях к контенту
Для корпоративной AI-системы почти всегда нужен удаленный доступ: сотрудники работают из разных офисов, администраторы подключаются к серверам, разработчики обновляют модель, служба безопасности проверяет журналы.
Но в публичном материале для российского рынка важно аккуратно выбирать формулировки. Российское регулирование ограничивает распространение материалов, связанных с популяризацией способов обхода блокировок, а с 1 сентября 2025 года вступили в силу изменения, связанные с ответственностью за рекламу таких средств.
Поэтому в статье о корпоративной нейросети не нужно рассказывать, как обходить ограничения, перечислять инструменты обхода, давать инструкции по подключению к ним или продвигать такие сервисы.
Корректный фокус другой: защищенный корпоративный доступ, Zero Trust, сегментация сети, межсетевые экраны, bastion host, MFA, журналирование администраторских действий и разграничение прав.
Это не только юридически осторожнее. Это еще и профессиональнее. Компаниям нужен не «обход», а управляемый безопасный доступ к своей инфраструктуре.
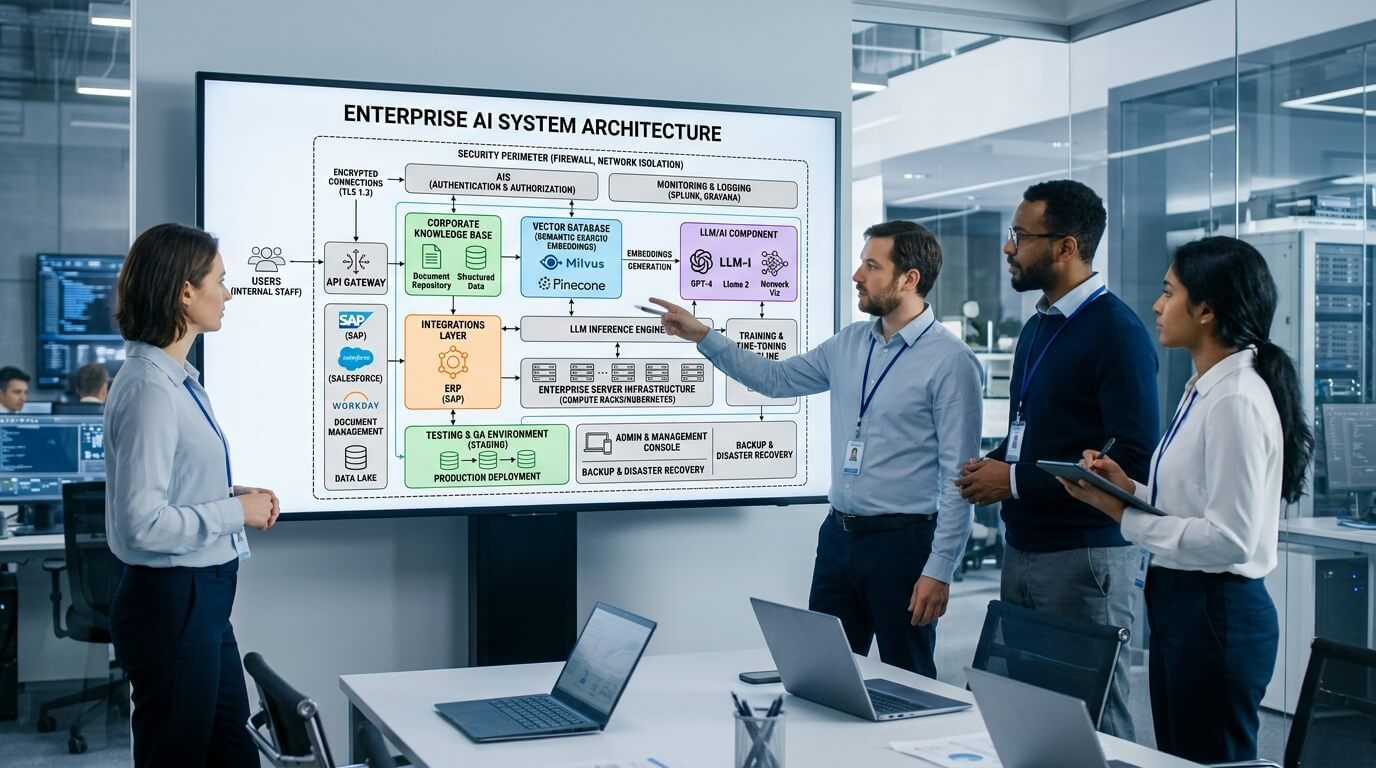
Как выглядит архитектура корпоративной нейросети
Корпоративный AI можно представить как кухню ресторана. Пользователь видит готовое блюдо - ответ в чате. Но за кулисами работают разные станции: модель, база знаний, поиск, права доступа, логирование, мониторинг и серверная инфраструктура.
