



















Оглавление
- Почему надежность - это не только задача инженеров
- SLI, SLO, SLA и error budget: коротко о главном
- Почему 100% надежности почти никогда не цель
- Как SLO связывает инженеров и бизнес
- SLA: почему обещать нужно меньше, чем умеете
- Error budget как инструмент для честных решений
- Как посчитать error budget на простом примере
- Какие метрики выбирать для SLI
- Как задавать SLO без самообмана
- SLO и инфраструктура: где VPS, а где выделенный сервер
- Почему мониторинг без SLO часто шумит
- Как внедрить SLO без бюрократии
- Частые ошибки при работе с SLO, SLA и error budget
- Как SLO помогает считать деньги
- SLO как основа для разговоров с клиентами
- Практический пример: интернет-магазин на VPS
- Практический пример: B2B API с внешним SLA
- Что должно быть в хорошей политике error budget
- Как KingServers-подход ложится на надежность
- Мини-чек-лист для старта
- Итог: надежность должна работать на бизнес, а не жить отдельно
Надежность редко обсуждают, пока всё работает. Сайт открывается, заявки приходят, клиенты оплачивают заказы, команда спокойно выкатывает обновления - и кажется, что инфраструктура просто «должна» быть стабильной. Но стоит сервису лечь в неподходящий момент, как техническая проблема быстро превращается в бизнес-проблему: падают продажи, растет нагрузка на поддержку, клиенты теряют доверие. Именно поэтому надежность нельзя измерять только ощущениями. Бизнесу нужны понятные ориентиры: какой уровень доступности действительно нужен, сколько простоя допустимо, когда стоит ускорять разработку, а когда лучше остановиться и заняться стабильностью. Для этого в инженерных командах используют SLO, SLA и error budget. Эти термины звучат сухо, но на практике они помогают говорить о надежности простым языком. Не «сервер иногда тормозит», а «мы сжигаем бюджет ошибок быстрее, чем планировали». Не «нужно сделать надежнее», а «для этой услуги достаточно 99,9%, а для платежей нужен более строгий показатель». Разница большая.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Почему надежность - это не только задача инженеров
Когда сервис работает нестабильно, первым обычно страдает пользователь. Он не видит CPU load, сетевые задержки, ошибки базы данных или перегруженный API. Он видит другое: страница не открылась, оплата не прошла, личный кабинет завис, заказ не оформился. Для бизнеса это выглядит еще шире. Один сбой может ударить по выручке. Другой - по репутации. Третий - по обязательствам перед клиентами. А если инциденты повторяются, компания начинает жить в режиме тушения пожаров: разработчики чинят срочные ошибки, поддержка отвечает на одинаковые жалобы, менеджеры объясняют клиентам, почему «так получилось». Здесь и появляется главная идея SLO, SLA и error budget: надежность должна быть управляемой. Не абстрактной мечтой о 100% аптайме, а понятной системой решений. Представьте интернет-магазин. Если карточка товара открывается на секунду дольше обычного, это неприятно, но не всегда критично. Если не работает корзина, ущерб уже серьезнее. Если недоступна оплата, бизнес теряет деньги прямо сейчас. Все эти части системы не должны иметь одинаковый приоритет. У них разная цена отказа. Надежность начинается с честного вопроса: что именно должно работать стабильно, для кого и насколько хорошо?
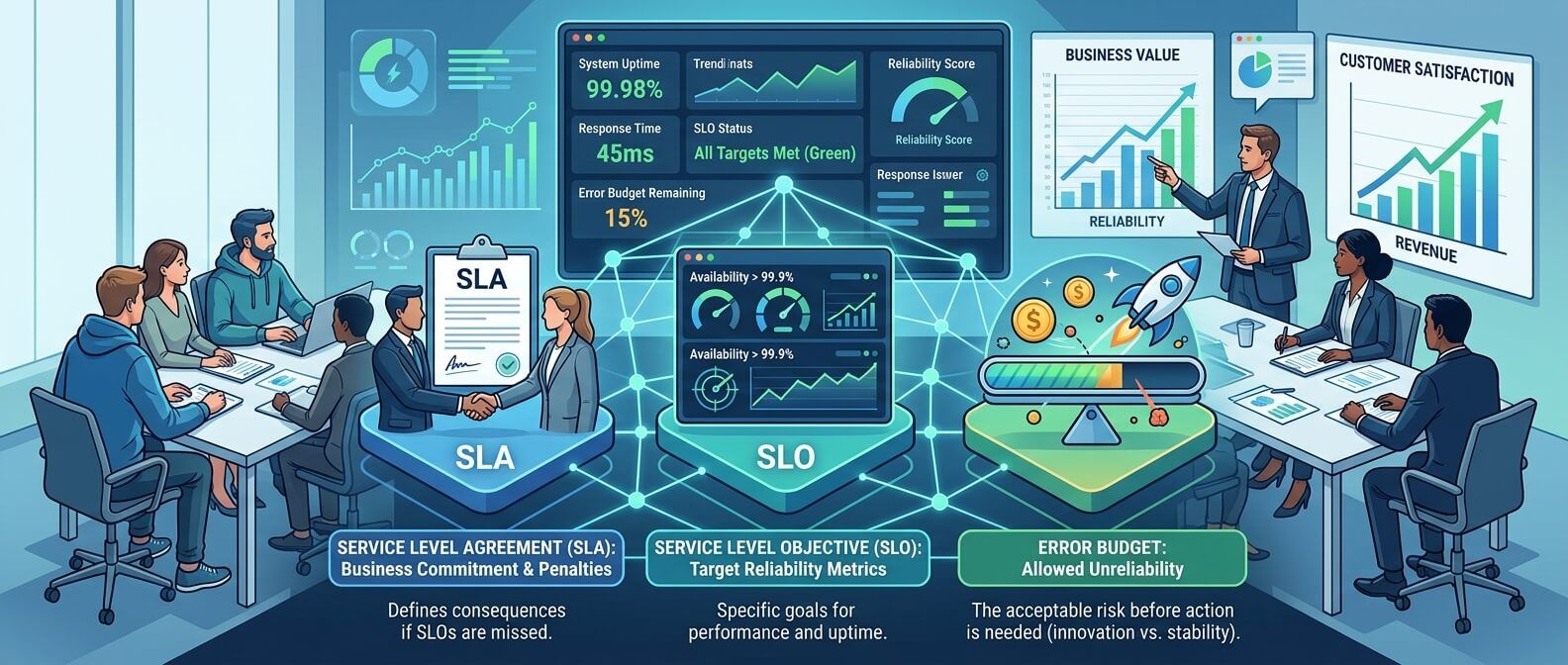
SLI, SLO, SLA и error budget: коротко о главном
Чтобы не путаться в терминах, полезно разложить их по ролям.
