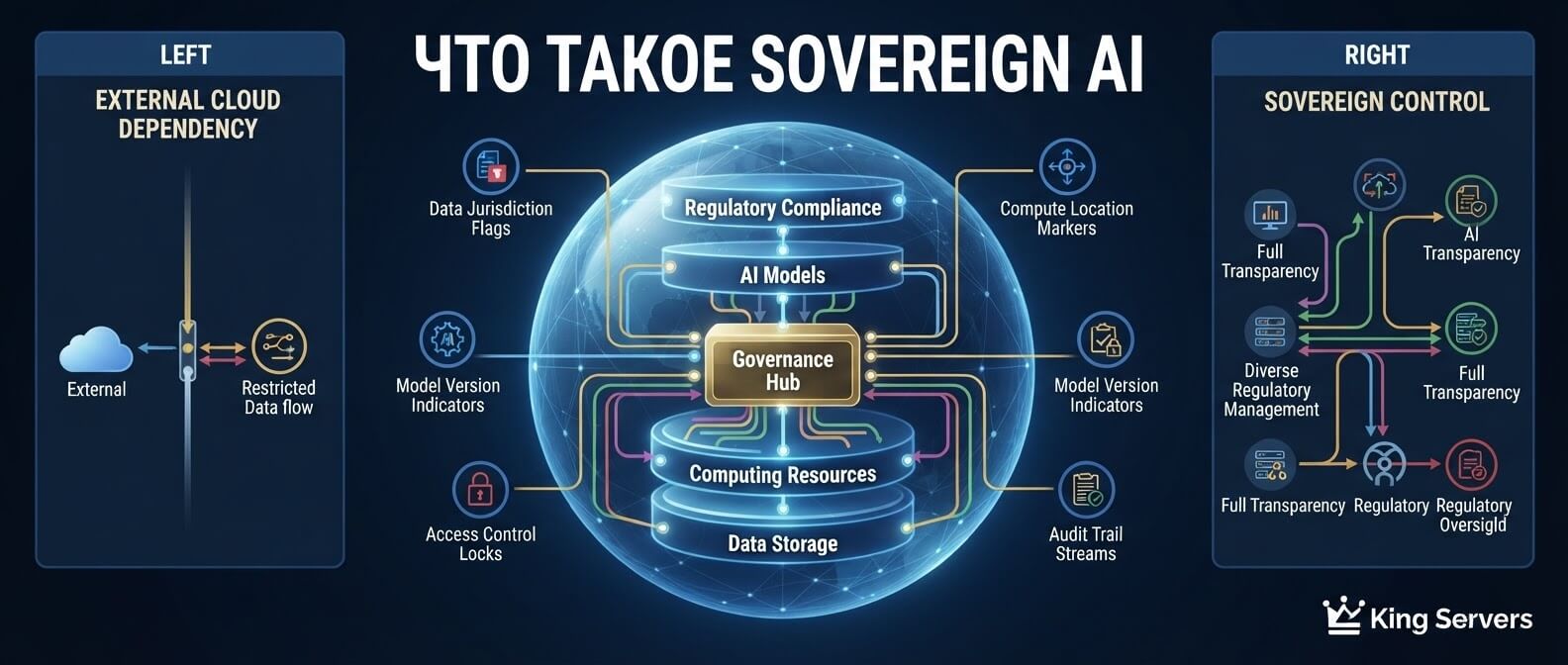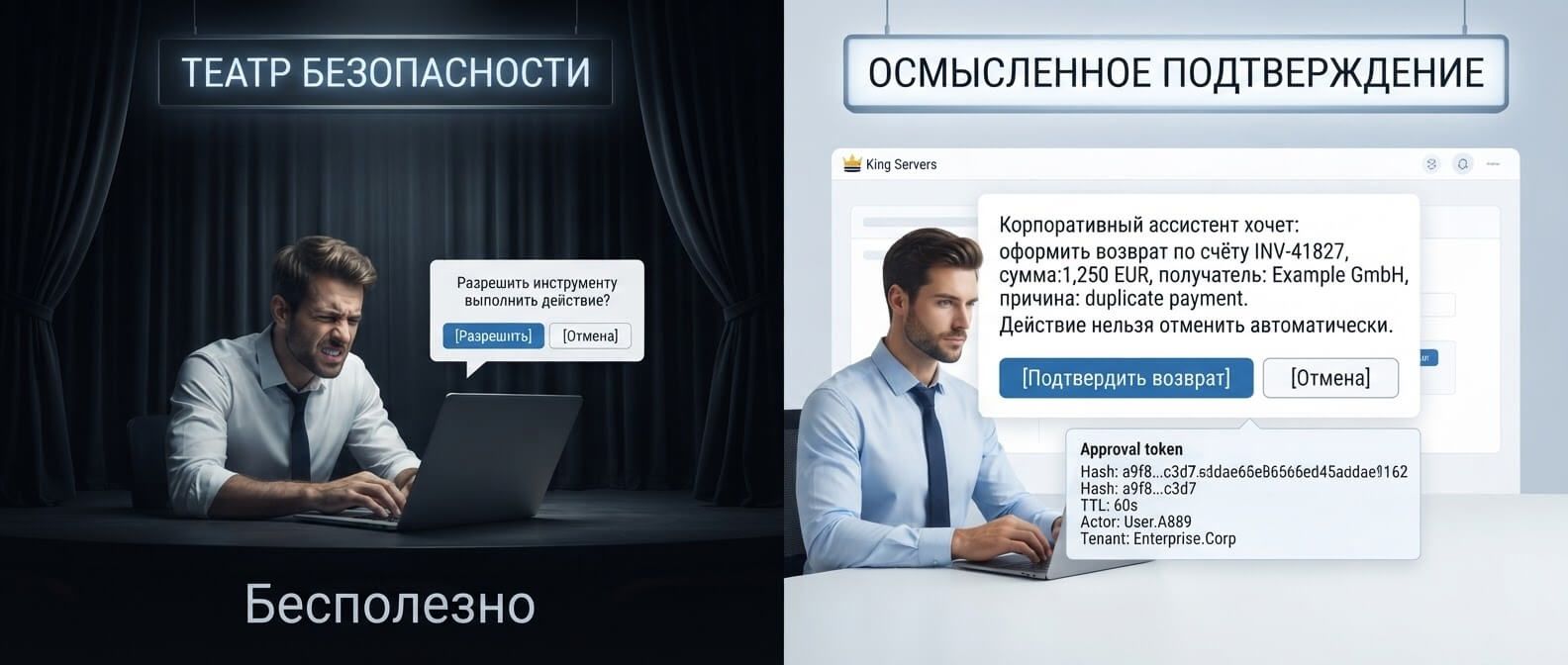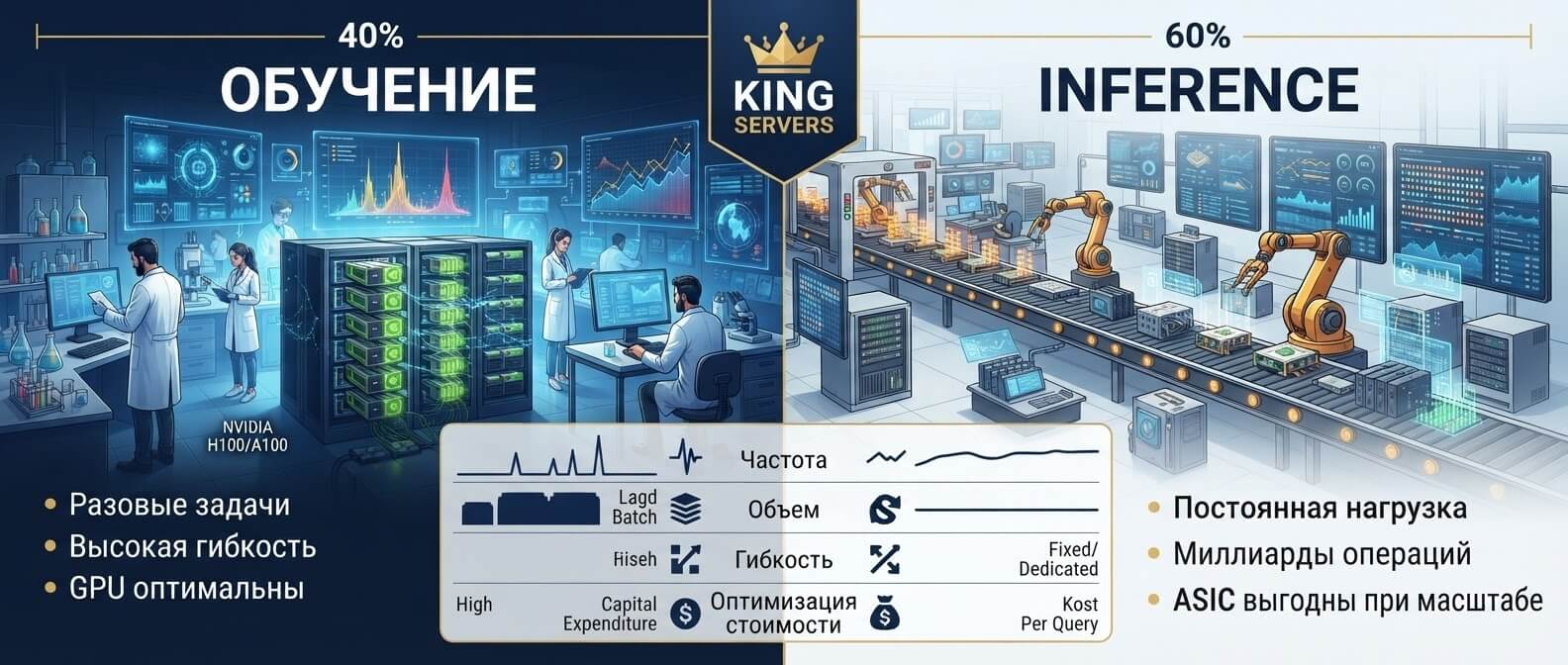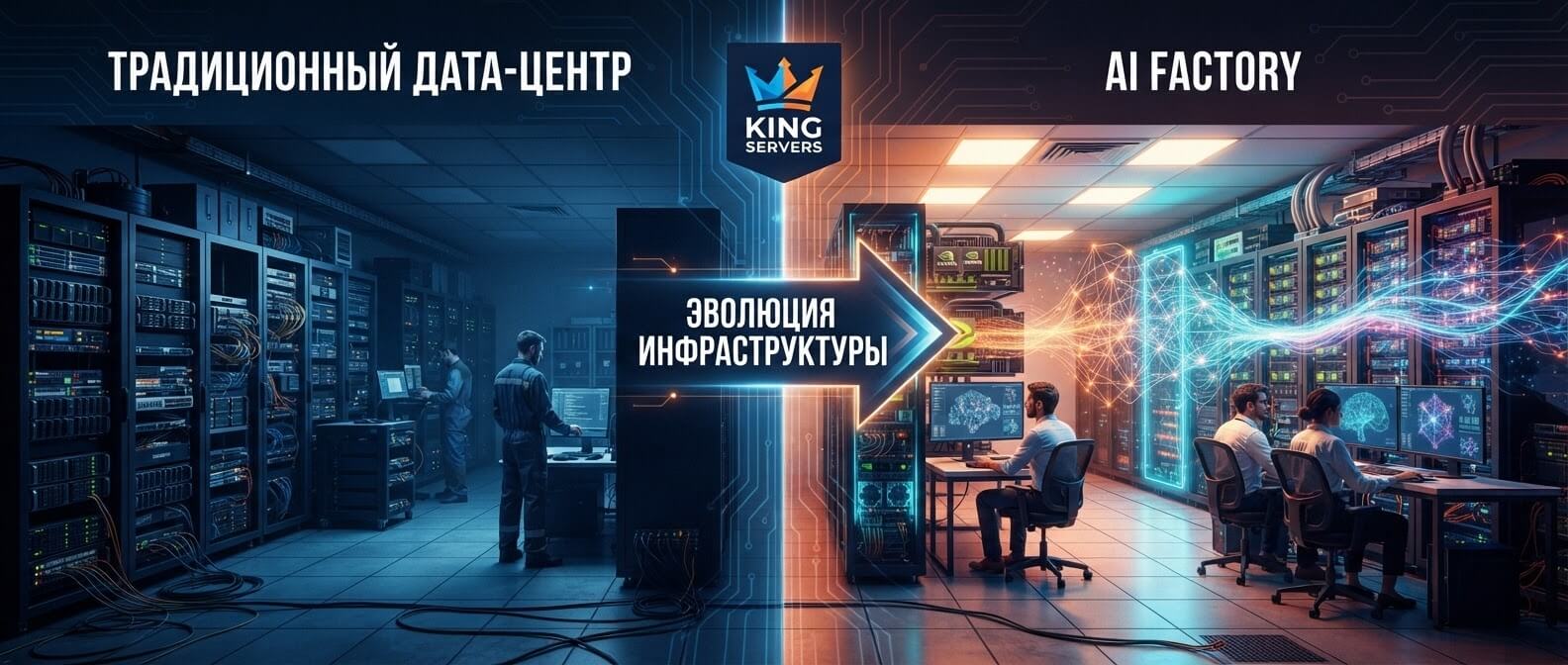
Data flywheel для AI-продукта: как улучшать нейросеть на основе действий пользователей
Практическое руководство по запуску data flywheel для AI-продукта: какие данные собирать, как классифицировать ошибки, строить evals, улучшать RAG и промпты, защищать информацию и связывать качество нейросети с бизнес-результатами.
Андрей Минин, автор блога