Если хотя бы один элемент собран наспех, результат будет нестабильным.
1. Серверная инфраструктура
Для тестового проекта может хватить VPS или отдельного сервера без GPU. Например, если модель небольшая, а основная нагрузка - поиск по документам и обращение к внешнему API.
Но если компания хочет запускать собственную LLM, обрабатывать большой поток запросов, строить embeddings, работать с крупными документами или выполнять inference локально, нужны более серьезные ресурсы: CPU, RAM, быстрые NVMe-диски и GPU.
У King Servers есть выделенные серверы для AI и Machine Learning: под обучение моделей, inference, LLM-нагрузки, аналитику и AI-сервисы, с подбором GPU, RAM, NVMe и сетевой конфигурации под задачу.
Простой пример: внутренний бот для 20 сотрудников может жить на умеренной конфигурации. А AI-помощник для поддержки, который обрабатывает тысячи обращений и ищет по большой базе знаний, уже потребует отдельного расчета нагрузки.
2. Языковая модель
Модель - это двигатель системы. Она принимает запрос, контекст и формирует ответ.
Не всегда нужна самая большая модель. Иногда компактная модель, хорошо настроенная под сценарий, дает лучший результат: быстрее отвечает, дешевле обслуживается и проще контролируется.
Для компании важно оценивать не только качество ответов, но и практические параметры:
сколько памяти нужно модели; какая задержка ответа допустима; поддерживает ли она русский язык; можно ли запускать ее локально; насколько удобно ограничивать ее поведение; как она работает с длинными документами.
Здесь полезна аналогия с автомобилем. Грузовик мощнее легковой машины, но это не значит, что на нем удобно ездить за документами в соседний офис. Модель нужно выбирать под маршрут.
3. RAG-слой
RAG - это подход, при котором нейросеть отвечает не «из памяти», а с опорой на подключенные документы.
Сначала система ищет релевантные фрагменты в базе знаний, затем передает их модели, а модель формирует ответ. Так AI меньше фантазирует и чаще опирается на актуальные источники.
Например, сотрудник спрашивает: «Какой порядок обработки возврата по корпоративному клиенту?» Система находит нужный раздел регламента, подтягивает его в контекст и отвечает на основе документа.
Без RAG модель может уверенно придумать порядок, которого в компании никогда не было. С RAG она работает как сотрудник, который сначала открыл инструкцию, а уже потом дал ответ.
4. Векторная база данных
Чтобы AI быстро находил нужные документы, их нужно превратить в векторы - числовые представления смысла.
Звучит сложно, но идея простая. Обычный поиск ищет совпадения слов. Векторный поиск ищет близость смысла.
Если сотрудник спросит «как оформить доступ новому инженеру», система может найти документ под названием «Регламент выдачи учетных записей техническим специалистам». Слова разные, смысл близкий.
Для корпоративной базы знаний это особенно полезно: люди редко формулируют вопросы так же, как названы документы.
5. Контроль доступа
Самый важный принцип: AI не должен видеть больше, чем видит пользователь.
Если менеджер по продажам не имеет доступа к зарплатным ведомостям, нейросеть тоже не должна отвечать ему на вопросы по этим документам. Если подрядчик может видеть только проектную документацию по своему направлению, AI не должен подтягивать ему внутренние финансовые отчеты.
Это кажется очевидным, но на практике именно здесь часто возникают ошибки.