SLI - что именно измеряем
SLI, или Service Level Indicator, - это показатель уровня сервиса. Он отвечает на вопрос: «По какой метрике мы понимаем, что сервис работает хорошо?»
Например
• доля успешных HTTP-запросов
• время ответа API
• процент успешных платежей
• доступность сайта
• количество ошибок 5xx
• скорость загрузки страницы
• доля запросов, обработанных быстрее заданного порога.
SLI - это термометр. Он сам по себе не говорит, хорошо или плохо. Он просто показывает температуру. Если у интернет-магазина 99,95% запросов к странице оформления заказа проходят успешно, это SLI. Если среднее время ответа API составляет 180 мс, это тоже SLI. Главное - метрика должна отражать опыт пользователя, а не только внутреннее состояние сервера. Например, сервер может быть «живым» с точки зрения мониторинга, но приложение при этом отдает ошибки. Формально машина работает. Для клиента - сервис сломан.

SLO - какого уровня хотим достичь
SLO, или Service Level Objective, - это целевой уровень надежности. Он отвечает на вопрос: «Какой показатель мы считаем нормальным?»
Например
• 99,9% успешных запросов за 30 дней
• 95% ответов API быстрее 300 мс
• 99,5% успешных платежных операций за месяц
не более 0,1% ошибок на критическом пользовательском пути. Если SLI - термометр, то SLO - отметка, выше которой температура считается допустимой. Важно: хороший SLO не обязан быть максимальным. Кажется, что 99,999% всегда лучше, чем 99,9%. Но каждое дополнительное «девятка» обычно стоит денег, времени и инженерного внимания. Иногда бизнесу действительно нужна почти безупречная доступность. Иногда достаточно стабильного, но более экономичного уровня. Например, для внутренней аналитической панели может быть нормально, если она недоступна несколько минут в месяц. А для платежного шлюза даже короткий сбой может стоить дорого. Один и тот же стандарт для этих систем будет либо слишком слабым, либо слишком дорогим.
SLA - что обещаем клиенту
SLA, или Service Level Agreement, - это соглашение об уровне сервиса. Обычно оно фиксирует обязательства перед клиентом: доступность, время реакции, порядок компенсаций, границы ответственности. SLO живет внутри команды. SLA выходит наружу. Например, команда может держать внутренний SLO на уровне 99,95%, а в SLA обещать клиентам 99,9%. Такой запас нужен, чтобы не превращать каждый небольшой технический сбой в нарушение договора. SLA - это уже не просто инженерный ориентир. Это юридическое и коммерческое обещание. Поэтому его нельзя назначать «на глаз». Если в договоре указана доступность 99,99%, инфраструктура, процессы, мониторинг, поддержка и бюджет должны соответствовать этому уровню. Иначе SLA становится красивой цифрой на бумаге, которая при первом серьезном инциденте превращается в проблему для бизнеса.
Error budget - сколько ошибок мы можем себе позволить
Error budget, или бюджет ошибок, - это допустимый объем ненадежности в рамках SLO. Звучит непривычно, но идея очень практичная: если мы не требуем 100% надежности, значит у нас есть небольшой запас на сбои, ошибки, деградации и рискованные изменения. Например, если SLO по доступности составляет 99,9% за месяц, то error budget равен 0,1%. Это тот небольшой процент времени или запросов, который сервис может «потерять», не нарушив внутреннюю цель. Можно представить error budget как запас топлива. Пока он есть, команда может ехать быстрее: выкатывать новые функции, проводить эксперименты, менять архитектуру. Если запас заканчивается, пора сбавить скорость и заняться надежностью. Это здоровый баланс. Бизнесу нужны новые функции, но бизнесу также нужна стабильность. Error budget помогает не спорить на эмоциях, а принимать решения по данным.
Цепочка: SLI → SLO → SLA
Внутри команды — измерение и цель; наружу — осторожное обещание с буфером.
Error budget = допустимый объём ненадёжности в рамках SLO.
