



















Инфраструктура редко ломается из-за одного большого неправильного решения. Чаще она становится тяжёлой постепенно: команда сама поднимает мониторинг, сама собирает Kubernetes, сама пишет backup-скрипты, сама поддерживает CI/CD, сама разбирается с сетью, безопасностью, storage и биллингом. В какой-то момент инженеры уже не развивают продукт, а чинят платформу, которую никто не планировал превращать в отдельный бизнес.
С другой стороны, слепо покупать всё у провайдера тоже опасно. Managed-сервисы экономят время, но добавляют зависимость, ограничения, непредсказуемую стоимость и иногда слишком узкий коридор возможностей. Поэтому вопрос Build vs Buy в инфраструктуре — не философия и не спор «своё против чужого». Это нормальная бизнес-дисциплина: понять, где контроль даёт преимущество, а где он просто съедает время команды.
Оглавление
- Что означает Build vs Buy в инфраструктуре
- Почему этот вопрос стал особенно важным
- Главный принцип: строить стоит только то, что даёт преимущество
- Что обычно стоит держать внутри
- 1. Архитектурные решения и ownership
- 2. Критичные данные и политика доступа
- 3. Секреты, ключи и identity
- 4. Product-specific automation
- 5. Инфраструктурные знания о собственном продукте
- Что чаще разумнее отдавать провайдеру
- 1. Физическая инфраструктура и дата-центр
- 2. DDoS mitigation и edge protection
- 3. Commodity-сервисы без уникальной ценности
- 4. Managed services для нехватки экспертизы
- 5. Compliance tooling и audit-поддержка
- Где решение зависит от контекста
- Kubernetes
- Базы данных
- Observability
- CI/CD
- Storage
- Матрица принятия решения
- Пример 1. SaaS-компания на стадии роста
- Пример 2. Gaming-платформа
- Пример 3. Fintech или regulated business
- Скрытые расходы Build
- Скрытые расходы Buy
- Как избежать крайностей
- Роль провайдера: не только продавать ресурсы
- Как пересматривать Build vs Buy со временем
- Практический checklist перед решением
- Итог
Хорошая инфраструктурная стратегия не пытается построить всё внутри и не отдаёт всё наружу. Она разделяет задачи: что является ядром бизнеса, что требует уникальной экспертизы, что должно быть под прямым контролем, а что можно спокойно доверить провайдеру.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Что означает Build vs Buy в инфраструктуре
Build — значит команда сама проектирует, разворачивает, поддерживает и развивает инфраструктурный компонент. Например, самостоятельно управляет базой данных, Kubernetes-кластером, системой логирования, storage-кластером, CI/CD-платформой или внутренним developer portal.
Buy — значит компания покупает готовый сервис или отдаёт часть ответственности провайдеру. Это может быть managed database, managed Kubernetes, CDN, DDoS protection, backup service, monitoring platform, hosted CI, cloud firewall, object storage или bare metal provider с поддержкой hardware и сети.
На практике между Build и Buy есть много промежуточных вариантов.
Можно купить выделенные серверы, но самостоятельно управлять ОС и приложениями. Можно использовать managed Kubernetes, но держать observability внутри. Можно отдать DDoS mitigation провайдеру, но управлять network policies самостоятельно. Можно купить SaaS-мониторинг, но хранить критичные security logs в собственной системе.
То есть вопрос звучит не «делаем сами или покупаем?», а точнее: «какую часть ответственности мы оставляем у себя, а какую передаём наружу?»

Почему этот вопрос стал особенно важным
Раньше инфраструктура часто росла естественным путём. Появилась база — подняли сервер. Нужны логи — поставили ELK. Нужен Kubernetes — собрали кластер. Нужны backups — написали скрипты. Каждый шаг казался разумным.
Проблема проявляется позже, когда этих решений становится много.
Команда внезапно отвечает за:
- обновления и patch management;
- high availability;
- backups и restore tests;
- безопасность и доступы;
- monitoring и alerting;
- capacity planning;
- incident response;
- compliance;
- оптимизацию расходов;
- документацию и обучение новых инженеров.