Компании подключают «всю базу знаний», запускают чат для всех сотрудников и только потом замечают, что бот слишком охотно отвечает на лишние вопросы.
Правильный путь - интеграция с ролями, группами, каталогом пользователей и политиками доступа. Нейросеть должна наследовать корпоративную модель прав, а не жить отдельно от нее.

6. Логирование и аудит
Логи нужны не для тотального контроля сотрудников, а для безопасности и качества.
Они помогают понять:
кто задавал запрос; какие документы использовались в ответе; были ли попытки получить запрещенную информацию; где модель ошиблась; какие разделы базы знаний нужно обновить; не попали ли в запросы лишние данные.
Но логи сами могут стать источником риска. Если сотрудник вставил в запрос персональные данные или коммерческую информацию, это окажется в журнале.
Поэтому нужно заранее решить, что логируется, как долго хранится, кто имеет доступ к журналам и какие данные нужно маскировать.
Слои корпоративной нейросети
Пользователь видит ответ в чате; за кулисами — шесть опорных компонентов.
Слабое звено (права, устаревшие документы, логи с ПДн) ломает всю систему быстрее, чем «не та» модель.
Как работает RAG внутри компании
Сначала поиск по документам с учётом прав, затем ответ модели.
Где развернуть корпоративный AI
Есть несколько вариантов. У каждого свои плюсы и ограничения.
Вариант 1. На собственной инфраструктуре компании
Это максимальный контроль. Серверы стоят в вашем контуре, доступ регулируется внутренними политиками, данные не уходят к внешним поставщикам.
Минус - стоимость и сложность. Нужно покупать оборудование, обслуживать GPU, следить за охлаждением, обновлениями, резервированием, безопасностью и масштабированием.
Для крупных компаний с сильной IT-командой это может быть оправдано. Для среднего бизнеса - не всегда.
Вариант 2. На выделенном сервере
Выделенный сервер - хороший компромисс между контролем и затратами. Компания получает отдельные аппаратные ресурсы, может настроить окружение под себя, изолировать сервисы, развернуть векторную базу, модель, мониторинг и систему доступа.
Это особенно удобно для пилота: можно начать с понятной конфигурации, проверить сценарий и затем масштабироваться.
Например, сначала компания запускает AI-поиск по внутренним инструкциям. Если пилот успешен, добавляет обработку тикетов, интеграцию с helpdesk и отдельный контур для юридических документов.
Вариант 3. В публичном облаке или через внешний AI API
Это быстрый старт. Не нужно поднимать модель, думать о GPU и обслуживании.
Но здесь больше вопросов к данным: где они обрабатываются, кто имеет доступ, как хранятся запросы, можно ли удалить историю, используется ли информация для улучшения модели, есть ли трансграничная передача.
Для открытых данных и некритичных задач такой вариант может быть удобен. Для персональных данных, коммерческой тайны и внутренних документов нужен отдельный анализ рисков.
Пошаговый план запуска корпоративной нейросети
Хороший AI-проект начинается не с выбора модели. Он начинается с задачи.
Шаг 1. Выберите один понятный сценарий
Не стоит запускать «AI для всей компании» сразу. Это как строить офис, не понимая, сколько людей там будет работать и чем они занимаются.
Лучше выбрать один сценарий:
поиск по базе знаний; помощник для службы поддержки; анализ внутренних инструкций; подготовка черновиков ответов; классификация обращений; поиск по договорам; помощь DevOps-команде с документацией.
Хороший вопрос для старта: где сотрудники чаще всего тратят время на поиск информации?
Если ответ - «в регламентах и старых документах», RAG-ассистент может дать быстрый эффект.
Шаг 2. Проведите инвентаризацию данных
Перед подключением документов нужно понять, что в них лежит.
Один файл может выглядеть как обычная инструкция, но внутри содержать имена клиентов, номера договоров, внутренние адреса, логины, технические схемы или финансовые условия.
Разделите данные по категориям:
публичные; внутренние; конфиденциальные; персональные; критичные технические; запрещенные для обработки в AI без отдельного согласования.
