




















Оглавление
- Что такое PostgreSQL PITR простыми словами
- Почему обычного backup не всегда хватает
- WAL: сердце восстановления на точку времени
- Base backup: точка старта для восстановления
- Чем PITR отличается от dump и snapshot
- Что нужно подготовить перед настройкой PITR
- Настройка WAL-архивации в PostgreSQL
- Создаём пользователя для base backup
- Проверяем, что WAL действительно архивируется
- Делаем base backup
- Retention: сколько хранить base backup и WAL
- Как выполнить восстановление PostgreSQL на нужную точку времени
- Как выбрать правильную точку восстановления
- Тест восстановления: backup без теста ещё не backup
- Типичные ошибки при настройке PITR
- Где запускать восстановление: на production или отдельно
- PITR и инфраструктура: что важно на VPS и выделенном сервере
- Минимальный чек-лист настройки PostgreSQL PITR
- Практический пример: ошибка после миграции
- PITR не должен быть единственным планом
- Короткие ответы на частые вопросы
- Итог: PITR стоит настроить до первого серьёзного инцидента
Удалили важную таблицу. Накатили не тот SQL-скрипт. Обновление приложения записало в базу тысячи некорректных строк. В такие моменты обычная резервная копия помогает не всегда: она возвращает базу в состояние “на вчера”, “на ночь” или “на момент snapshot”, но бизнесу часто нужна точность до минуты, а иногда и до секунды. Для этого в PostgreSQL есть PITR, point-in-time recovery. Это восстановление базы данных на конкретную точку времени с помощью base backup и WAL-архивов. Грубо говоря, base backup даёт “тело” базы, а WAL-файлы позволяют прокрутить её историю до нужного момента, как запись с камеры наблюдения. PITR не заменяет все виды резервного копирования, но закрывает очень важный сценарий: быстро откатиться к состоянию до ошибки, аварии или неудачного релиза. Особенно если PostgreSQL работает на VPS, выделенном сервере или в инфраструктуре, где база хранит данные, потеря которых стоит дороже, чем настройка нормального backup-процесса.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Что такое PostgreSQL PITR простыми словами
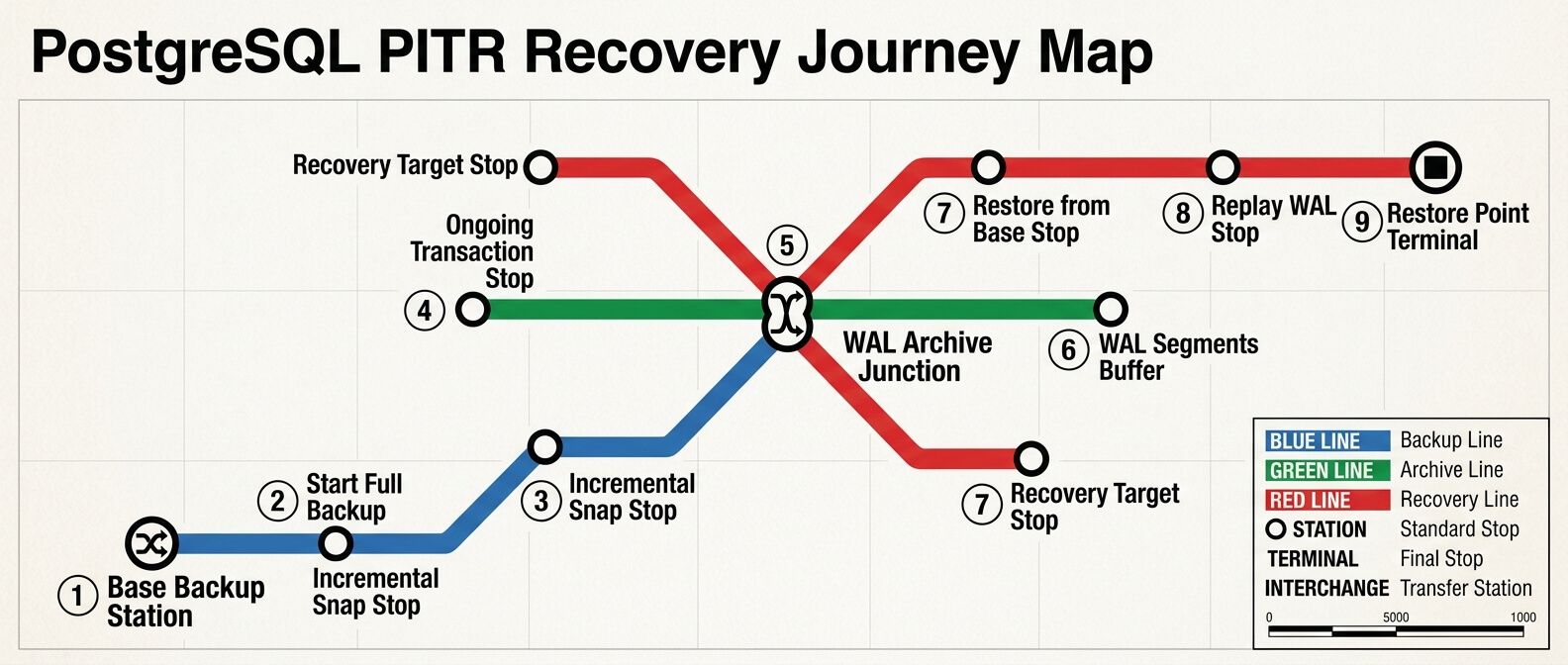