И всё это нужно делать параллельно с разработкой продукта.
В 2026 году этот баланс стал ещё заметнее. Инфраструктура дорожает, AI-нагрузки увеличивают спрос на compute, cloud spend требует постоянного контроля, а требования к безопасности и суверенности данных становятся строже. В такой ситуации решения Build vs Buy напрямую влияют не только на IT, но и на скорость бизнеса.
Главный принцип: строить стоит только то, что даёт преимущество
Самый простой фильтр звучит так: если компонент не отличает ваш бизнес от конкурентов, его не обязательно строить самостоятельно.
Например, если компания продаёт SaaS для управления заказами, собственная система мониторинга редко является её конкурентным преимуществом. Пользователь не платит за то, что команда сама поддерживает Prometheus, Grafana, alert routing и long-term metrics storage. Он платит за стабильный продукт, понятный интерфейс и работающие бизнес-функции.
Но если компания строит low-latency trading platform, network stack, latency monitoring и контроль над железом могут быть частью преимущества. Здесь «сделать самим» может быть оправдано.
Хороший вопрос для любого инфраструктурного решения:
Если мы построим это внутри, станет ли продукт заметно лучше для клиента или бизнес заметно сильнее?
Если ответ расплывчатый, возможно, лучше купить сервис и освободить команду для более важных задач.
Что обычно стоит держать внутри
Нет универсального списка, который подходит всем. Но есть категории, где внутренний контроль часто оправдан.
1. Архитектурные решения и ownership
Даже если компания активно использует провайдеров, ответственность за архитектуру нельзя полностью отдать наружу.
Провайдер может предоставить серверы, облако, database service, CDN или защиту от атак. Но он не знает ваш продукт так, как его знает ваша команда. Он не принимает решения о trade-offs между latency, стоимостью, риском, compliance и скоростью разработки.
Внутри стоит держать:
- целевую архитектуру;
- правила выбора технологий;
- стандарты безопасности;
- network design;
- data ownership;
- disaster recovery strategy;
- правила доступа;
- SLO и error budgets;
- подход к observability;
- критерии выбора провайдеров.
Мини-пример: провайдер может предложить managed database. Но решение, можно ли хранить данные в конкретном регионе, какой RPO допустим, как выполнять миграции и кто имеет доступ к production backup, должно оставаться у бизнеса.
Покупать можно сервис. Нельзя покупать собственное понимание системы.

2. Критичные данные и политика доступа
Данные — это сердце инфраструктуры. Даже если физически они хранятся у провайдера, правила владения и доступа должны быть внутренними.
Важно самим определить:
- какие данные являются критичными;
- где они могут храниться;
- кто имеет доступ;
- как работает encryption;
- как выполняются backups;
- как проверяется restore;
- сколько времени хранятся логи;
- кто может удалять данные;
- как выполняются требования клиентов и регуляторов.
Провайдер может дать инструменты. Но политика должна быть вашей.
Аналогия простая: банк может арендовать помещение для архива, но не должен позволять арендодателю решать, кто имеет доступ к сейфам.
3. Секреты, ключи и identity
Identity and access management — плохое место для хаоса. Когда доступы разрастаются без правил, инфраструктура становится похожа на офис, где ключи от всех комнат лежат в общей кружке на кухне.
Внутри стоит держать контроль над:
- root/admin доступом;
- privileged accounts;
- service accounts;
- secrets management;
- rotation policies;
- MFA;
- break-glass доступом;
- audit logs;
- принципом least privilege.
Можно использовать внешний identity provider или managed secrets store. Но модель доступа, роли, процедуры выдачи и отзыва прав должны быть понятны внутри компании.
Особенно это важно в hybrid infrastructure, где часть систем работает в облаке, часть — на выделенных серверах, часть — в SaaS-инструментах.
4. Product-specific automation
Автоматизация, которая напрямую отражает бизнес-логику продукта, часто должна оставаться внутри.
Например:
- provisioning customer environments;
- создание серверов под клиента;
- управление тарифными лимитами;
- routing по tenant-ам;
- deployment workflows для продукта;
- custom billing integration;
- внутренние self-service инструменты для support или engineering;
- автоматизация rollback под специфику приложения.
