



















Оглавление
Executive summary
pgvector превращает PostgreSQL в полноценное хранилище векторов внутри обычной реляционной базы: с JOIN, ACL, транзакциями, WAL, репликацией и восстановлением на момент времени. Это особенно хорошо ложится на RAG, где векторный индекс нужен не сам по себе, а рядом с метаданными документов, tenant-фильтрами, версиями эмбеддингов и привычной эксплуатацией PostgreSQL. По состоянию на 17 апреля 2026 года актуальные документация и changelog pgvector описывают ветку 0.8.2; расширение поддерживает PostgreSQL 13+, но сами поддерживаемые ветки PostgreSQL сейчас — 14–18, поэтому для новых внедрений разумно ориентироваться на PostgreSQL 16–18 и pgvector 0.8.2.
Если нужен один короткий вывод, то он такой: для большинства онлайн-RAG-нагрузок разумная точка старта — HNSW, потому что в текущей документации pgvector он прямо описан как индекс с лучшим speed/recall trade-off, чем IVFFlat; расплачиваетесь вы за это более долгой сборкой и большим потреблением памяти. IVFFlat стоит выбирать тогда, когда критичны скорость построения индекса, более предсказуемая память и дешёвые массовые rebuild’ы, а также когда корпус заранее bulk-load’ится и настраивается под конкретные lists/probes.
Для RAG важно не перепутать технологию и сценарий. Если запросы почти всегда идут по узким фильтрам вроде tenant_id, project_id, language, а подмножество документов невелико, PostgreSQL может выполнять точный поиск по фильтр-индексам эффективнее ANN-индекса; pgvector 0.8.0 отдельно отмечает, что если сопоставимая производительность достижима без ANN, это предпочтительно, потому что даёт 100% recall. И наоборот, когда фильтр не слишком селективен, а SLA по латентности жёсткий, ANN уже выигрывает.
Практический выбор для статьи ниже такой: раз версия PostgreSQL и pgvector не указана, примеры даны в совместимом стиле для PostgreSQL 14–18 и актуального pgvector 0.8.x; а раз размер корпуса и профиль нагрузки не указаны, материал отдельно рассматривает «малые» сценарии до нескольких миллионов векторов и «большие» — с десятками и сотнями миллионов. Это не жёсткие границы, а удобная инженерная рамка для планирования индексов, памяти и миграций.
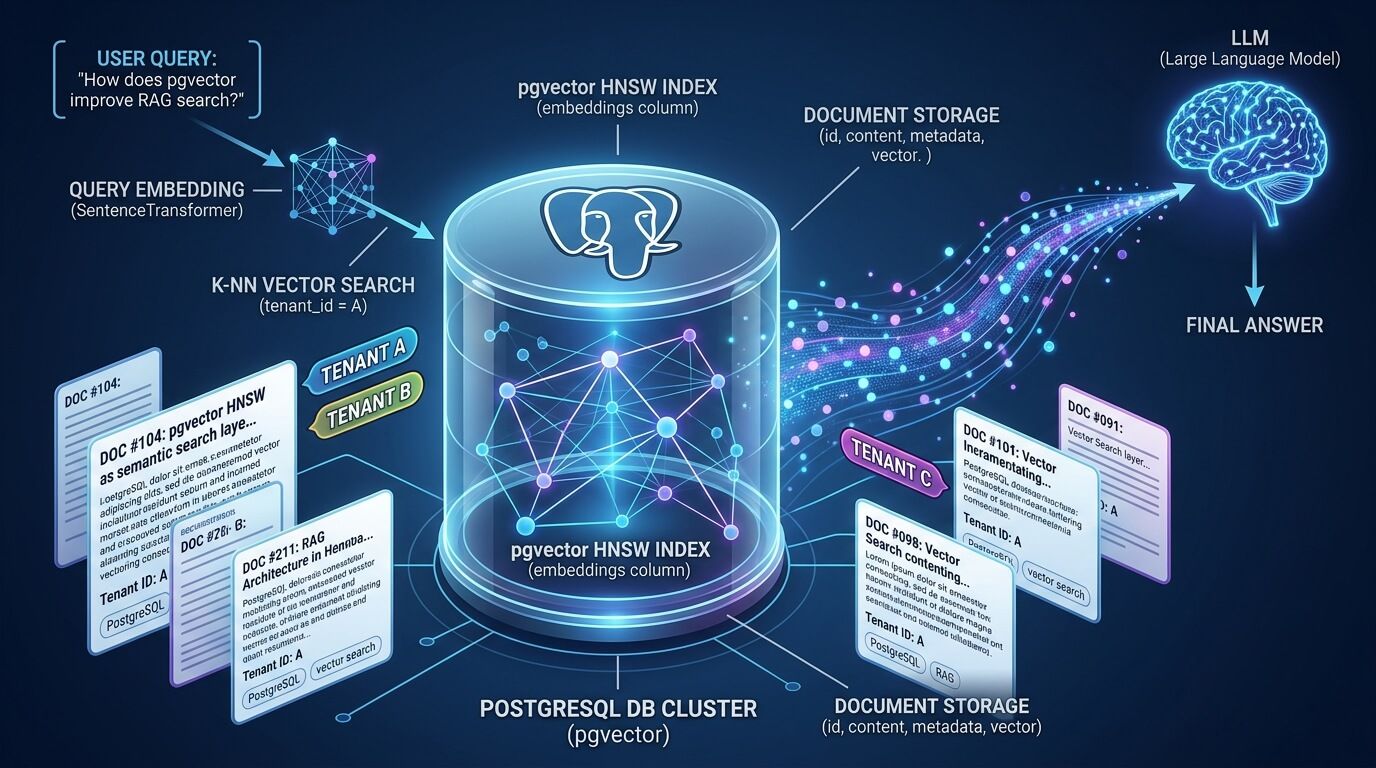
Pgvector как слой поиска для RAG
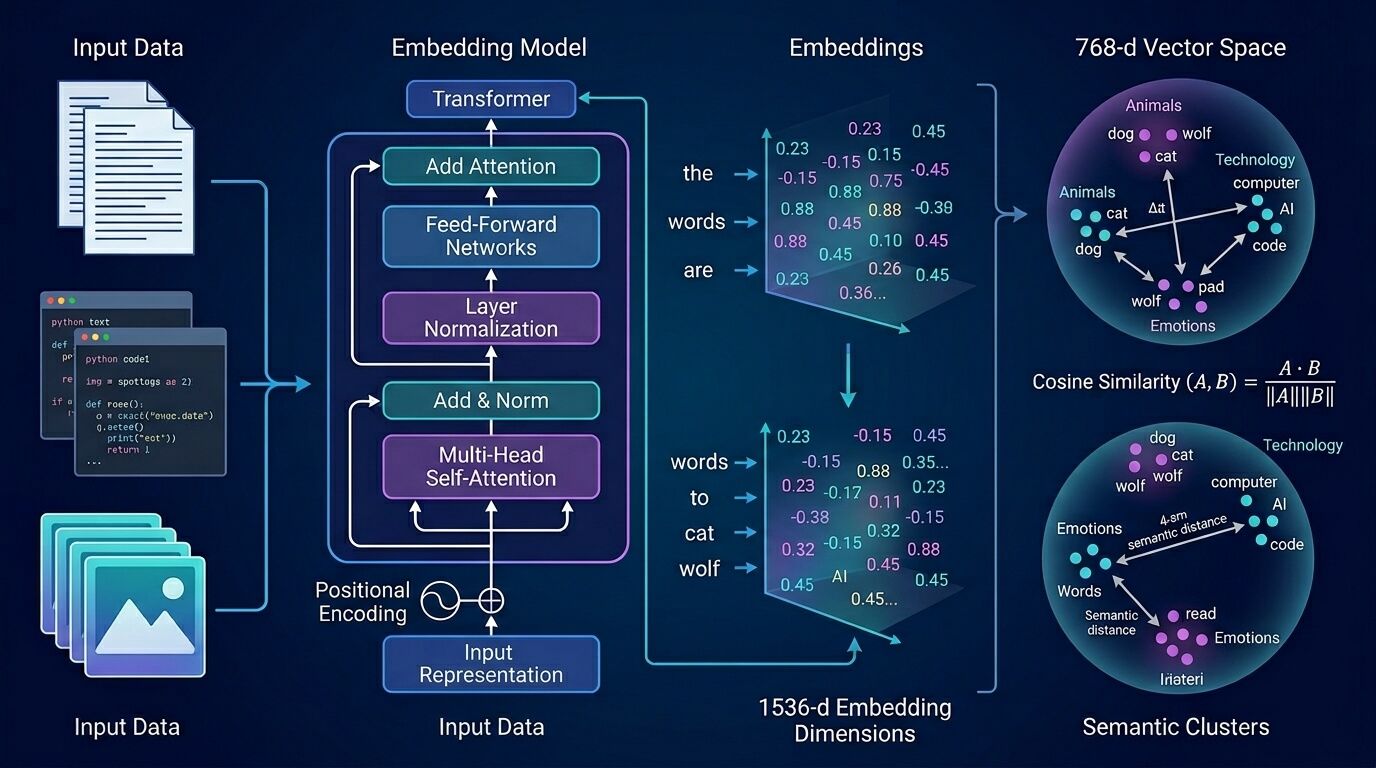
Идея RAG появилась как ответ на ограничение «знаний в параметрах» у языковых моделей: в исходной работе Lewis и соавторов прямо сказано, что обновление мировых знаний и объяснимость через provenance остаются открытыми проблемами, а retrieval-augmented подход решает их через связку параметрической модели и внешней не-параметрической памяти — плотного индекса документов. Именно поэтому векторный индекс в RAG — не optional enhancement, а центральная часть архитектуры.