PITR - это механизм восстановления PostgreSQL не просто из последней копии, а на выбранный момент времени. Например, есть интернет-магазин. В 14:37 администратор случайно запускает SQL-запрос без WHERE и меняет цены у всех товаров. Последний ночной backup был в 03:00. Если восстановиться только из него, потеряются заказы, регистрации, изменения остатков и платежные события за половину дня. С PITR сценарий другой: вы берёте base backup, подключаете архив WAL и говорите PostgreSQL: “восстановись до 14:36:50”. База возвращается в состояние за несколько секунд до ошибки. Не в идеальном мире, а в нормальной рабочей практике.

Из чего состоит PITR
У PITR есть три ключевых элемента
• Base backup - базовая физическая копия всего кластера PostgreSQL.
• WAL-архивация - сохранение журналов изменений, которые PostgreSQL пишет во время работы.
• Recovery target - точка, до которой нужно “докрутить” базу при восстановлении.
Это похоже на сохранение в игре. Base backup - это крупная контрольная точка. WAL - все действия после неё. Recovery target - момент, в который вы хотите вернуться. Если есть только base backup, вы можете восстановить базу только на момент этой копии. Если есть только WAL без base backup, их не к чему применить. Работает именно связка.
Три элемента PITR
Base backup + WAL-архив + recovery target.
Почему обычного backup не всегда хватает
Многие команды начинают с pg_dump, и это нормально. Логический dump удобен, понятен и часто спасает в небольших проектах. Но как только база становится активной, а цена простоя и потери данных растёт, у dump появляются ограничения. pg_dump делает логическую копию: SQL-структуру, данные, объекты базы. Это хорошо для переноса, частичного восстановления, миграций и небольших инсталляций. Но он не даёт точного восстановления на произвольный момент времени. Представим SaaS-сервис. Ночью в 02:00 создаётся dump. В 11:20 разработчик выкатывает миграцию, которая повреждает часть данных. Если откатиться на ночной dump, пропадут все действия пользователей с 02:00 до 11:20. Для бизнеса это может быть хуже самой ошибки. PITR решает именно эту проблему. Он позволяет восстановить физическое состояние базы до момента перед инцидентом.
pg_dump vs PITR
Фотография утром vs видео с паузой за секунду до ошибки.