Провайдер может дать API. Но сценарии, которые делают ваш продукт быстрым и удобным, лучше проектировать самостоятельно.
Если клиент нажимает кнопку «создать сервер», а за ней стоит цепочка из inventory, billing, network allocation, access setup и monitoring, это уже не просто инфраструктура. Это часть пользовательского опыта.
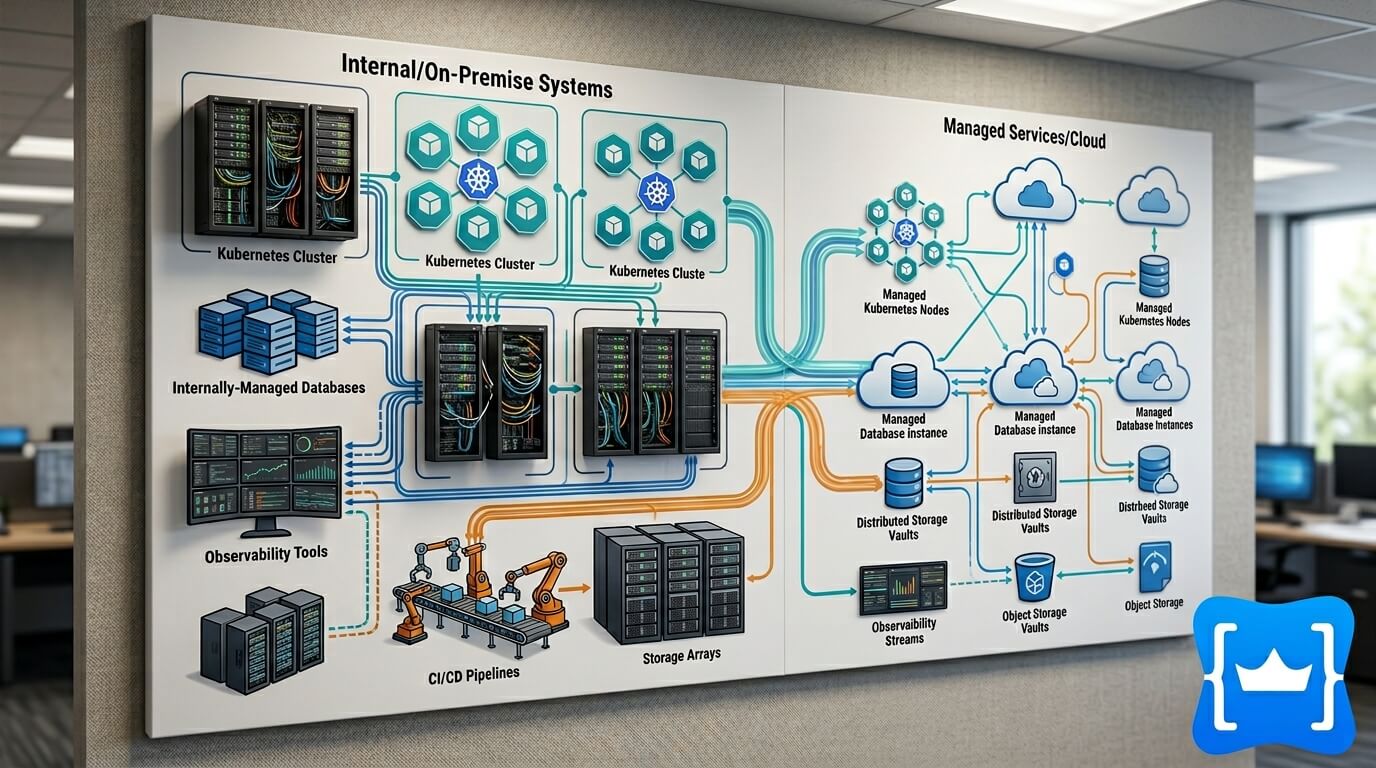
5. Инфраструктурные знания о собственном продукте
Даже при максимальном Buy команда должна понимать, как работает её система.