С точки зрения PostgreSQL, pgvector даёт два режима: точный nearest neighbor search по умолчанию и приближённый через ANN-индексы HNSW или IVFFlat. Документация pgvector прямо подчёркивает, что точный поиск даёт perfect recall, а после добавления approximate index результаты могут отличаться, потому что вы сознательно меняете полноту на скорость. Для RAG это важный организационный момент: всегда держите у себя exact-baseline для проверки recall@k и качества ответа.
Сильная сторона именно pgvector в том, что вектор остаётся «рядом» с реляционными данными. Репозиторий расширения перечисляет поддержку обычных и approximate nearest neighbor запросов, типов vector, halfvec, bit, sparsevec, нескольких метрик и при этом отдельно подчёркивает преимущества PostgreSQL — ACID, point-in-time recovery, JOIN и всё остальное, что уже умеет сервер. Для RAG это означает меньше системных разрывов: не нужно выносить метаданные в одну БД, а эмбеддинги — в другую, если ваши SLA, объём и бюджет укладываются в один кластер PostgreSQL.
flowchart LR
A[Источники данных] --> B[Чанкинг и метаданные]
B --> C[Модель эмбеддингов]
C --> D[(PostgreSQL + pgvector)]
D --> E[ANN или exact retrieval]
E --> F[Фильтры, rerank, hybrid search]
F --> G[Сборка контекста]
G --> H[LLM]
H --> I[Ответ с опорой на найденные фрагменты]Минимальный SQL-паттерн у pgvector очень простой: создаёте расширение, добавляете колонку vector(n) и начинаете сортировать по distance operator. При этом индекс используется только если запрос написан «по-постгресовски»: ORDER BY должен быть именно по оператору расстояния, в возрастающем порядке, и почти всегда с LIMIT; выражения вроде 1 - cosine_distance в ORDER BY ломают план использования индекса.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE rag_chunks (
id bigserial PRIMARY KEY,
tenant_id bigint NOT NULL,
doc_id bigint NOT NULL,
chunk_no integer NOT NULL,
content text NOT NULL,
embedding vector(1536)
);
-- типичный nearest-neighbor запрос
SELECT id, doc_id, content
FROM rag_chunks
WHERE tenant_id = 42
ORDER BY embedding <=> $1
LIMIT 5;Для RAG это хорошо ещё и потому, что рядом с вектором легко держать обычные B-tree индексы по фильтрующим полям. В документации pgvector отдельно сказано, что для запросов с WHERE хорошая начальная стратегия — обычный индекс на filter-column, а exact search часто выигрывает, если условие выбирает малую долю строк. Для мультиарендных RAG-систем это не экзотика, а базовый сценарий.
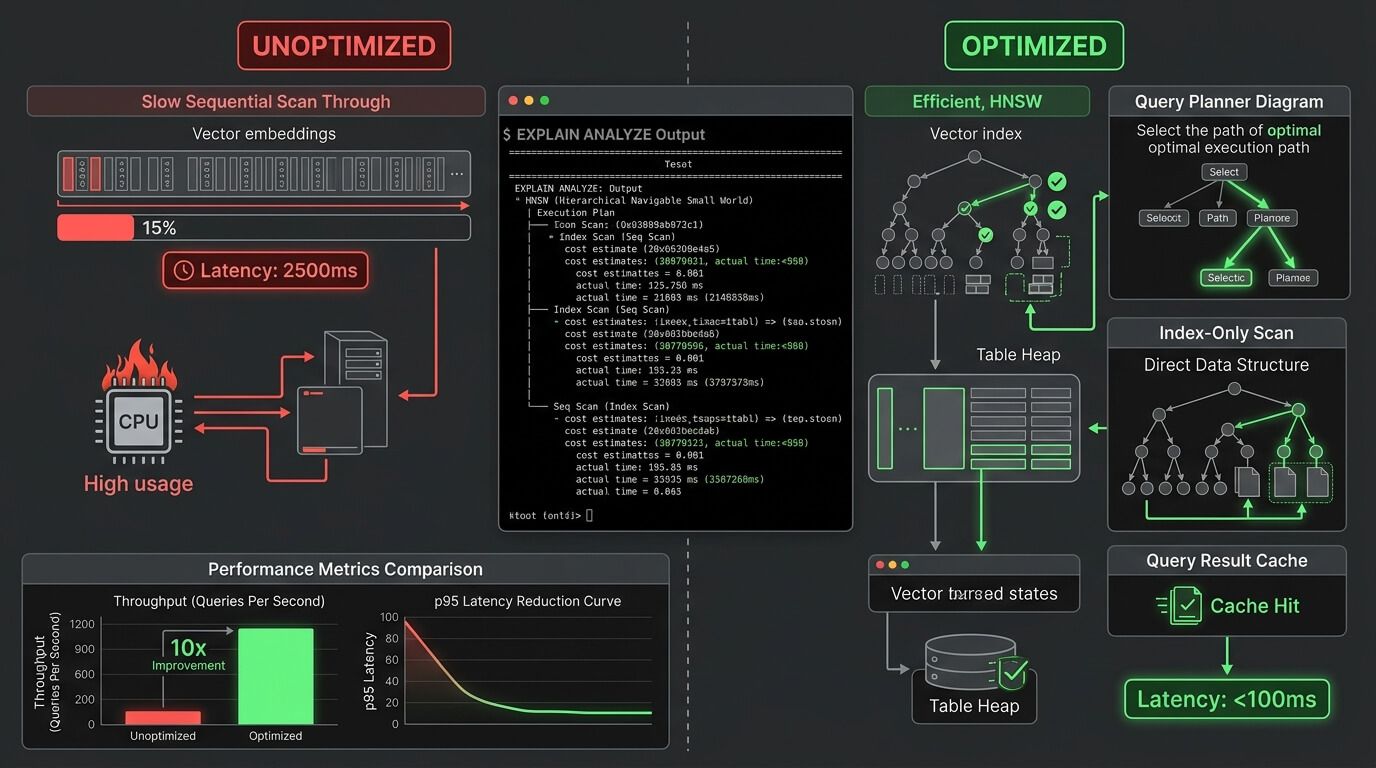
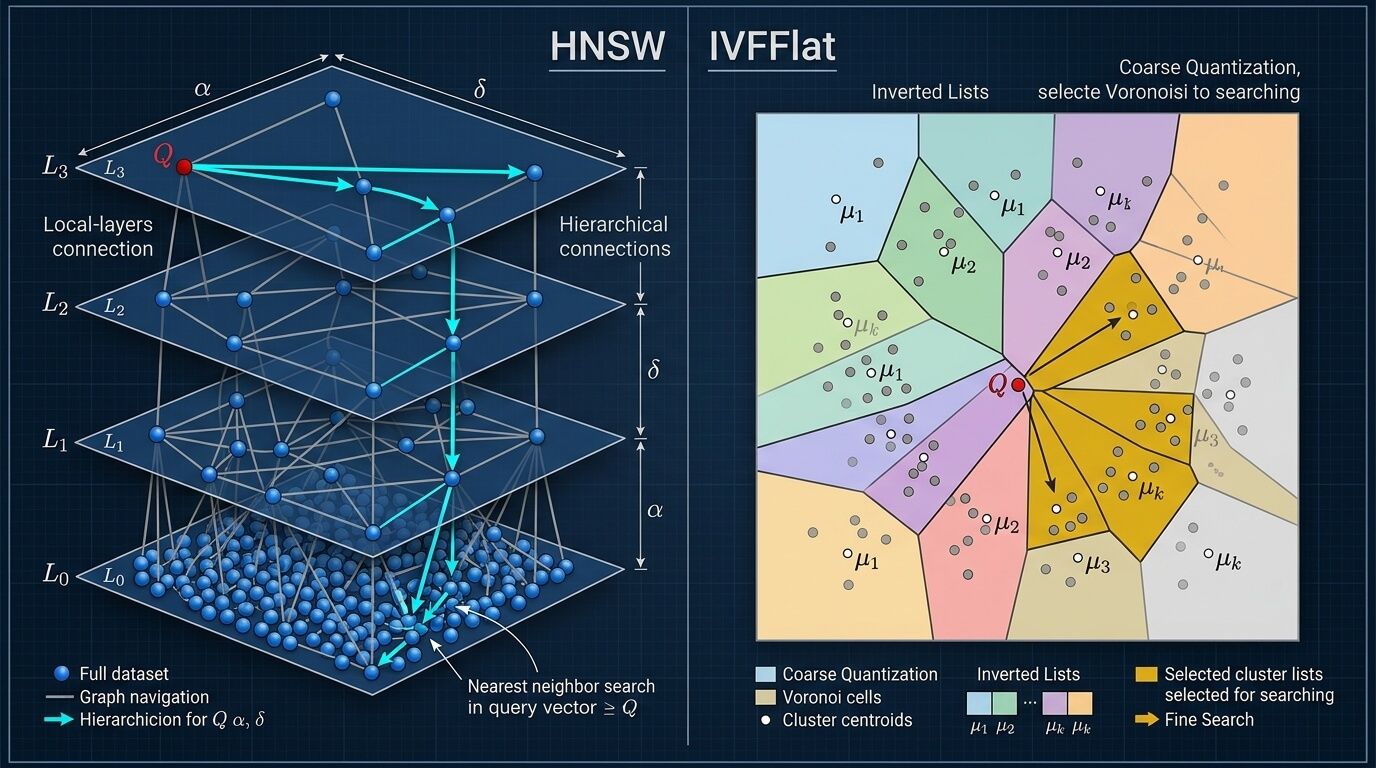
HNSW и IVFFlat без мифов
У pgvector два ANN-индекса, и это не просто «быстрый» и «медленный» режимы, а два разных подхода к поиску соседей. HNSW — это иерархический граф ближайших соседей; в оригинальной статье Malkov и Yashunin описывают многоуровневую графовую структуру, где поиск начинается сверху и спускается вниз, что даёт эффективный поиск и логарифмическое масштабирование в исходной модели. IVFFlat — это inverted file: пространство разбивается на списки (ячейки, кластеры, Voronoi-like partitions), а на запросе просматривается только часть ближайших списков. Именно из этого вырастают два разных профиля эксплуатации.