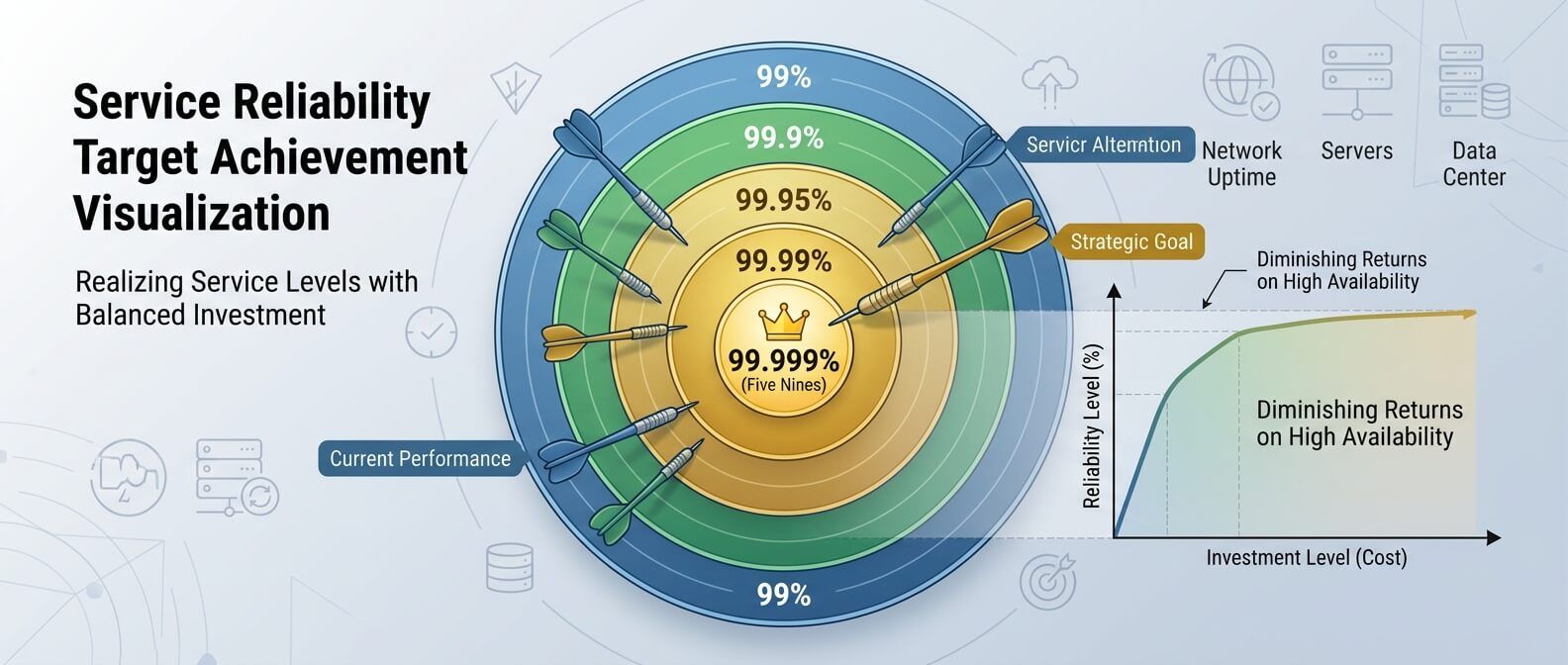
Почему 100% надежности почти никогда не цель
На первый взгляд всё просто: чем выше доступность, тем лучше. Но в реальной инфраструктуре 100% надежности - это не цель, а ловушка. Чтобы приблизиться к абсолютной доступности, нужно резервировать всё: серверы, сети, базы данных, балансировщики, каналы связи, команды поддержки, процессы деплоя. Чем выше требование, тем дороже каждый следующий шаг. При этом пользователь не всегда заметит разницу между 99,9% и 99,99%, а бюджет заметит. Допустим, у компании есть сервис для просмотра отчетов. Если он недоступен 10 минут ночью, бизнес почти ничего не теряет. Делать для него архитектуру уровня критической банковской системы может быть неразумно. А теперь другой пример: сервис авторизации для B2B-платформы. Если он падает, пользователи не могут войти, клиенты не могут работать, поддержка получает шквал обращений. Здесь более высокий SLO уже оправдан. Надежность должна соответствовать ценности сервиса. Это похоже на выбор автомобиля. Для поездок по городу не всегда нужен бронированный внедорожник с запасным двигателем. Но если вы везете медицинское оборудование через сложный маршрут, требования меняются. В инфраструктуре логика такая же: надежность должна быть не максимальной, а адекватной риску.
Сколько простоя в месяц
Каждая дополнительная «девятка» резко сокращает допустимый downtime — и удорожает инфраструктуру.
Как SLO связывает инженеров и бизнес
Одна из главных проблем в обсуждении надежности - разные языки. Инженеры говорят о latency, uptime, packet loss, saturation, retries и ошибках 5xx. Бизнес говорит о продажах, клиентах, договорах, LTV, репутации и стоимости простоя. Оба языка важны, но между ними нужен переводчик. SLO как раз выполняет эту роль. Хорошо сформулированный SLO связывает техническую метрику с бизнес-эффектом. Например:
• «99,9% запросов к checkout должны завершаться успешно за 30 дней»
• «95% ответов API каталога должны быть быстрее 300 мс»
• «99,95% операций авторизации должны проходить без ошибок»
«страница оплаты должна быть доступна в 99,99% пользовательских минут». Это уже не просто «сервер должен работать». Это конкретный ориентир: какой пользовательский путь защищаем, какой уровень качества нужен, за какой период измеряем.