Это скучная работа, зато она экономит нервы. Как уборка склада перед автоматизацией: сначала нужно понять, какие коробки вообще стоят на полках.
Шаг 3. Очистите базу знаний
Нейросеть не делает старые документы правильными. Она только быстрее достает из них информацию.
Если в базе знаний есть три версии одной инструкции, устаревшие тарифы, противоречивые правила и файлы «final_final_новый_точно.docx», AI будет путаться.
Перед запуском нужно убрать дубли, отметить актуальные версии, назначить владельцев документов и настроить регулярное обновление.
Мини-пример: если служба поддержки пользуется старым FAQ, бот будет повторять старые ответы. Проблема будет не в модели, а в источнике.
Шаг 4. Определите правила обработки данных
Для каждого типа данных нужно прописать правила:
можно ли использовать в AI; можно ли хранить в индексе; нужно ли обезличивание; кто имеет доступ; как долго хранятся логи; кто отвечает за удаление; что делать при инциденте.
Если AI работает с персональными данными, компания должна учитывать требования 152-ФЗ: цель обработки, объем данных, основания обработки, меры защиты и контроль доступа.
Здесь полезно подключить юриста, специалиста по информационной безопасности и владельцев бизнес-процессов. AI-проект не должен быть только задачей разработчиков.
Шаг 5. Выберите инфраструктуру
Инфраструктура зависит от сценария.
Для небольшого внутреннего поиска по документам может хватить сервера с хорошим CPU, достаточным объемом RAM и быстрым NVMe. Для локального запуска LLM и высокой нагрузки может потребоваться GPU.
На этом этапе важно оценить:
количество пользователей; ожидаемое число запросов в день; размер базы знаний; требования к скорости ответа; необходимость локального inference; объем логов и резервных копий; требования к размещению данных.
Не стоит брать конфигурацию «на глаз». Лучше начать с пилота, измерить нагрузку и масштабировать осознанно.
Шаг 6. Разверните RAG и подключите документы
После подготовки инфраструктуры можно собирать рабочую схему:
документы загружаются в хранилище; текст разбивается на фрагменты; фрагменты преобразуются в embeddings; embeddings попадают в векторную базу; пользователь задает вопрос; система ищет релевантные фрагменты; модель формирует ответ; ответ возвращается пользователю с учетом прав доступа.
Хороший тон - показывать источники ответа. Тогда сотрудник видит, откуда взята информация, и может быстро открыть оригинальный документ.
Это снижает слепую веру в AI и повышает доверие к системе.

Шаг 7. Настройте безопасность
Минимальный набор для корпоративной нейросети:
MFA для администраторов; разграничение ролей; изоляция сервисов; шифрование соединений; контроль сетевых доступов; резервное копирование; мониторинг нагрузки; журналирование действий; маскирование чувствительных данных; регулярное обновление компонентов.
Отдельно стоит настроить фильтры запросов. Например, система должна реагировать на попытки получить пароли, секретные ключи, персональные данные без основания или документы вне зоны доступа пользователя.
AI не должен быть «добрым сотрудником», который пытается помочь любой ценой. В корпоративной среде он должен быть полезным, но дисциплинированным.
Шаг 8. Обучите сотрудников
Даже самая аккуратная инфраструктура не спасет, если люди не понимают правил.
Сотрудникам нужно объяснить простыми словами:
какие задачи можно решать через AI; какие данные нельзя вставлять в запрос; почему нельзя отправлять пароли и ключи; как проверять ответы; куда сообщать об ошибках; что делать, если AI выдал лишнюю информацию.
Лучший формат - не длинная политика на 30 страниц, а короткая инструкция с примерами.
Например:
Плохо: «Проанализируй договор с клиентом Ивановым, вот полный текст с паспортными данными».
Лучше: «Сделай краткое резюме условий договора. Персональные данные удалены, реквизиты заменены плейсхолдерами».
Так правила становятся не абстрактным запретом, а рабочей привычкой.
Какие документы нужны для безопасного запуска
Корпоративная нейросеть должна быть не только технически настроена, но и организационно оформлена.