В документации pgvector этот контраст сформулирован очень прямо. HNSW создаёт multilayer graph, имеет лучший speed/recall trade-off, но строится дольше и ест больше памяти; зато его можно создать даже на пустой таблице, потому что training step ему не нужен. IVFFlat, наоборот, делит векторы на lists, строится быстрее и использует меньше памяти, но уступает HNSW по speed/recall trade-off и требует уже имеющихся данных для хорошего обучения coarse partitioning.
Если вы приходите из мира Faiss или hnswlib, сопоставление параметров полезно держать в голове. В pgvector у HNSW параметры называются так же, как в HNSW-литературе: m, ef_construction, hnsw.ef_search. У IVF ситуация чуть менее очевидна: SQL-параметр называется lists, но по смыслу это ровно тот же nlist, который Faiss использует для числа coarse clusters; ivfflat.probes соответствует nprobe. Метрика в pgvector задаётся не отдельным metric = ..., а operator class при создании индекса: vector_l2_ops, vector_ip_ops, vector_cosine_ops, а для bit — bit_hamming_ops и у HNSW ещё bit_jaccard_ops.
| Концепт | Pgvector | Аналог в Faiss или HNSWlib | Что регулирует | |---|---|---|---| | Число связей в графе HNSW | m | M | Плотность графа, память, recall | | Глубина построения HNSW | ef_construction | efConstruction | Качество графа против build time и insert speed | | Глубина поиска HNSW | hnsw.ef_search | efSearch или set_ef() | Recall против латентности | | Число coarse-кластеров IVF | lists | nlist | Грубость разбиения пространства | | Число просматриваемых кластеров IVF | ivfflat.probes | nprobe | Recall против латентности | | Метрика | operator class | metric | L2, inner product, cosine и др. |
Эта таблица — прямое сопоставление текущих pgvector SQL-knobs с параметрами из Faiss и hnswlib. HNSW-часть параметров почти один-в-один совпадает по смыслу; для IVF отличие в том, что pgvector использует имя lists, а не nlist.
Для HNSW базовые параметры в pgvector таковы: m = 16 по умолчанию, ef_construction = 64, hnsw.ef_search = 40. Документация говорит буквально следующее по trade-off: больший ef_construction даёт лучший recall ценой build time и insert speed, а больший ef_search — лучший recall ценой скорости запроса. Это делает HNSW отличным кандидатом для продовых RAG-систем, где индекс строится реже, чем читается. Дополнительно в актуальном changelog видно, что HNSW появился в pgvector 0.5.0, параллельная сборка для него пришла в 0.6.0, а в 0.8.0 были улучшены HNSW index scans и inserts; в 0.8.2 отдельно исправлен buffer overflow в parallel HNSW build. Для продакшена это весомый аргумент не сидеть на старых ветках расширения.
Для IVFFlat два главных вопроса — сколько сделать lists и сколько выставить probes. У pgvector есть очень полезная официальная эвристика: начинать с rows / 1000 для таблиц до 1 млн строк и со sqrt(rows) для таблиц больше 1 млн; число probes — хорошая стартовая точка около sqrt(lists). Faiss даёт близкую по духу рекомендацию: nlist ≈ C * sqrt(n), где цель — сбалансировать стоимость назначения к центроидам и сканирования inverted lists. Важно, что у pgvector ivfflat.probes = 1 по умолчанию, и при повышении probes recall растёт, а скорость падает; если довести probes до числа lists, поиск становится exact, и planner обычно уже не выбирает индекс.