Мини-пример
У SaaS-сервиса есть три ключевые зоны: лендинг, личный кабинет и API для клиентов. Лендинг важен для маркетинга, но кратковременная недоступность ночью может быть терпимой. Личный кабинет важнее, потому что влияет на текущих пользователей. API критичен, потому что встроен в процессы клиентов. Значит, SLO для этих зон должны отличаться. И это нормально. Так бизнес перестает платить за «надежность вообще» и начинает инвестировать в надежность там, где она действительно влияет на деньги, доверие и удержание клиентов.
Разные SLO для зон SaaS
Лендинг, кабинет и API — разная цена отказа.
SLA: почему обещать нужно меньше, чем умеете
SLA часто воспринимают как маркетинговую цифру. Чем выше, тем солиднее. Но в инфраструктуре обещания должны быть осторожными. Если компания публично обещает 99,99% доступности, она должна понимать, что это означает на практике. Это не только серверы. Это мониторинг, резервирование, регламенты, дежурства, реакция на инциденты, тестирование отказов, работа с поставщиками, документация и поддержка. SLA должен быть ниже или равен тому уровню, который команда уверенно умеет поддерживать. Внутренний SLO при этом лучше держать выше SLA. Так появляется буфер.
Например
• внутренний SLO: 99,95%
• внешний SLA: 99,9%.
На бумаге разница небольшая. В реальности это пространство для маневра. Если случился небольшой инцидент, команда может остаться в рамках SLA и при этом увидеть, что внутренний SLO под угрозой. Значит, есть время отреагировать до того, как проблема станет договорной. Это похоже на финансовый резерв. Компания не планирует потратить все деньги до нуля. Она оставляет запас на непредвиденные расходы. В надежности этот запас так же важен.
Буфер между SLO и SLA
Внутренний SLO выше внешнего SLA — пространство для манёвра до нарушения договора.
Error budget как инструмент для честных решений
Самая сильная сторона error budget - он снимает вечный конфликт между разработкой и эксплуатацией. Разработчики хотят быстрее выпускать функции. Операционные команды хотят меньше риска и больше стабильности. Бизнес хочет и то, и другое: новые возможности без падений. На словах это звучит отлично, но в реальности любой релиз несет риск. Error budget помогает договориться заранее. Если бюджет ошибок почти не потрачен, команда может позволить себе больше изменений: частые релизы, эксперименты, оптимизации, миграции. Если бюджет быстро сгорает, это сигнал: сервис уже ведет себя хуже, чем нужно пользователям и бизнесу. Значит, фокус временно смещается на стабильность. Например, команда запланировала крупное обновление личного кабинета. За последние две недели сервис уже пережил несколько инцидентов, и error budget почти закончился. В такой ситуации разумнее отложить рискованный релиз, закрыть причины сбоев, улучшить тесты и только потом двигаться дальше. Это не торможение бизнеса. Это защита бизнеса от еще более дорогой ошибки. Error budget делает надежность предметом управленческого решения. Не «админы опять запрещают релиз», а «мы израсходовали 80% бюджета ошибок за половину периода, поэтому новая функциональность подождет, пока не восстановим устойчивость».
Как посчитать error budget на простом примере
Возьмем SLO: 99,9% успешных запросов за 30 дней. Это означает, что допустимая доля ошибок - 0,1%. Если за месяц сервис обработал 10 000 000 запросов, error budget составит 10 000 ошибочных запросов.
Формула простая
Error budget = 100% - SLO
Для SLO 99,9% бюджет ошибок равен 0,1%. Теперь представим, что за первую неделю произошло 6 000 ошибок. Формально месячный SLO еще может быть выполнен. Но команда уже потратила 60% бюджета за четверть периода. Это тревожный сигнал: если темп сохранится, цель будет сорвана. Такой подход лучше обычного мониторинга «красное/зеленое». Он показывает не только факт проблемы, но и скорость, с которой сервис приближается к нарушению цели. В этом месте полезно смотреть не только на общий процент доступности, но и на burn rate - скорость сжигания бюджета ошибок. Если бюджет сгорает слишком быстро, алерт должен сработать раньше, чем SLO будет окончательно нарушен. Иначе получится как с автомобилем, где лампочка топлива загорается уже после того, как машина заглохла. Формально сигнал есть. Практически - поздно.
Какие метрики выбирать для SLI
Самая частая ошибка - выбирать SLI по принципу «что проще измерить». Например, смотреть только на загрузку процессора или доступность сервера по ping. Эти метрики полезны, но они не всегда показывают качество сервиса для пользователя. Хороший SLI должен быть ближе к пользовательскому опыту. Пользователю не важно, что CPU загружен всего на 30%, если страница оплаты возвращает ошибку. Ему не важно, что сервер отвечает на ping, если приложение зависло. Для разных сервисов подходят разные SLI.
Для сайта
Можно измерять
• доступность главных страниц
• время загрузки
• долю успешных HTTP-запросов
• ошибки 5xx
• успешность отправки форм.
Пример: для корпоративного сайта важным SLI может быть «доля успешных загрузок главной страницы быстрее 2 секунд».