Обычно нужны:
политика использования AI; перечень разрешенных и запрещенных данных; модель ролей и доступов; порядок логирования; регламент обработки инцидентов; правила обезличивания; инструкция для сотрудников; порядок обновления базы знаний; описание инфраструктуры; договоры и поручения обработки данных, если есть подрядчики.
Не обязательно превращать пилот в бюрократический монумент. Но минимальные правила должны быть зафиксированы до запуска, а не после первого инцидента.
Хорошая политика отвечает на три вопроса: что можно, что нельзя и кто отвечает.
Типичные ошибки при внедрении корпоративного AI
Ошибка 1. Подключить все документы сразу
Это частый соблазн. Кажется, чем больше данных, тем умнее будет нейросеть.
На деле получается наоборот: модель видит устаревшие файлы, дубли, лишние документы и начинает выдавать спорные ответы.
Лучше начать с небольшой, чистой и актуальной базы. Пусть бот сначала хорошо отвечает на 100 важных вопросов, чем плохо на 10 000 случайных.
Ошибка 2. Забыть про права доступа
Если у всех пользователей один общий AI-чат с одной общей базой, это почти всегда риск.
Отдел продаж не должен видеть HR-документы. Подрядчик не должен получать внутренние финансовые инструкции. Стажер не должен вытаскивать технические схемы всей инфраструктуры.
Права доступа должны быть частью архитектуры, а не «доработкой потом».
Ошибка 3. Логировать слишком много
Логи полезны. Но если в них сохраняются полные запросы с персональными данными, коммерческими условиями и техническими секретами, они сами становятся чувствительным хранилищем.
Нужно логировать достаточно для аудита, но не больше, чем нужно.
Иногда лучше хранить обезличенные события: кто, когда, к какому классу документов обращался и был ли ответ заблокирован.
Ошибка 4. Не проверять ответы модели
AI может ошибаться уверенно. Особенно если документ устарел, вопрос задан двусмысленно или в базе знаний есть противоречия.
Поэтому для критичных процессов нужен человек в контуре. Нейросеть готовит черновик, ищет источник, предлагает вариант, но финальное решение принимает сотрудник.
Это особенно важно для юридических, финансовых, кадровых и технически рискованных задач.
Ошибка 5. Считать AI только IT-проектом
Корпоративная нейросеть затрагивает юристов, ИБ, HR, поддержку, продажи, разработку и руководство.
Если проект делает только IT-отдел, высок риск собрать технически красивую систему, которой неудобно пользоваться или которую нельзя безопасно применять в реальных процессах.
Нужна команда: владелец бизнес-задачи, технический специалист, ИБ, юрист и представители будущих пользователей.
Как понять, что корпоративная нейросеть работает хорошо
У хорошего AI-проекта есть измеримые признаки.
Сотрудники быстрее находят информацию. Поддержка отвечает клиентам точнее. Новички быстрее разбираются в процессах. Руководители видят, какие вопросы повторяются чаще всего. База знаний становится чище, потому что ошибки модели подсвечивают слабые места в документации.
Можно отслеживать такие метрики:
время поиска ответа; доля успешных ответов; количество обращений к базе знаний; частота эскалаций к эксперту; количество заблокированных рискованных запросов; удовлетворенность пользователей; нагрузка на серверы; стоимость одного ответа.
AI должен быть не модным баннером в интерфейсе, а инструментом, который экономит время и снижает операционный хаос.
Если сотрудники после пилота говорят: «Мы теперь не хотим возвращаться к старому поиску», значит вы на правильном пути.
Что измерять после пилота
Метрики качества и безопасности, а не только «нравится ли чат».
Почему инфраструктура важна не меньше модели
Многие обсуждают AI так, будто весь проект сводится к выбору модели. Какая лучше? Какая умнее? Какая быстрее?
Но в корпоративной среде модель - только часть системы.
Не менее важны серверы, хранилище, сеть, мониторинг, резервное копирование, доступы, обновления и поддержка. Даже сильная модель будет бесполезна, если она медленно отвечает, падает под нагрузкой или работает с неактуальными документами.