Отдельно нужно проговорить про метрику. В RAG чаще всего используются cosine similarity или inner product. Faiss прямо пишет, что inner product становится эквивалентом cosine similarity при L2-нормализации и что ранжирование можно свести к MIPS либо L2 на нормализованных векторах; pgvector, в свою очередь, рекомендует для нормализованных до единичной длины эмбеддингов использовать inner product ради лучшей производительности. Практически это означает простое правило: если ваш embedding-provider гарантирует unit-normalized output, чаще всего стоит начинать с vector_ip_ops и запроса через <#>; если нет — с vector_cosine_ops и <=>.
Очень важный продовый нюанс — фильтрация. При approximate search фильтры применяются после сканирования ANN-индекса; документация pgvector даже приводит пример, что если условие совпадает с 10% строк и hnsw.ef_search = 40, вы получите в среднем лишь около 4 подходящих строк. С pgvector 0.8.0 это частично лечится через iterative index scans: strict_order сохраняет порядок расстояния, а relaxed_order улучшает recall ценой лёгкого нарушения порядка, который затем при необходимости выправляется materialized CTE. Для мультиарендного RAG это не тонкая оптимизация, а буквально разница между «находит нужные куски» и «иногда пусто».
Качественная сводка для выбора индекса выглядит так.
| Критерий | HNSW | IVFFlat | |---|---|---| | Принцип работы | Многоуровневый граф соседства | Inverted lists после coarse partitioning | | Качество при той же латентности | Обычно выше | Обычно ниже | | Память | Выше | Ниже | | Время построения | Дольше | Быстрее | | Нужен training step | Нет | Да | | Можно строить на пустой таблице | Да | Нет, нежелательно | | Поведение при постоянных вставках | Подходит, но вставки дороже | Подходит, но со временем может потребоваться rebuild из-за неудачных lists/распределения | | Лучший стартовый выбор для RAG | Да, в большинстве онлайн-сценариев | Да, когда важнее дешёвые build’ы и жёсткая экономия RAM |
Эта таблица — инженерная сводка официальных trade-off’ов из pgvector и базовых принципов HNSW/IVF из первоисточников. Для HNSW официально зафиксированы более высокий memory footprint и лучший speed/recall trade-off; для IVFFlat — более быстрая сборка, меньшая память и зависимость от удачного выбора lists/probes и имеющихся данных на момент build’а.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Миграции схемы без простоя
Хорошая миграция под pgvector почти всегда разбивается на две логические части: сначала изменение схемы и backfill, потом индексация и переключение read-path. Причина простая: PostgreSQL разрешает обычный CREATE INDEX внутри транзакции, но CREATE INDEX CONCURRENTLY — нет; более того, concurrent build для индексов на partitioned parent table не поддерживается, поэтому на секционированных таблицах индекс обычно строят по секциям и затем attach’ят на родителя. Для production migration frameworks это означает: не пытайтесь уместить всё в одну транзакционную миграцию Alembic/Flyway/Liquibase.
flowchart TD
A[Preflight: backup и restore point] --> B[CREATE EXTENSION и ALTER TABLE]
B --> C[Backfill через staging или ETL]
C --> D[ANALYZE и проверки качества]
D --> E[CREATE INDEX CONCURRENTLY]
E --> F[Canary-запросы и EXPLAIN]
F --> G[Переключение read-path]
G --> H[План reindex и vacuum]Первый шаг — проверить установленную версию расширения и, если нужно, обновить его до актуальной версии после установки файлов расширения на сервер. Официальный путь для обновления расширений в PostgreSQL — ALTER EXTENSION ... UPDATE; при major-upgrade самого PostgreSQL pg_upgrade отдельно напоминает, что внешние модули тоже должны быть бинарно совместимы. Для новых внедрений это ещё один довод не тащить старые сборки pgvector годами.
-- посмотреть текущую версию pgvector в базе
SELECT extversion
FROM pg_extension
WHERE extname = 'vector';
-- подключить расширение
CREATE EXTENSION IF NOT EXISTS vector;
-- обновить расширение до установленной на сервере версии
ALTER EXTENSION vector UPDATE;Дальше — добавление векторной колонки. У PostgreSQL есть важный нюанс: добавление столбца с volatile DEFAULT, generated column и рядом других вариантов может переписать всю таблицу; отсюда практический вывод: в больших таблицах безопаснее сначала добавить nullable column без DEFAULT, а уже потом backfill’ить её пакетно. Затем — отдельная staging-таблица или внешний ETL, который загружает готовые эмбеддинги через COPY; сам pgvector — это storage/search-слой, а не провайдер эмбеддингов. После массивного backfill’а стоит выполнить ANALYZE, потому that planner зависит от актуальной статистики.
ALTER TABLE rag_chunks
ADD COLUMN embedding vector(1536);
CREATE TABLE rag_chunks_embedding_stage (
id bigint PRIMARY KEY,
embedding vector(1536) NOT NULL
);
-- bulk load эмбеддингов, подготовленных вне БД
COPY rag_chunks_embedding_stage (id, embedding)
FROM STDIN WITH (FORMAT BINARY);
UPDATE rag_chunks c
SET embedding = s.embedding
FROM rag_chunks_embedding_stage s
WHERE c.id = s.id
AND c.embedding IS DISTINCT FROM s.embedding;
ANALYZE rag_chunks;Для production-RAG стоит добавить и проверку качества backfill’а. В документации pgvector есть важное примечание: NULL-векторы не индексируются; для cosine distance не индексируются и нулевые векторы. Если вы строите индекс vector_cosine_ops, а у части строк backfill пропущен или пришли плохие эмбеддинги, вы получите не «медленно», а просто непредсказуемо неполные результаты.
SELECT count(*) AS null_embeddings
FROM rag_chunks
WHERE embedding IS NULL;После backfill’а можно строить индексы. Для HNSW и IVFFlat синтаксис одинаково прост, но operationally различается смысл параметров. Для HNSW build time очень чувствителен к maintenance_work_mem; pgvector прямо пишет, что индексы строятся заметно быстрее, если граф помещается в maintenance_work_mem, и показывает NOTICE, когда перестаёт помещаться. Для обеих ANN-стратегий также лучше сначала загрузить initial data, а потом строить индекс. В production стоит использовать CONCURRENTLY, чтобы не блокировать запись.
-- HNSW для cosine distance
CREATE INDEX CONCURRENTLY rag_chunks_embedding_hnsw_cos_idx
ON rag_chunks USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- IVFFlat для cosine distance
CREATE INDEX CONCURRENTLY rag_chunks_embedding_ivf_cos_idx
ON rag_chunks USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 4096);С точки зрения наблюдаемости, у HNSW и IVFFlat разный pipeline построения. PostgreSQL даёт pg_stat_progress_create_index, а pgvector дополняет его собственными фазами: у HNSW это, по сути, initializing и loading tuples; у IVFFlat есть характерные шаги performing k-means, assigning tuples, loading tuples. Это удобно не только для мониторинга, но и для capacity planning: если у вас IVFFlat часами висит на k-means, проблема не в WAL, а в самой coarse-partitioning стадии.
-- прогресс HNSW
SELECT phase,
round(100.0 * blocks_done / nullif(blocks_total, 0), 1) AS pct
FROM pg_stat_progress_create_index;
-- прогресс IVFFlat
SELECT phase,
round(100.0 * tuples_done / nullif(tuples_total, 0), 1) AS pct
FROM pg_stat_progress_create_index;Если concurrent build падает, PostgreSQL оставляет INVALID index. Официальная рекомендация — либо удалить его и повторить CREATE INDEX CONCURRENTLY, либо выполнить REINDEX INDEX CONCURRENTLY. Это стоит автоматизировать в миграционных playbook’ах, потому что «невалидный, но существующий» индекс — самая неприятная форма полусломанного выката.