Опасная ситуация: «мы не знаем, почему сервис упал, потому что это managed». Managed не означает magical. Провайдер отвечает за свою часть, но приложение, нагрузка, схема данных, запросы, пользовательские сценарии и бизнес-риски остаются у вас.
Внутри должны быть:
- runbooks;
- architecture diagrams;
- incident history;
- postmortems;
- dependency map;
- capacity assumptions;
- ownership по сервисам;
- понимание critical path.
Это не обязательно означает держать большую infrastructure team. Но знание должно быть доступным, а не жить только в голове провайдера или одного senior engineer.
Что чаще разумнее отдавать провайдеру
Теперь обратная сторона. Есть области, где самостоятельная реализация часто выглядит героически, но приносит мало пользы бизнесу.
1. Физическая инфраструктура и дата-центр
Для большинства компаний строить собственный дата-центр не имеет смысла. Электропитание, охлаждение, физическая безопасность, каналы связи, fire suppression, hardware replacement, remote hands — всё это отдельная профессия.
Гораздо разумнее использовать провайдера, который уже умеет управлять физическим слоем.
Это может быть:
- dedicated server provider;
- colocation;
- public cloud;
- bare metal cloud;
- managed hosting;
- regional infrastructure provider.
Даже если компания хочет максимальный контроль над ОС и приложениями, ей не обязательно владеть зданием, дизель-генераторами и запасом дисков на складе.
Build здесь оправдан только для очень крупных игроков, для которых инфраструктура сама является бизнесом или стратегическим активом огромного масштаба.

2. DDoS mitigation и edge protection
Защита от DDoS — типичный пример, где Buy часто сильнее Build.
Чтобы эффективно отражать крупные атаки, нужны:
- большая сеть;
- фильтрация на edge;
- опыт анализа атак;
- capacity с запасом;
- автоматические правила;
- мониторинг трафика;
- команда, которая видела много разных сценариев.
Маленькой или средней компании сложно построить это на таком же уровне. Можно настроить firewall и rate limiting, но это не заменит полноценную upstream-защиту.
Хороший подход: базовые application-level меры держать внутри, а объёмную сетевую защиту отдавать провайдеру.
3. Commodity-сервисы без уникальной ценности
Если сервис нужен всем и не является вашей специализацией, часто лучше купить готовое решение.
Примеры:
- email delivery;
- DNS hosting;
- object storage;
- basic monitoring SaaS;
- uptime checks;
- status page;
- error tracking;
- vulnerability scanning;
- managed certificates;
- hosted CI для небольших команд.
Конечно, бывают исключения. Но если команда тратит недели на поддержку внутреннего аналога стандартного SaaS, стоит честно спросить: зачем?
Иногда ответ есть: compliance, стоимость на масштабе, особые требования. Если ответа нет, это кандидат на Buy.
4. Managed services для нехватки экспертизы
Самостоятельно управлять PostgreSQL, Kafka, Elasticsearch, Kubernetes или ClickHouse можно. Вопрос — есть ли команда, которая действительно умеет это делать 24/7.
Не «мы один раз подняли кластер», а именно умеет:
- обновлять без downtime;
- восстанавливать из backups;
- настраивать replication;
- расследовать performance issues;
- защищать от потери данных;
- планировать capacity;
- реагировать ночью;
- документировать runbooks;
- обучать новых инженеров.
Если такой экспертизы нет, managed service может быть дешевле, даже если счёт провайдера выглядит выше. Потому что альтернатива — скрытая стоимость ошибок, простоев и времени senior engineers.

5. Compliance tooling и audit-поддержка
Многие compliance-задачи лучше не собирать с нуля.
Например:
- centralized logging;
- immutable audit trails;
- policy checks;
- vulnerability management;
- asset inventory;
- access reviews;
- backup reporting;
- evidence collection.
Провайдеры и специализированные сервисы часто уже имеют готовые механизмы, отчёты и интеграции. Это не освобождает компанию от ответственности, но снижает ручную работу.
Если security-команда собирает evidence вручную перед каждым аудитом, это хороший сигнал: часть процесса пора покупать или автоматизировать на готовой платформе.
Где решение зависит от контекста
Есть компоненты, по которым нельзя дать универсальный ответ. Они могут быть и Build, и Buy — зависит от масштаба, требований и команды.