Для AI-нагрузок особенно важны:
быстрые NVMe-диски для индексов и баз; достаточный объем RAM; производительный CPU; GPU для локальных моделей и интенсивного inference; стабильная сеть; возможность масштабирования; понятная панель управления; техническая поддержка.
Выделенный сервер или GPU-сервер позволяет компании не смешивать AI-нагрузку с другими сервисами и точнее контролировать окружение.
Для пилота это дает предсказуемость. Для промышленного запуска - устойчивость.
Практический сценарий: внутренний AI-помощник для службы поддержки
Представим компанию, где поддержка каждый день отвечает на сотни однотипных вопросов. Инструкции есть, но они разбросаны по документам, чатам, старым таблицам и внутренней базе знаний.
Сотрудник тратит 5-10 минут, чтобы найти нужный ответ. Иногда отвечает по памяти. Иногда ошибается, потому что видел старую версию инструкции.
Как можно внедрить корпоративную нейросеть:
собрать актуальные инструкции; убрать устаревшие документы; разделить материалы по продуктам; закрыть документы с персональными данными; развернуть RAG-систему на выделенном сервере; подключить авторизацию сотрудников; настроить логи и источники ответов; запустить пилот на небольшой группе поддержки; собрать вопросы, ошибки и недостающие документы; масштабировать систему на весь отдел.
В результате AI не заменяет поддержку, а помогает ей быстрее находить точные ответы.
Это как опытный коллега рядом, который помнит, где лежит нужная инструкция, и не устает от повторяющихся вопросов.
Что лучше не делать в публичной статье и маркетинге
Если материал публикуется на сайте компании, особенно для российской аудитории, стоит избегать формулировок, которые могут выглядеть как продвижение обхода ограничений.
Не нужно:
давать инструкции по обходу блокировок; перечислять сервисы для обхода ограничений; писать рекламные фразы про такие инструменты; объяснять, как получить доступ к запрещенным ресурсам; строить сценарии вокруг обхода ограничений.
Лучше писать о безопасной корпоративной инфраструктуре:
закрытый контур; защищенный административный доступ; Zero Trust; MFA; сегментация сети; контроль сетевых правил; bastion host; мониторинг подключений; журналирование действий; соответствие внутренним политикам ИБ.
Так статья остается полезной для бизнеса и не уходит в рискованную плоскость.

Чек-лист перед запуском корпоративной нейросети
Перед тем как выводить AI в продакшен, стоит пройти короткий контрольный список.
Определен конкретный бизнес-сценарий. Проведена инвентаризация документов. Данные разделены по категориям чувствительности. Проверено наличие персональных данных. Определены цели и основания обработки. Учтены требования локализации, если обрабатываются данные граждан РФ. Настроены роли и права доступа. Выбрана инфраструктура под нагрузку. Подключена актуальная база знаний. Настроены логи и срок их хранения. Есть фильтры рискованных запросов. Сотрудники получили понятную инструкцию. Назначен владелец системы. Есть план обновления документов. Есть процедура реагирования на инциденты.
Если хотя бы несколько пунктов вызывают сомнения, запуск лучше не ускорять. В AI-проектах спешка часто стоит дороже, чем аккуратная подготовка.
Итог
Корпоративная нейросеть - это не «чатик с искусственным интеллектом», а полноценная информационная система. Она работает с документами, пользователями, правами доступа, логами, персональными данными и внутренними процессами компании.
Правильный путь начинается не с выбора самой громкой модели, а с понятной задачи, чистой базы знаний, аккуратной архитектуры и уважения к требованиям безопасности.
Развернуть AI внутри компании реально. Более того, это может быстро дать практический эффект: ускорить поддержку, упростить поиск по документам, помочь новым сотрудникам и снизить нагрузку на экспертов.
Главное - не превращать нейросеть в черный ящик. Данные должны оставаться под контролем, доступы - соответствовать ролям, инфраструктура - выдерживать нагрузку, а сотрудники - понимать правила работы.
Тогда корпоративный AI становится не источником новых рисков, а надежным инструментом роста. И чем раньше компания выстроит такой подход, тем спокойнее она сможет использовать нейросети не «на страх и риск», а как зрелую часть своей цифровой инфраструктуры.