Для интернет-магазина
Здесь важнее смотреть на пользовательские пути
• просмотр товара
• добавление в корзину
• оформление заказа
• оплата
• отправка уведомлений.
Пример: «99,5% попыток оформления заказа должны завершаться успешно за 30 дней». Такая метрика гораздо полезнее, чем средняя загрузка сервера.
Для API
Для API часто измеряют
• успешность запросов
• latency по percentiles, например p95 или p99
• количество таймаутов
• ошибки авторизации
• корректность ответов.
Пример: «95% запросов к API должны отвечать быстрее 300 мс, а доля ошибок 5xx не должна превышать 0,1%».

Для инфраструктуры на VPS/VDS или выделенных серверах
Здесь важно соединить инфраструктурные и продуктовые показатели
• доступность узлов
• доступность приложения
• сетевые задержки
• дисковый ввод-вывод
• ошибки базы данных
• успешность бэкапов
• время восстановления после сбоя.
Например, VPS может быть доступен, но база данных на нем уперлась в диск. Или выделенный сервер имеет запас по CPU, но приложение страдает из-за неудачной конфигурации Nginx. Поэтому SLI лучше строить не только вокруг железа, а вокруг результата для пользователя.
Как задавать SLO без самообмана
SLO должен быть амбициозным, но достижимым. Если поставить цель слишком низко, пользователи будут недовольны. Если поставить слишком высоко, команда будет постоянно жить в режиме тревоги. Есть несколько практичных вопросов, которые помогают выбрать разумный уровень.
Что пользователь считает нормальной работой?
Для стримингового сервиса короткая деградация качества видео может быть терпимой, если воспроизведение продолжается. Для банковской операции даже небольшой сбой выглядит критично. Нужно смотреть глазами пользователя: где он готов подождать, а где сразу теряет доверие?
Сколько стоит простой?
Если час недоступности стоит бизнесу несколько тысяч долларов, требования к надежности будут одними. Если сервис внутренний и используется несколькими сотрудниками, требования могут быть мягче. Здесь полезно считать не только прямые потери, но и косвенные: нагрузку на поддержку, компенсации, репутационный ущерб, отток клиентов.
Какие ресурсы есть у команды?
SLO не должен игнорировать реальность. Если проект работает на одном сервере без резервирования, обещать почти безупречную доступность рискованно. Для высоких целей нужны соответствующая архитектура, мониторинг, процессы и люди. Надежность покупается не только деньгами. Она покупается вниманием.
Что показывает история инцидентов?
Если за последние три месяца сервис уже несколько раз падал, сначала стоит понять причины. Возможно, SLO нужно вводить постепенно: сначала стабилизировать базовые вещи, затем повышать планку. Хороший SLO не рождается в таблице. Он появляется на стыке данных, опыта и здравого смысла.
SLO и инфраструктура: где VPS, а где выделенный сервер
SLO помогает принимать инфраструктурные решения без гадания. Например, проект стартует на VPS. На ранней стадии это логично: быстро, гибко, экономично. Нагрузка умеренная, команда проверяет гипотезы, пользователи только приходят. SLO может быть достаточно мягким, потому что цена простоя пока невысока. Со временем трафик растет. Появляются платные клиенты, интеграции, рекламные кампании, пиковые нагрузки. Ошибка в инфраструктуре уже стоит дороже. В этот момент бизнесу стоит пересмотреть SLO и понять, хватает ли текущей архитектуры. Иногда достаточно увеличить ресурсы VPS, оптимизировать приложение, добавить мониторинг и настроить бэкапы. Иногда разумнее перейти на выделенный сервер, разделить роли между несколькими узлами, вынести базу данных, добавить балансировку и резервирование. SLO здесь работает как компас. Если целевой уровень надежности не требует сложной отказоустойчивой схемы, не нужно строить космический корабль для поездки в соседний район. Но если от сервиса зависит выручка, договоры и доверие клиентов, экономия на инфраструктуре может оказаться дорогой.
Пример
У компании есть API, через который партнеры получают данные в реальном времени. Пока API обслуживает несколько клиентов, один VPS справляется. Но после подключения крупных партнеров любое падение начинает бить по SLA. Команда пересматривает SLO, добавляет резервирование, мониторинг latency, алерты по error budget и переносит критические компоненты на более предсказуемую инфраструктуру. Это не «апгрейд ради апгрейда». Это инфраструктурное решение, привязанное к бизнес-риску.
Почему мониторинг без SLO часто шумит
Многие команды начинают с мониторинга: ставят Prometheus, Grafana, Zabbix, Uptime Kuma или другой инструмент, настраивают десятки алертов и ждут спокойствия. Но вместо спокойствия получают шум. Алертит CPU. Алертит память. Алертит диск. Алертит latency. Алертит всё сразу. Проблема не в инструментах. Проблема в отсутствии приоритетов. SLO помогает отделить важное от второстепенного. Если метрика не влияет на пользовательский опыт и бизнес-цель, возможно, она не должна будить инженера ночью. Ее можно оставить на дашборде, но не превращать в тревогу. Например, кратковременный скачок CPU до 90% может быть нормальным во время фоновой задачи. Но рост ошибок на странице оплаты - совсем другой уровень риска. Хороший алерт должен отвечать на вопрос: «Если мы сейчас ничего не сделаем, нарушим ли мы SLO или быстро сожжем error budget?» Если ответ «нет», возможно, это не срочный инцидент, а обычный сигнал для плановой работы.