REINDEX INDEX CONCURRENTLY rag_chunks_embedding_hnsw_cos_idx;С бэкапами и откатами логика такая. pg_dump делает согласованную выгрузку даже при параллельной работе с базой и не блокирует readers/writers, но сама документация PostgreSQL отдельно предупреждает: pg_dump обычно не лучший инструмент для регулярных production-backup’ов. Для продового rollback-контурa нужны base backup’ы, WAL-архивация и PITR; pg_basebackup умеет снимать базовую копию работающего кластера и использоваться как база для point-in-time recovery и для standby. Перед крупной миграцией полезно поставить restore point.
# логический бэкап базы
pg_dump -Fc -d appdb -f appdb.dump
# восстановление логического бэкапа
pg_restore -d appdb_restored appdb.dump
# базовая копия кластера для PITR / standby
pg_basebackup -D /backups/base_2026_04_17 -X streamSELECT pg_create_restore_point('before_pgvector_migration');Практический rollback-путь для pgvector-миграций поэтому обычно такой: удаление/реиндексация невалидного индекса при локальной ошибке миграции; откат read-path на старый exact или старый индекс при проблеме качества; полноценный PITR до restore point — если проблема затронула данные массово. Это надёжнее, чем надеяться на «быстрый downgrade» расширения, потому что официально ALTER EXTENSION ... UPDATE описан как переход на новую версию при наличии update-scripts, а не как универсальная двусторонняя машина откатов.
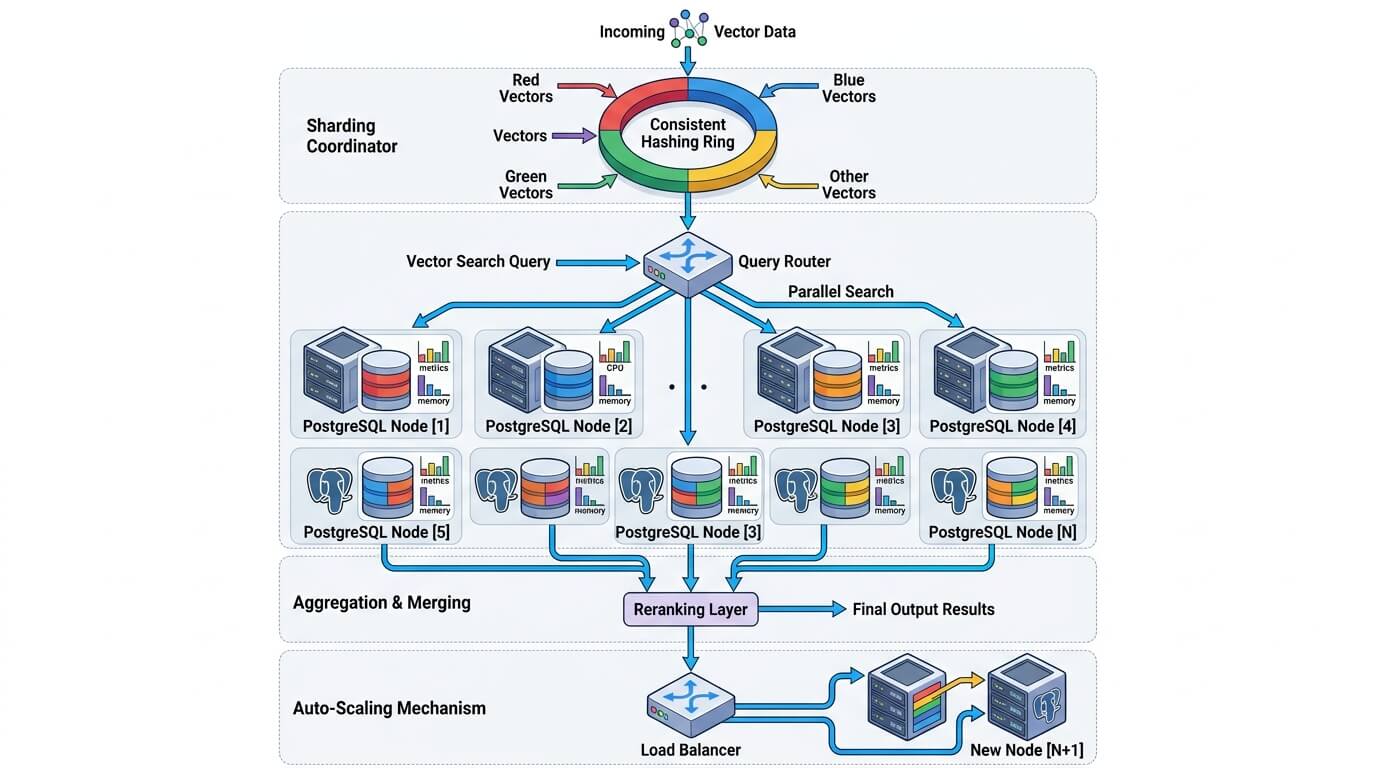
Эксплуатация в продакшене
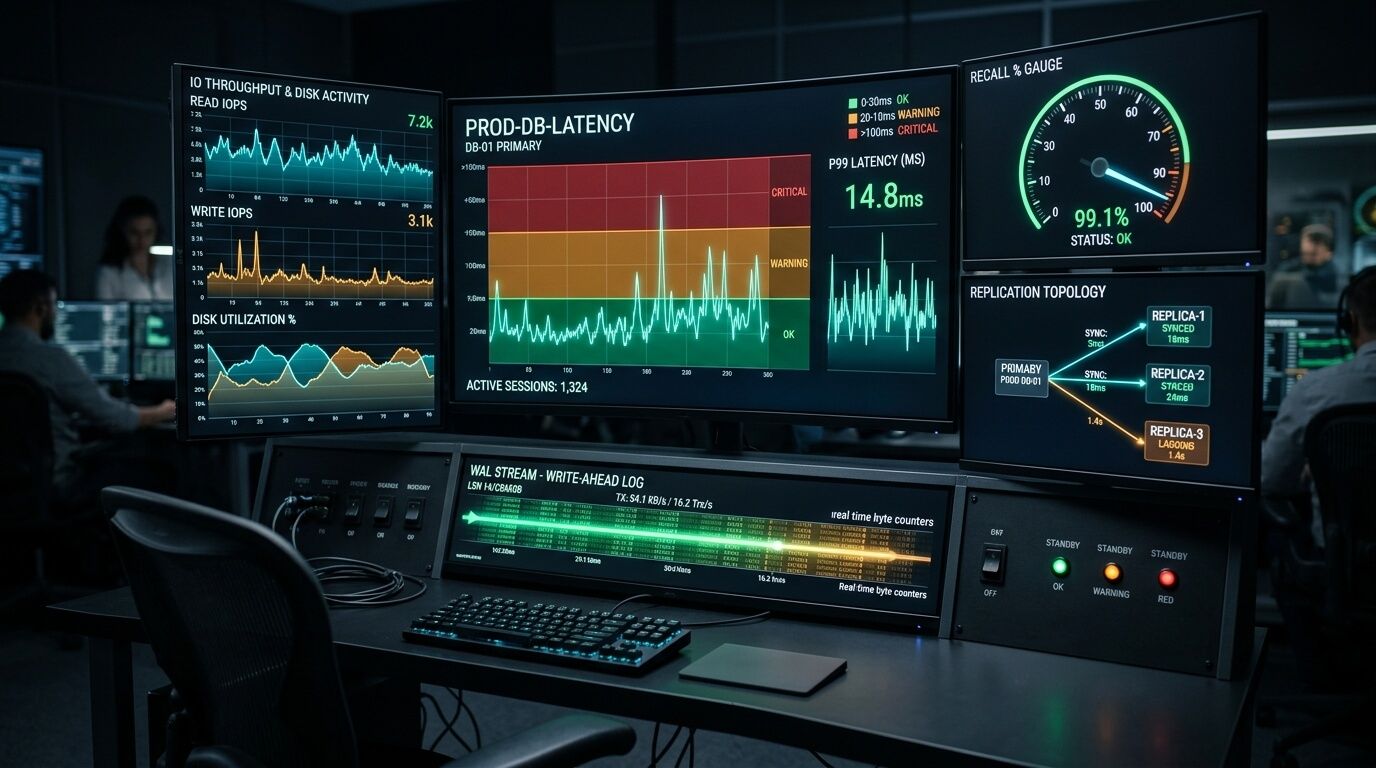
Для эксплуатации pgvector полезно мыслить не в терминах «индекс есть или нет», а в терминах SLO: p95/p99 latency ANN-запросов, recall@k относительно exact baseline, размер индекса, время rebuild’а, WAL/IO pressure во время bulk load и reindex, а также lag реплик и состояние replication slots. Именно эта связка говорит, где у вас настоящий bottleneck — в алгоритме, в фильтрах, в памяти, в WAL или уже в операционном контуре PostgreSQL.