Kubernetes
Managed Kubernetes часто хорош для старта. Он снимает часть забот о control plane, обновлениях и интеграции с облачной инфраструктурой.
Но если компания управляет большим количеством bare metal nodes, имеет особые network requirements, хочет точный контроль над CNI, storage и upgrade policy, self-managed Kubernetes может быть оправдан.
Вопрос не в том, «настоящий» ли Kubernetes. Вопрос в том, кто отвечает за операционную сложность.
Если команда не готова разбирать etcd, networking, node pressure, admission controllers и upgrade failures, лучше не романтизировать self-managed подход.

Базы данных
Managed database экономит время и снижает операционные риски. Это сильный выбор для многих команд.
Но self-managed database может быть разумнее, если:
- нужна особая конфигурация;
- важна стоимость на большом масштабе;
- workload очень специфичный;
- есть сильная DBA/SRE экспертиза;
- нужны кастомные extensions;
- требуется физическая изоляция;
- есть ограничения по data residency;
- cloud egress или IOPS делают managed-вариант слишком дорогим.
Для небольшой команды managed PostgreSQL может быть подарком. Для зрелой платформы с огромной постоянной нагрузкой self-managed кластер на выделенных серверах может быть экономически и технически оправдан.

Observability
На ранней стадии лучше купить готовый monitoring и logging stack. Команда получает dashboards, alerts, tracing, retention и integrations без долгой настройки.
Но на большом масштабе observability может стать дорогой статьёй расходов. Особенно если логи шумные, cardinality высокая, а retention длительный.
Тогда появляются гибридные варианты:
- metrics в managed-сервисе;
- security logs в собственном хранилище;
- traces с sampling;
- горячие логи в SaaS, архив — в object storage;
- критичные dashboards внутри, внешний сервис — для alerting.
Главное — не доводить до ситуации, где monitoring стоит почти как production-инфраструктура, но никто не понимает, какие данные действительно нужны.
CI/CD
Hosted CI удобен, пока workload умеренный. Не нужно поддерживать runners, обновлять образы, следить за очередями и безопасностью.
Но если builds тяжёлые, частые и предсказуемые, self-hosted runners на выделенных серверах могут быть выгоднее. Особенно для больших monorepo, container builds, test matrices и workloads с высоким потреблением CPU.
Компромиссный вариант — держать control plane у провайдера, а runners запускать на своей инфраструктуре.
Так команда сохраняет удобный интерфейс и получает контроль над compute.
Storage
Object storage у провайдера часто идеален для backups, static files, archives и интеграции с другими сервисами.
Но если бизнес хранит огромные объёмы горячих данных, активно читает и пишет, имеет предсказуемый workload и сильные требования к стоимости, собственный storage-кластер или dedicated storage servers могут быть интересны.
Здесь важно честно считать всё: диски, репликацию, замену hardware, мониторинг, rebuild time, backup, сеть, инженеров и риски потери данных.
Storage кажется простым ровно до первого серьёзного восстановления.
Матрица принятия решения
Чтобы не спорить на уровне вкусов, полезно использовать простую матрицу.
Оцените каждый компонент по нескольким параметрам от 1 до 5.
Критерий
Вопрос
Business differentiation
Даёт ли компонент конкурентное преимущество?
Control requirement
Нужен ли глубокий контроль над настройками и поведением?
Security/compliance
Есть ли строгие требования к данным, доступу, аудиту?
Operational expertise
Есть ли команда, которая умеет поддерживать это 24/7?
Cost predictability
Насколько важна фиксированная и понятная стоимость?
Scale
Достигла ли нагрузка масштаба, где self-managed выгоден?
Time to market
Насколько критична скорость запуска?
Lock-in risk
Насколько опасна зависимость от одного провайдера?
Failure impact
Что будет, если компонент сломается?
Если компонент сильно влияет на конкурентное преимущество, безопасность, контроль и стоимость на масштабе — его стоит рассмотреть для Build или хотя бы для более управляемой модели.
Если компонент стандартный, не уникальный, требует круглосуточной экспертизы и не отличает продукт — скорее Buy.