Как внедрить SLO без бюрократии
SLO не должен превращаться в тяжелый процесс с десятками документов. Начать можно спокойно и практично.
1. Выберите один критический пользовательский путь
Не нужно сразу покрывать всю систему. Возьмите то, что напрямую влияет на бизнес. Для интернет-магазина это может быть оформление заказа. Для SaaS - авторизация и работа основного API. Для медиа-проекта - доступность страниц и скорость загрузки. Для B2B-платформы - стабильность интеграций. Один хороший SLO лучше десяти формальных.
2. Определите SLI
Решите, какую метрику будете измерять. Например: доля успешных заказов; процент успешных API-запросов; p95 latency; доступность страницы; доля пользовательских сессий без критических ошибок. Главный критерий: метрика должна отражать реальный опыт пользователя.
3. Назначьте SLO
Выберите целевой уровень. Лучше начать с реалистичного значения, основанного на текущих данных. Если сервис исторически показывает 99,5%, не стоит сразу ставить 99,99%. Сначала нужно понять, что мешает подняться выше: архитектура, код, база данных, внешние зависимости, деплой, нехватка наблюдаемости.
4. Рассчитайте error budget
Определите, сколько ошибок допустимо за период. Обычно используют окно 7, 28 или 30 дней. Для разных сервисов окно может отличаться. Например, месячный период удобен для бизнес-отчетности. Более короткий период быстрее показывает проблемы. Rolling window помогает видеть состояние сервиса постоянно, а не только в конце календарного месяца.
5. Договоритесь о правилах
Error budget работает только тогда, когда заранее понятны последствия.
Например
• если потрачено меньше 50% бюджета, релизы идут по обычному графику
• если потрачено 50-80%, новые изменения проходят осторожнее
• если потрачено больше 80%, команда фокусируется на надежности
если бюджет исчерпан, рискованные релизы замораживаются до устранения причин. Это не наказание. Это ремень безопасности.
6. Пересматривайте SLO регулярно
SLO не высечен в камне. Бизнес меняется, нагрузка растет, архитектура развивается, появляются новые клиенты и новые риски. Раз в квартал полезно спрашивать: этот SLO всё еще отражает реальность? Пользователи довольны? Команда справляется? SLA не слишком агрессивный? Error budget помогает принимать решения? Так надежность остается живым инструментом, а не забытым документом.
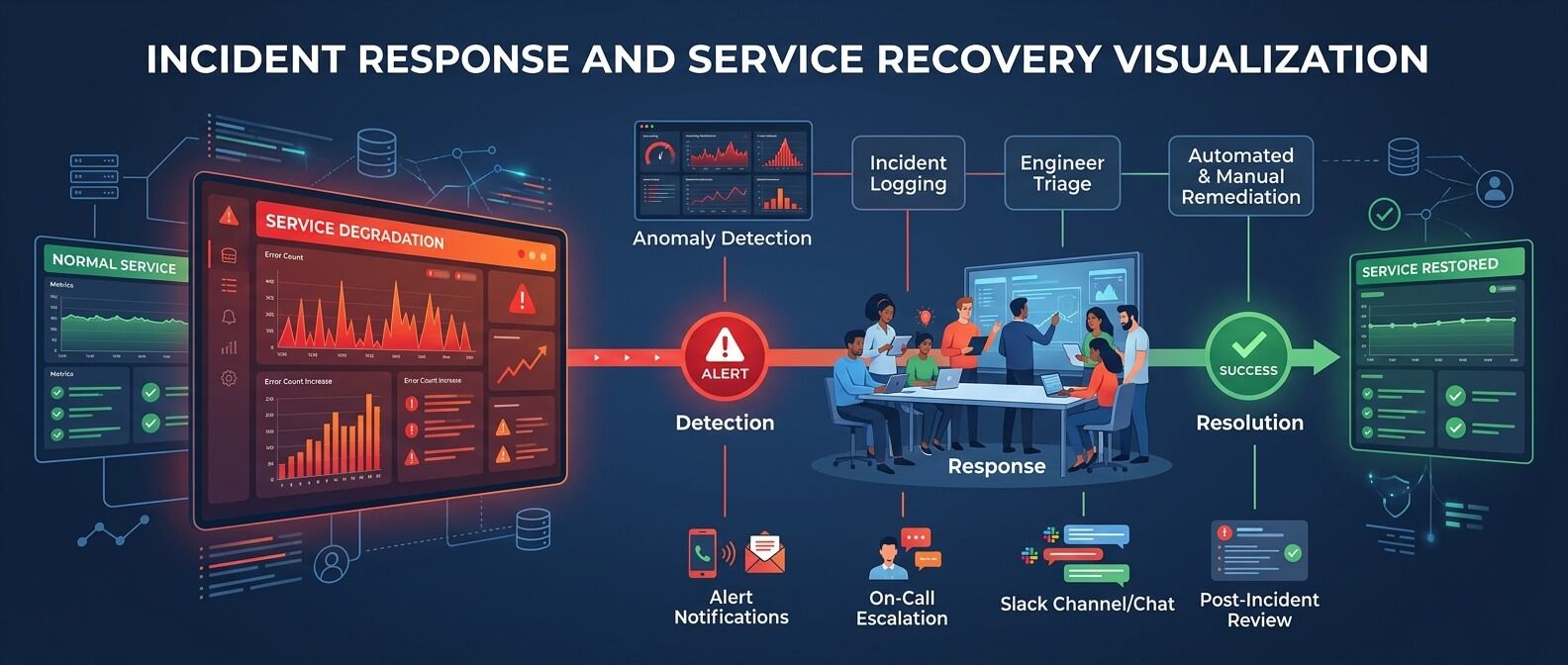
Частые ошибки при работе с SLO, SLA и error budget
Даже хорошая идея может не сработать, если внедрять ее формально. Вот несколько ловушек, которые встречаются особенно часто.