Минимальный operational stack обычно выглядит так.
| Что мониторить | Зачем | Основной источник | |---|---|---| | Тяжёлые и частые поисковые запросы | видеть p95/p99 и top-N query patterns | pg_stat_statements | | Прогресс build/rebuild | не гадать, где стоит индексация | pg_stat_progress_create_index | | Использование индексов | понимать, выбран ли индекс planner’ом | pg_stat_user_indexes | | IO и buffer pressure | ловить evictions, read/write/fsync hotspots | pg_stat_io на PostgreSQL 16+ | | Активность и ожидания | смотреть lock/wait/WAL waits | pg_stat_activity | | Репликацию | видеть lag и риски по slot retention | pg_stat_replication, pg_replication_slots | | Физический размер индекса | планировать RAM и rebuild windows | pg_relation_size() |
Все перечисленные представления и функции — штатная статистическая подсистема PostgreSQL; pg_stat_statements нужно заранее загрузить через shared_preload_libraries, pg_stat_user_indexes показывает доступы к индексам, а pg_stat_io с PostgreSQL 16 даёт cluster-wide IO-statistics по relation/WAL и прямо предназначен для тюнинга.
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
SELECT query,
calls,
round((total_plan_time + total_exec_time) / calls) AS avg_ms,
round((total_plan_time + total_exec_time) / 60000.0, 2) AS total_min
FROM pg_stat_statements
ORDER BY total_plan_time + total_exec_time DESC
LIMIT 20;SELECT relname AS table_name,
indexrelname AS index_name,
idx_scan,
idx_tup_read,
idx_tup_fetch
FROM pg_stat_user_indexes
WHERE indexrelname LIKE '%embedding%'
ORDER BY idx_scan DESC;-- PostgreSQL 16+
SELECT backend_type, object, context, reads, writes, write_time, fsyncs, fsync_time
FROM pg_stat_io
WHERE object IN ('relation', 'wal')
ORDER BY write_time DESC NULLS LAST
LIMIT 20;Отдельно у pgvector есть очень правильная рекомендация: измеряйте recall сравнением approximate vs exact. Делается это просто — временно отключаете index scan, получаете exact-baseline, сравниваете top-k пересечение. Это не научная роскошь, а обязательный operational practice для RAG, потому что низкий recall почти всегда аукнется качеством ответа LLM уже через несколько миллисекунд после того, как «база отработала быстро».
BEGIN;
SET LOCAL enable_indexscan = off; -- exact search baseline
SELECT id
FROM rag_chunks
WHERE tenant_id = 42
ORDER BY embedding <=> $1
LIMIT 10;
COMMIT;С тюнингом есть несколько неочевидных моментов. Во-первых, maintenance_work_mem — главное топливо для build/rebuild; PostgreSQL описывает его как лимит памяти для maintenance-операций (VACUUM, CREATE INDEX и др.), а pgvector прямо говорит, что HNSW строится заметно быстрее, если граф помещается в эту память. Во-вторых, work_mem — это per-operation budget, который может многократно размножиться по сессиям и параллельным worker’ам; в contrast к нему PostgreSQL отдельно подчёркивает, что для parallel utility commands maintenance_work_mem применяется ко всей операции целиком, а не на worker. В-третьих, shared_buffers на dedicated server логично начинать около 25% RAM, но большие значения обычно требуют и большего max_wal_size, иначе checkpoints станут слишком частыми.
Для VACUUM и churn-нагрузок важно помнить, что PostgreSQL хранит dead tuples до vacuum, и это особенно чувствительно на часто обновляемых таблицах. У pgvector есть отдельное практическое замечание: vacuuming HNSW indexes can take a while, и если нужно ускорить обслуживание, помогает REINDEX INDEX CONCURRENTLY перед VACUUM. На таблицах, где backfill или re-embedding происходят пачками, это лучше заранее закладывать в окно обслуживания, а не вспоминать в пятницу вечером.
REINDEX INDEX CONCURRENTLY rag_chunks_embedding_hnsw_cos_idx;
VACUUM (ANALYZE) rag_chunks;С планированием индексации правило простое: на одной таблице одновременно может идти только один concurrent index build, и concurrent build делает больше общей работы, чем обычный build, потому что выполняет несколько проходов и ждёт завершения старых транзакций. Это значит, что rebuild нескольких vector-индексов надо сериализовать по таблицам и защищать от long-running transactions; иначе вы будете видеть не «медленную индексацию», а «индексацию, которая ждёт чужую MVCC-историю».
Масштабируется pgvector так же, как сам PostgreSQL. Документация pgvector прямо советует вертикальное масштабирование, реплики для горизонтального чтения и Citus или иной sharding-подход для распределения данных; PostgreSQL, в свою очередь, для больших таблиц рекомендует partitioning, потому что оно улучшает locality, позволяет быстро удалять/архивировать старые куски и помогает держать рабочую часть индексов в памяти. Для RAG это обычно означает: сначала single-node + replica, затем partitioning по tenant/date/collection и только потом шардинг.
С репликацией нужно различать два режима. Физическая репликация копирует блоки и WAL, а pgvector в FAQ прямо говорит, что использует WAL, поэтому поддерживает replication и PITR. Логическая репликация распространяет данные и изменения по publish/subscribe; при старте она делает snapshot данных таблицы, а дальше шлёт изменения. Но schema drift здесь опаснее: PostgreSQL прямо пишет, что последующие изменения схемы надо синхронизировать вручную, иначе репликация остановится из-за несовпадения схемы. Для blue/green или cross-region RAG это критично учитывать заранее.