Пример 1. SaaS-компания на стадии роста
Представим SaaS-платформу, которая выросла из стартапа в стабильный продукт. Команда обслуживает тысячи клиентов, нагрузка стала предсказуемой, cloud bill растёт, а инженеры всё чаще занимаются инфраструктурой вместо продуктовых задач.
Разумная стратегия может быть такой:
- оставить managed database для core transactional данных;
- вынести heavy background jobs на выделенные серверы;
- использовать cloud object storage для архивов;
- купить DDoS protection у провайдера;
- держать product provisioning logic внутри;
- оставить hosted CI, но добавить self-hosted runners для тяжёлых builds;
- использовать SaaS observability, но снизить объём логов и вынести cold storage отдельно.
Это не чистый Build и не чистый Buy. Это взрослая смесь.
Компания покупает то, где провайдер сильнее, и строит то, что связано с продуктовой логикой и экономикой на масштабе.
Пример 2. Gaming-платформа
Игровая инфраструктура часто чувствительна к latency, network jitter и стабильной производительности.
Здесь выделенные серверы могут быть очень сильным выбором для game servers, matchmaking nodes, voice infrastructure или региональных backend-компонентов.
Но при этом нет смысла самостоятельно строить всё подряд.
Можно:
- держать game servers на dedicated infrastructure;
- использовать managed DNS;
- купить DDoS protection;
- хранить analytics в облачном data warehouse;
- использовать CDN для статических assets;
- держать account management API в облаке или гибридной среде.
Так бизнес получает контроль над критичной latency-частью, но не тратит силы на commodity-сервисы.
Пример 3. Fintech или regulated business
В regulated-средах Build vs Buy часто упирается не только в стоимость, но и в ответственность.
Компания может использовать провайдеров, но ей нужно доказать контроль:
- где хранятся данные;
- кто имеет доступ;
- как шифруются backups;
- как проверяется restore;
- как логируются действия администраторов;
- как выполняется segregation of duties;
- что происходит при инциденте.
Здесь полезна модель, где:
- identity, access policy и audit ownership остаются внутри;
- инфраструктура размещается у надёжного провайдера;
- security tooling частично покупается;
- критичные данные хранятся в строго выбранных регионах;
- disaster recovery регулярно тестируется;
- compliance evidence собирается автоматически.
Провайдер помогает выполнить требования, но не заменяет внутреннюю ответственность.
Скрытые расходы Build
Когда команда выбирает Build, важно считать не только серверы и лицензии.
Есть скрытые расходы:
- время инженеров;
- найм и обучение;
- on-call;
- документация;
- обновления;
- security patches;
- incident response;
- backup testing;
- migration work;
- technical debt;
- bus factor;
- стоимость ошибок.
Самостоятельно поднятый сервис может казаться бесплатным, потому что не приходит отдельный invoice. Но если два senior engineers каждую неделю тратят на него по несколько часов, счёт всё равно есть. Просто он спрятан в зарплатах и упущенной продуктовой работе.
Build оправдан, когда эта стоимость возвращается контролем, экономией на масштабе или конкурентным преимуществом.
Скрытые расходы Buy
У Buy тоже есть своя цена, кроме monthly bill.
Нужно учитывать:
- vendor lock-in;
- ограничения API;
- рост стоимости при масштабировании;
- egress fees;
- лимиты тарифов;
- зависимость от roadmap провайдера;
- сложности миграции;
- shared responsibility gaps;
- compliance ограничения;
- риск изменения условий сервиса.
Покупка сервиса не должна превращаться в отказ от управления. Нужно понимать SLA, exit strategy, data export, backup options, support process и финансовую модель.
Иначе Buy сначала выглядит удобным, а через два года становится дорогой комнатой без запасного выхода.
Как избежать крайностей
В инфраструктуре опасны две крайности.
Первая: «мы всё сделаем сами». Обычно она приводит к перегруженной команде, внутренним платформам без владельца, устаревшим версиям и постоянным инцидентам.
Вторая: «мы всё купим». Она может привести к cloud bill, который никто не понимает, lock-in, зависимости от десятка SaaS-инструментов и потере инженерного контроля.