Ошибка 1. Измерять сервер, а не пользователя
Ping проходит, сервер доступен, CPU в норме - но пользователь не может оплатить заказ. Такое бывает чаще, чем кажется. Надежность нужно измерять снаружи внутрь: от пользовательского пути к инфраструктуре, а не наоборот.
Ошибка 2. Делать одинаковый SLO для всего
Не все части системы одинаково важны. Админка, главная страница, API оплаты и фоновый импорт данных имеют разную цену отказа. Одинаковый SLO либо перегружает команду, либо недостаточно защищает критичные зоны.
Ошибка 3. Обещать в SLA больше, чем можно обеспечить
Красивое SLA может помочь продажам, но только до первого серьезного сбоя. Если обязательства не подкреплены архитектурой и процессами, бизнес берет на себя лишний риск. Лучше обещать осторожно и выполнять стабильно, чем обещать громко и регулярно объясняться.
Ошибка 4. Не связывать error budget с действиями
Если бюджет ошибок просто отображается на дашборде, но ни на что не влияет, он быстро становится декоративной метрикой. Нужны правила: что команда делает при нормальном расходе, при ускоренном burn rate, при угрозе нарушения SLO и при полном исчерпании бюджета.
Ошибка 5. Игнорировать внешние зависимости
Платежные системы, DNS, CDN, облачные сервисы, сторонние API - всё это может влиять на ваш SLO. Пользователю обычно не важно, кто именно виноват. Он взаимодействует с вашим продуктом. Поэтому внешние зависимости нужно учитывать в архитектуре, мониторинге и коммуникации с клиентами.
Как SLO помогает считать деньги
Надежность часто воспринимают как техническую инвестицию. На деле это еще и финансовая модель.
SLO помогает ответить на вопросы, которые волнуют бизнес
• сколько стоит простой
• где инфраструктура недоинвестирована
• где надежность избыточна
• какие сервисы нужно резервировать в первую очередь
• когда стоит переходить с VPS на выделенный сервер
• какие инциденты действительно критичны
• какие улучшения дадут максимальный эффект.
Например, команда видит, что 70% пользовательских жалоб связаны не с полной недоступностью сайта, а с медленной оплатой в пиковые часы. Значит, покупка более мощного сервера может быть полезной, но только если узкое место действительно в ресурсах. Возможно, проблема в базе данных, очередях, стороннем платежном API или неудачной логике приложения. SLO заставляет искать связь между симптомом и бизнес-результатом.
Еще пример
Компания хочет повысить доступность сервиса с 99,9% до 99,99%. На первый взгляд разница небольшая. Но для этого может понадобиться резервная инфраструктура, автоматическое переключение, дополнительный мониторинг, круглосуточное дежурство и регулярные тесты отказоустойчивости. Если потенциальные потери от простоя ниже стоимости этих мер, бизнес может осознанно остаться на 99,9%. Это не слабость. Это зрелое управление риском.
Цена дополнительных «девяток»
Рост SLO с 99,9% до 99,99% часто требует резервов, дежурств и тестов отказов — считайте ROI.
SLO как основа для разговоров с клиентами
Клиенты редко хотят слышать технические подробности инцидента. Им важны понятные ответы: что произошло; как это повлияло на сервис; сколько длилось; что сделано для предотвращения повторения; выполняются ли обязательства. Когда у компании есть SLO и SLA, коммуникация становится спокойнее. Есть факты, метрики, границы ответственности и понятные действия. Например, вместо размытого «у нас были временные технические трудности» можно сказать: «Сервис авторизации работал с повышенной долей ошибок в течение 12 минут. Причина устранена, текущий уровень доступности за расчетный период остается в рамках SLA. Мы дополнительно обновили алерты, чтобы быстрее обнаруживать похожую деградацию». Такой ответ звучит увереннее. Он показывает, что компания управляет ситуацией, а не просто реагирует на хаос.
Практический пример: интернет-магазин на VPS
Представим интернет-магазин, который работает на VPS. Трафик стабильный, но во время акций нагрузка резко растет. Иногда пользователи жалуются, что корзина открывается медленно, а оплата не всегда проходит с первого раза. Команда решает не гадать, а ввести SLO.
Критический путь: оформление заказа
SLI
доля успешных переходов от корзины к оплате; доля успешных ответов checkout API; p95 времени ответа checkout API; количество ошибок 5xx.
SLO
99,5% операций оформления заказа должны завершаться успешно за 30 дней; 95% запросов checkout API должны отвечать быстрее 500 мс.
Error budget
0,5% неуспешных операций за месяц. После этого команда видит, что во время акций error budget сгорает слишком быстро. Причина не в общем аптайме VPS, а в перегрузке базы данных и очереди фоновых задач. Решение: оптимизация запросов, вынос тяжелых задач, настройка кэша, увеличение ресурсов и подготовка отдельного плана на периоды пикового трафика. Позже, когда объем заказов растет, бизнес рассматривает переход на выделенный сервер или более распределенную архитектуру. Теперь это решение основано не на ощущении «нам тесно», а на данных: текущая инфраструктура не позволяет стабильно держать нужный SLO во время коммерчески важных периодов.