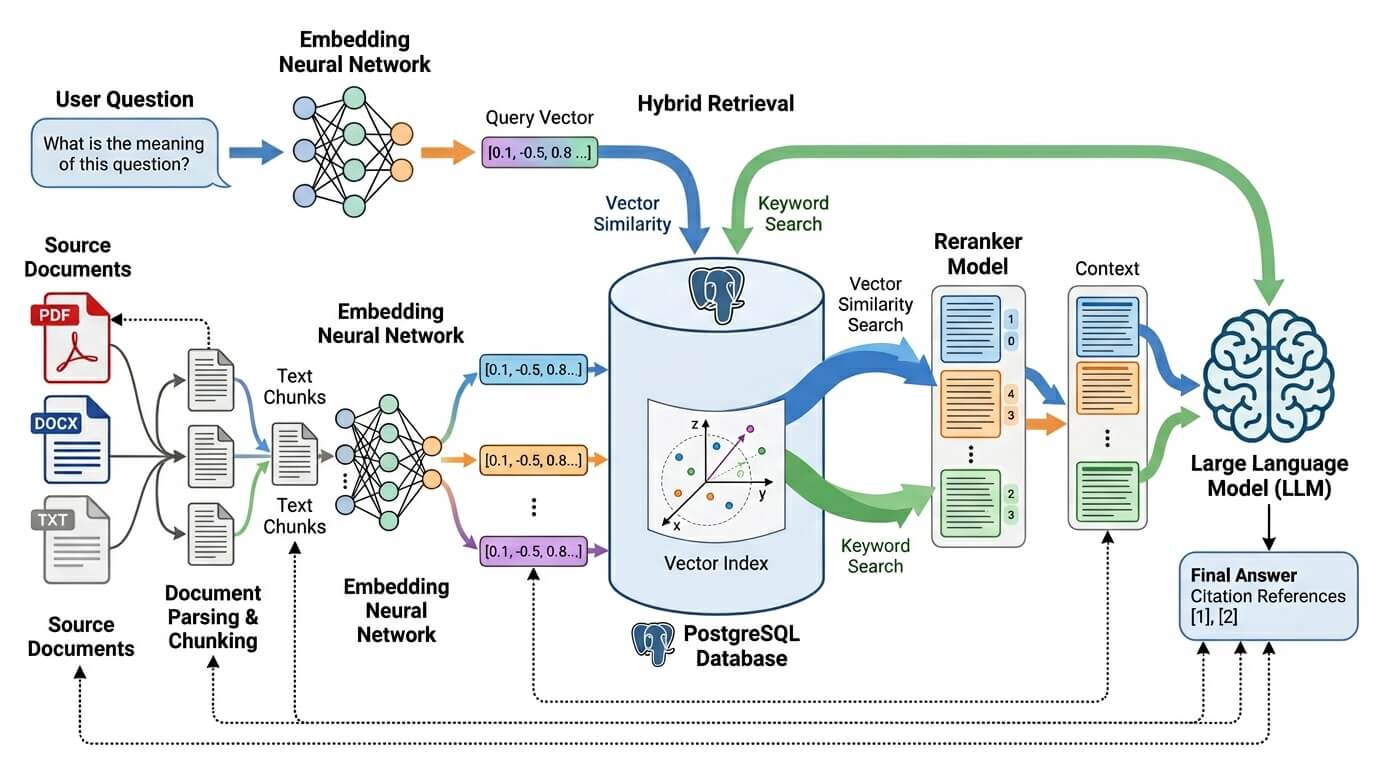
Конфигурации и железо
Ниже — не «магические числа», а рабочие стартовые профили. Они опираются на documented behavior PostgreSQL и pgvector: shared_buffers разумно начинать около 25% RAM на dedicated DB server; work_mem размножается по операциям и worker’ам, поэтому его легко переоценить; maintenance_work_mem безопасно держать заметно выше work_mem, но надо помнить, что autovacuum при дефолтном autovacuum_work_mem = -1 может брать значение от maintenance_work_mem; а build HNSW ускоряется, если граф помещается в maintenance budget.
Для практики этого достаточно, чтобы сформулировать простую аппаратную логику. HNSW любит RAM, потому что сам индекс тяжелее и его speed/recall преимущества лучше проявляются, когда горячая часть рабочей структуры сидит в памяти. IVFFlat любит предсказуемые bulk-load/rebuild процессы, потому что строится быстрее и скромнее по памяти. Накопленные RAG-корпуса любят NVMe, потому что и ANN, и exact fallback, и bulk backfill, и WAL-архивирование в конечном счёте живут на IO. PostgreSQL отдельно напоминает, что WAL пишется последовательно и его flush дешевле, чем flush всех data files; при высокой write-нагрузке pg_wal можно вынести на отдельное устройство.
Условная матрица выбора выглядит так.
| Сценарий | База рекомендаций | |---|---| | До нескольких миллионов векторов, строгие SLA на онлайн-поиск | PostgreSQL 16–18, HNSW, достаточная RAM, exact baseline и B-tree по фильтрам | | Несколько миллионов, но индекс строится часто и память ограничена | IVFFlat, bulk load → build → lists/probes tuning | | Десятки миллионов | Partitioning по tenant/collection/date, read replicas, HNSW или IVFFlat по фактическому recall/latency тесту | | Сотни миллионов и выше | Partitioning + sharding, halfvec/binary quantization/subvector indexing как компромиссы по памяти, регулярный benchmark exact vs ANN |
Это именно инженерная эвристика, а не hard limit. Официальные документы PostgreSQL и pgvector не дают «магической границы» в миллионах строк; они дают строительные блоки: partitioning, replicas, sharding, half-precision, binary quantization и обычные механизмы тюнинга PostgreSQL.
Ниже — два стартовых примера postgresql.conf. Они даны как профили начала тюнинга, а не как vendor defaults.
# Профиль для RAG-кластера среднего размера
shared_buffers = 16GB
work_mem = 64MB
maintenance_work_mem = 8GB
autovacuum_work_mem = 1GB
max_parallel_workers = 16
max_parallel_workers_per_gather = 4
max_parallel_maintenance_workers = 7
max_wal_size = 16GB
checkpoint_timeout = '15min'
shared_preload_libraries = 'pg_stat_statements'
compute_query_id = on
pg_stat_statements.max = 10000
pg_stat_statements.track = all# Профиль для крупного read-heavy RAG-кластера
shared_buffers = 64GB
work_mem = 32MB
maintenance_work_mem = 16GB
autovacuum_work_mem = 2GB
max_parallel_workers = 32
max_parallel_workers_per_gather = 8
max_parallel_maintenance_workers = 7
max_wal_size = 64GB
checkpoint_timeout = '15min'
shared_preload_libraries = 'pg_stat_statements'
compute_query_id = on
pg_stat_statements.max = 20000
pg_stat_statements.track = allПочему именно так. У PostgreSQL work_mem — per query-operation и может многократно умножаться на worker’ы; значит, при высококонкурентном RAG слишком большой work_mem опаснее, чем кажется на бумаге. maintenance_work_mem, наоборот, можно держать существенно выше ради CREATE INDEX, REINDEX, VACUUM. max_parallel_workers_per_gather ускоряет exact fallback и часть тяжёлых запросов, но PostgreSQL прямо предупреждает, что parallel query резко увеличивает совокупное потребление CPU/RAM/IO; то есть это не «поставить побольше», а «ставить осознанно». max_wal_size и checkpoint_timeout помогают не устраивать слишком частые checkpoints при bulk load и rebuild.
У самого pgvector есть и специальные способы ужать footprint. halfvec позволяет хранить векторы в half precision и индексировать до 4000 измерений, а expression indexing даёт возможность индексировать представление embedding::halfvec(...) для уменьшения индекса. Для экстремального memory-pressure можно использовать binary quantization и затем re-rank на исходных векторах; документация pgvector показывает этот паттерн явно. Для очень больших RAG-корпусов это часто выгоднее, чем слепо «докупать RAM».
Интеграция в RAG-пайплайн
Самая частая ошибка при интеграции pgvector в RAG — проектировать только индекс, а не жизненный цикл знания. У RAG внешняя память должна уметь обновляться, версионироваться, фильтроваться и давать provenance; исходная работа про RAG делает на этом особый акцент. В PostgreSQL это означает, что рядом с embedding обычно хочется хранить как минимум tenant_id, source_id, chunk_no, content_hash, embedding_model, embedding_version, created_at, updated_at, а иногда и deleted_at/is_active. Это уже не просто «хранилище векторов», а полноценный knowledge store.