Зрелый подход находится посередине.
Для каждого компонента нужно ответить:
- почему мы держим это внутри;
- почему мы отдаём это провайдеру;
- кто владелец решения;
- как выглядит fallback;
- как мы измеряем стоимость;
- что будет при росте нагрузки;
- как выйти из решения, если оно перестанет подходить.
Если на эти вопросы нет ответов, решение ещё не принято. Оно просто случилось.
Роль провайдера: не только продавать ресурсы
Хороший инфраструктурный провайдер — это не просто место, где арендуют сервер или включают сервис.
Он помогает закрыть те слои, которые бизнесу невыгодно строить самому:
- физическое размещение;
- сеть;
- hardware replacement;
- базовую доступность;
- DDoS protection;
- bandwidth;
- remote hands;
- географию;
- predictable pricing;
- поддержку.
Для компании это способ сосредоточиться на продукте, не теряя контроль над важными техническими решениями.
Особенно ценна модель, где провайдер даёт надёжный фундамент, а команда строит сверху свою платформу: приложения, данные, автоматизацию, безопасность и продуктовую логику.
Как пересматривать Build vs Buy со временем
Решение, правильное сегодня, может устареть через год.
На ранней стадии Buy почти всегда помогает быстрее двигаться. На зрелой стадии часть Buy может стать слишком дорогой или ограничивающей. И наоборот: self-managed решение, которое когда-то было выгодным, может превратиться в технический долг.
Поэтому стоит регулярно проводить infrastructure review.
Например, раз в квартал или раз в полгода проверять:
- какие сервисы стали дорогими;
- какие компоненты требуют слишком много ручной поддержки;
- где вырос риск lock-in;
- какие workloads стали стабильными;
- какие managed services больше не дают ценности;
- какие self-managed системы пора отдать провайдеру;
- где появились новые compliance требования;
- какие компоненты стали критичнее для бизнеса.
Инфраструктура — живой организм. Её нужно не только строить, но и периодически приводить в форму.
Практический checklist перед решением
Перед тем как строить новый инфраструктурный компонент внутри, задайте команде несколько прямых вопросов.
- Это часть нашего конкурентного преимущества?
- Есть ли у нас экспертиза поддерживать это ночью, в выходные и во время инцидента?
- Сколько будет стоить не только запуск, но и три года эксплуатации?
- Что произойдёт, если главный эксперт по этой системе уйдёт?
- Есть ли готовый сервис, который закрывает 80% задачи?
- Что мы потеряем, если купим сервис у провайдера?
- Как мы выйдем из этого решения при необходимости?
- Какие данные и доступы окажутся у провайдера?
- Как это повлияет на compliance?
- Как мы поймём, что решение перестало быть выгодным?
Если после этих вопросов Build всё ещё выглядит разумным — значит, решение становится крепче. Если нет, лучше купить готовый сервис и не превращать инфраструктуру в музей внутренних проектов.
Итог
Build vs Buy в инфраструктуре — это не выбор между независимостью и удобством. Это выбор правильного уровня ответственности.
Внутри стоит держать архитектурное мышление, данные, доступы, продуктовую автоматизацию, security ownership и понимание critical path. Провайдеру разумно отдавать физический слой, commodity-сервисы, DDoS mitigation, часть managed platforms и задачи, где внешняя экспертиза сильнее внутренней.
Build нужен там, где контроль создаёт реальную ценность: снижает стоимость на масштабе, улучшает продукт, помогает выполнить compliance или даёт техническое преимущество. Buy нужен там, где готовый сервис экономит время, снижает операционный риск и позволяет инженерам заниматься тем, что двигает бизнес.
Самая сильная инфраструктура обычно не полностью своя и не полностью купленная. Она осознанно собрана из разных слоёв: где-то выделенные серверы, где-то облако, где-то managed services, где-то внутренняя платформа. Главное — понимать, зачем каждый слой существует и кто за него отвечает.
Когда этот баланс найден, инфраструктура перестаёт быть вечным источником споров. Она становится рабочим инструментом: предсказуемым, управляемым и достаточно гибким, чтобы поддерживать рост бизнеса без лишнего героизма.