Магазин на VPS: критический путь
SLO на checkout, не на «средний аптайм сервера».
Error budget 0,5% — сигнал пересмотреть БД и пики на акциях.
Практический пример: B2B API с внешним SLA
Другой сценарий - компания предоставляет API для партнеров. Партнеры используют его в своих продуктах, поэтому недоступность API влияет уже не только на одну компанию, а на цепочку клиентов. Здесь внешний SLA особенно важен. Команда может задать внутренний SLO: 99,95% успешных API-запросов за 30 дней; p95 latency ниже 300 мс; не более 0,05% ошибок 5xx. А клиентам обещать SLA 99,9%. Внутренний запас помогает обнаруживать проблемы раньше. Если error budget начинает быстро сгорать, команда временно ограничивает рискованные релизы, усиливает мониторинг, анализирует медленные запросы, проверяет сетевые задержки и состояние инфраструктуры.
Для бизнеса это дает сразу несколько преимуществ
• меньше риск нарушить договор
• проще объяснять надежность крупным клиентам
• понятнее, зачем нужны инвестиции в инфраструктуру
• легче расставлять приоритеты в roadmap.
Надежность перестает быть абстрактным техническим качеством. Она становится частью продукта.

B2B API: SLO выше SLA
Внутренний запас для раннего обнаружения проблем до нарушения договора.
Что должно быть в хорошей политике error budget
Error budget полезен только тогда, когда вокруг него есть правила. Не обязательно сложные. Главное - понятные. Хорошая политика отвечает на несколько вопросов.
Кто отвечает за SLO?
У каждого SLO должен быть владелец. Это может быть команда продукта, платформенная команда, SRE, DevOps или инженерная группа. Главное, чтобы ответственность не растворялась в воздухе. Если «отвечают все», часто не отвечает никто.
Что происходит при быстром расходе бюджета?
Например
• проводится разбор причин
• усиливается мониторинг
• релизы проходят через дополнительную проверку
• часть команды переключается на надежность
• рискованные изменения временно откладываются.
Что происходит при исчерпании бюджета?
Здесь нужны более жесткие действия: заморозка нерелевантных релизов; приоритет исправлений над новыми функциями; обязательный postmortem; пересмотр архитектурных решений; обновление тестов и алертов.
Как возвращаемся к нормальному режиму?
Важно не только остановить релизы, но и определить, когда можно снова ускоряться. Например, после устранения корневых причин, восстановления error budget и прохождения стабильного периода. Такая политика убирает личные споры. Команда заранее знает правила игры.
Как KingServers-подход ложится на надежность
Для проектов на VPS/VDS, выделенных серверах и гибридной инфраструктуре SLO особенно полезны. Они помогают понять, где достаточно простой конфигурации, а где нужна более серьезная архитектура. Если проект только стартует, важны скорость запуска, понятная стоимость и возможность быстро масштабироваться. Если сервис уже влияет на выручку клиентов, на первый план выходят мониторинг, резервирование, защита от DDoS, предсказуемая производительность и грамотная настройка. Инфраструктура должна расти вместе с требованиями бизнеса. Когда есть SLO, разговор с провайдером тоже становится предметнее. Вместо «нам нужен надежный сервер» можно сформулировать задачу точнее:
какой трафик ожидается;
• какие компоненты критичны
• какие периоды нагрузки самые важные
• какая доступность нужна
• насколько быстро нужно восстановление
• какие риски недопустимы.
Так проще выбрать между VPS, выделенным сервером, кастомной конфигурацией, дополнительной защитой и резервной схемой. Надежность любит конкретику. Чем точнее цель, тем проще подобрать инфраструктуру под нее.

Мини-чек-лист для старта
Если хочется внедрить SLO без лишней сложности, начните с короткого чек-листа. Выберите один сервис или пользовательский путь, который важен для бизнеса. Определите, что для пользователя значит «работает хорошо». Подберите SLI, который это измеряет. Назначьте реалистичный SLO. Посчитайте error budget. Настройте мониторинг и алерты по скорости расхода бюджета. Договоритесь, что команда делает при риске нарушения SLO. Раз в месяц или квартал пересматривайте цели. Даже такой простой подход уже меняет культуру. Команда начинает обсуждать надежность не в момент аварии, а заранее.
Итог: надежность должна работать на бизнес, а не жить отдельно
SLO, SLA и error budget нужны не для красивых отчетов. Они помогают связать инженерные решения с бизнес-реальностью. SLO показывает, какой уровень надежности нужен пользователям. SLA фиксирует обещания перед клиентами. Error budget помогает балансировать скорость разработки и стабильность. Вместе они превращают надежность из туманного пожелания в управляемую систему. Главное - не начинать с максимальных цифр. Начните с важного пользовательского пути, честных метрик и понятных правил. Посмотрите, где сервис действительно теряет качество, где инфраструктура уже на пределе, а где можно обойтись без лишней сложности. Надежность - это не гонка за идеальными 100%. Это умение держать нужный уровень качества там, где он влияет на клиентов, деньги и доверие. А когда инфраструктура, команда и бизнес смотрят на одни и те же показатели, решения становятся спокойнее, точнее и сильнее.