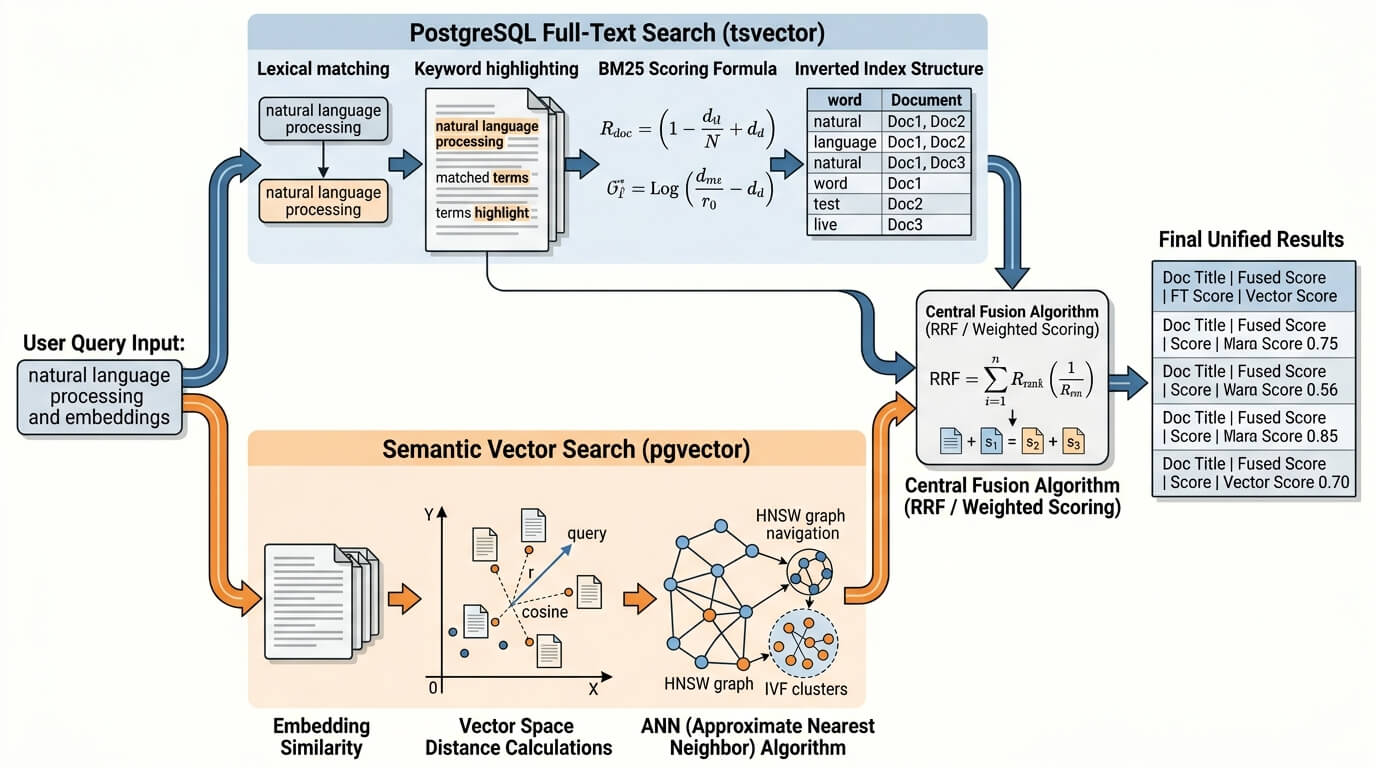
Для RAG-пайплайна особенно полезны две возможности pgvector. Первая — гибридный поиск: документация прямо рекомендует использовать векторный поиск вместе с PostgreSQL full-text search и объединять результаты RRF или cross-encoder’ом. Вторая — индексация представлений: можно строить expression indexes для subvector(...), binary_quantize(...) или halfvec, а затем делать re-rank по исходным векторам. Это даёт хороший operational path для крупных коллекций: быстрый грубый кандидат-генератор, затем точная сортировка на коротком хвосте.
Если вы планируете жить с несколькими embedding-моделями или мигрировать между разными размерностями, очень полезен documented pattern с типом vector без фиксированной размерности и partial expression indexes по model_id. Официальная FAQ pgvector показывает именно такой приём и отдельно подчёркивает, что индексировать можно только строки одной размерности за раз. Для продового RAG это идеально: храните старую и новую модель рядом, строите новый индекс concurrent, сравниваете recall/latency/answer quality, потом переключаете routing.
CREATE TABLE embeddings (
model_id bigint,
item_id bigint,
embedding vector,
PRIMARY KEY (model_id, item_id)
);
CREATE INDEX CONCURRENTLY embeddings_m202604_hnsw_cos_idx
ON embeddings
USING hnsw ((embedding::vector(1536)) vector_cosine_ops)
WHERE model_id = 202604;Для дедупликации и обновлений практический путь обычно такой. Используйте content_hash как идемпотентный ключ содержимого и либо уникальное ограничение на (source_id, chunk_no, embedding_model, embedding_version), либо UPSERT по surrogate/business key. Сам pgvector демонстрирует обычные INSERT ... ON CONFLICT DO UPDATE, UPDATE и DELETE как штатную модель работы, а PostgreSQL-индексы в целом всегда добавляют write-overhead — значит, задача не «избежать обновлений», а сделать их предсказуемыми, пакетными и проверяемыми. Это инженерный вывод из нормального DML-жизненного цикла PostgreSQL и documented support для upsert/update/delete в pgvector.
Выбор метрики в RAG тоже лучше зафиксировать на уровне контракта. Если эмбеддинги нормализованы до единичной длины, PostgreSQL и Faiss сходятся в одном практическом совете: inner product даёт хороший путь к cosine-like ranking, а в pgvector он ещё и рекомендован как более быстрый вариант для normalized embeddings. Если нормализации нет — используйте cosine distance, но не забывайте, что в ORDER BY индексу нужен именно raw distance operator, а преобразование в similarity-score лучше делать уже снаружи.
BEGIN;
SET LOCAL hnsw.ef_search = 100;
WITH nearest_results AS MATERIALIZED (
SELECT id,
doc_id,
content,
embedding <=> $1 AS distance
FROM rag_chunks
WHERE tenant_id = 42
ORDER BY distance
LIMIT 50
)
SELECT id,
doc_id,
content,
1 - distance AS cosine_similarity
FROM nearest_results
WHERE distance < 0.25
ORDER BY distance;
COMMIT;Если в запросах почти всегда есть tenant- и domain-фильтры, не полагайтесь только на ANN. Документация pgvector прямо рекомендует: сначала индексируйте filter-columns обычными индексами, а для низкой доли совпадений exact search может оказаться предпочтительнее; если же фильтрация выбивает слишком мало строк после approximate scan, поднимайте hnsw.ef_search или ivfflat.probes, а с 0.8.0 — включайте iterative scans. Для мультиарендного RAG это практически обязательный паттерн.
BEGIN;
SET LOCAL hnsw.ef_search = 200;
SET LOCAL hnsw.iterative_scan = relaxed_order;
WITH ann AS MATERIALIZED (
SELECT id,
doc_id,
content,
embedding <=> $1 AS distance
FROM rag_chunks
WHERE tenant_id = 42
ORDER BY distance
LIMIT 20
)
SELECT *
FROM ann
ORDER BY distance + 0; -- нужно для PostgreSQL 17+
COMMIT;И, наконец, стратегически: если у вас RAG-индекс часто переобучается или меняется embedding-model, делайте dual-run. Старый индекс остаётся serving baseline, новый индекс строится concurrent, на canary-трафике сравниваются latency, recall@k и downstream answer quality, после чего переключается retrieval layer. Смешение нескольких моделей без явного embedding_version — одна из самых дорогих ошибок, потому что ломается не SQL, а смысл расстояния между векторами.