WAL: сердце восстановления на точку времени
WAL расшифровывается как Write-Ahead Log. Это журнал, куда PostgreSQL записывает изменения до того, как они окончательно попадут в файлы данных. Можно представить WAL как бортовой журнал корабля. Даже если часть данных ещё не “осела” на диск в привычном виде, PostgreSQL уже знает, какие изменения происходили и в каком порядке. Именно поэтому WAL важен для отказоустойчивости, репликации и восстановления. Когда включена WAL-архивация, PostgreSQL не просто использует WAL внутри каталога pg_wal, а дополнительно отправляет завершённые WAL-сегменты в отдельное хранилище: локальную директорию, другой диск, сетевое хранилище или объектное хранилище.
Почему WAL нужно архивировать отдельно
Каталог pg_wal не предназначен для долгосрочного хранения всей истории. PostgreSQL переиспользует и удаляет старые WAL-сегменты, когда они больше не нужны текущему серверу. Если надеяться только на pg_wal, однажды вы обнаружите неприятную вещь: нужных файлов уже нет. А без непрерывной цепочки WAL восстановление на нужный момент невозможно. Поэтому WAL-архив должен жить отдельно от основного кластера. И желательно не на том же диске, где лежит база. Если диск с базой умер, а WAL-архив был на нём же, формально backup-процесс был. Практически - спасать уже нечего.
WAL-архивация
pg_wal переиспользуется; архив — отдельное хранилище.
Base backup: точка старта для восстановления
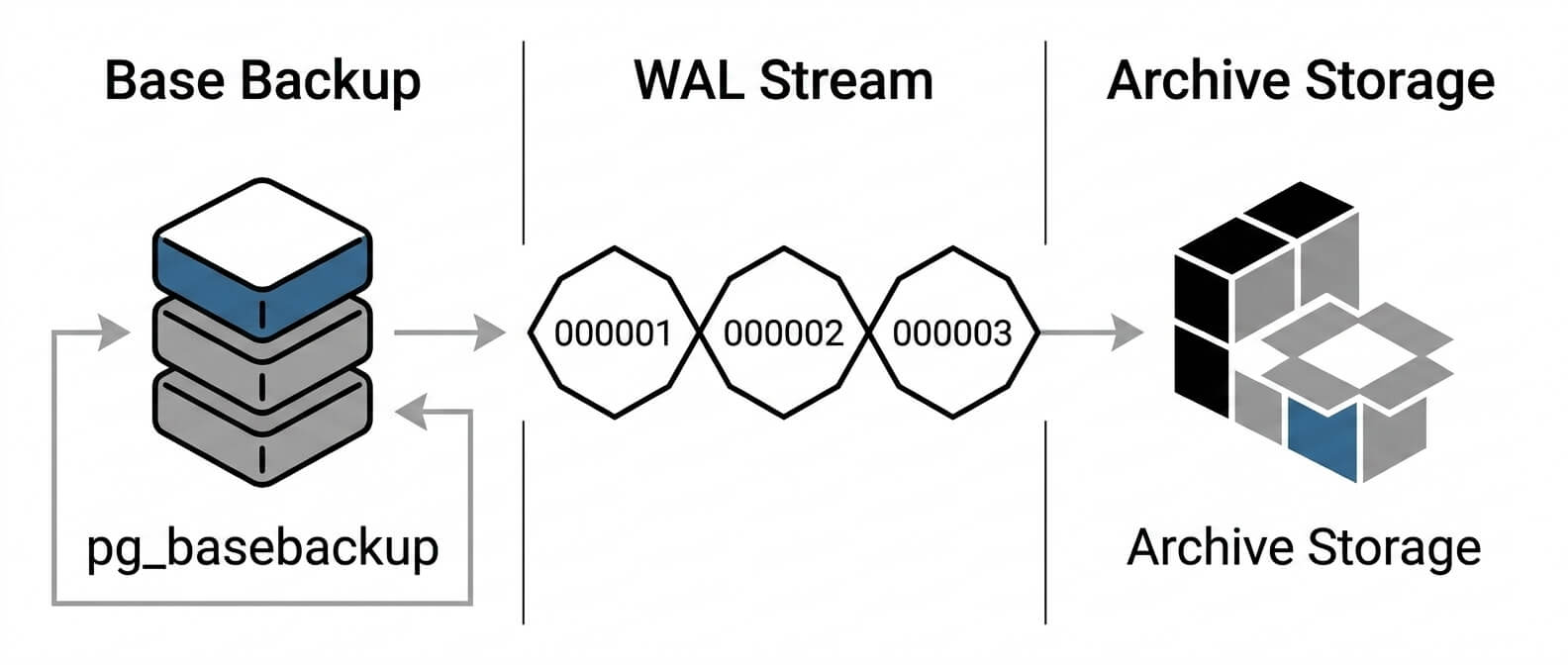
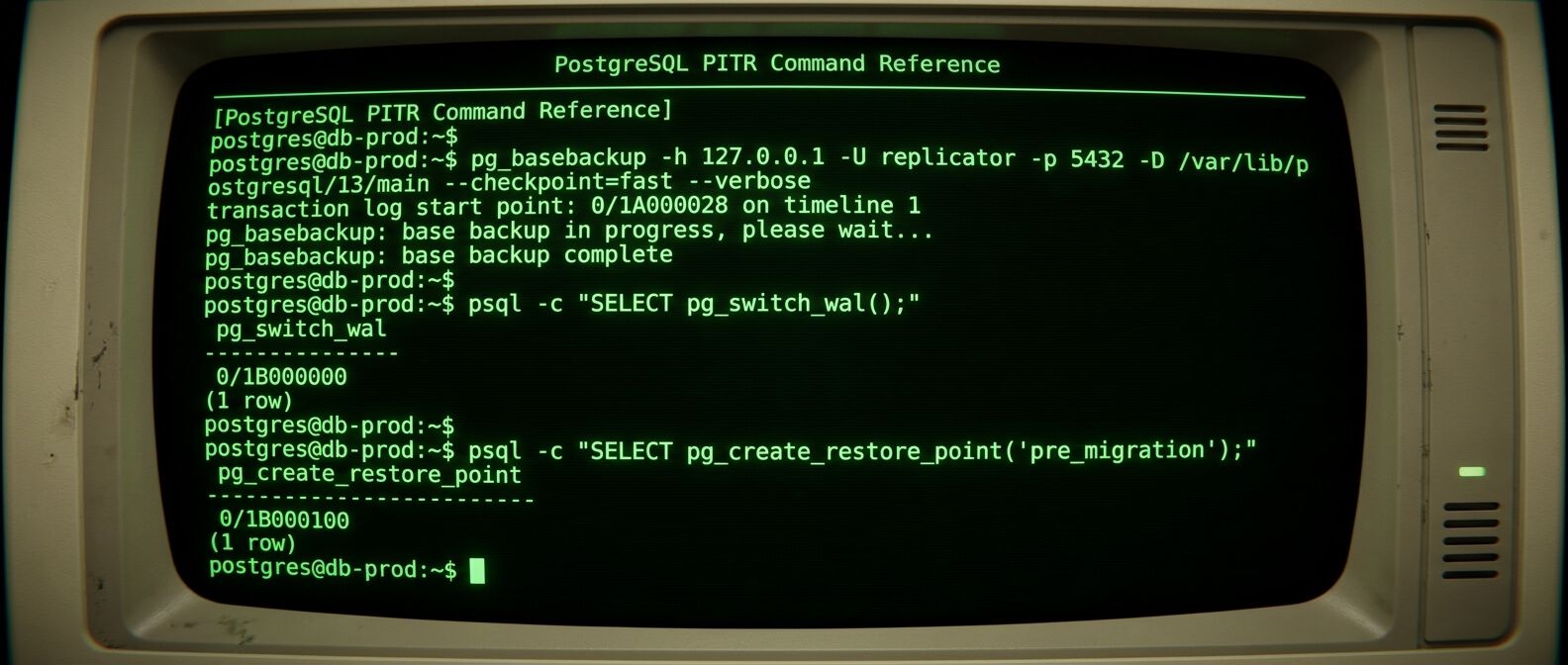
Base backup - это физическая копия всего PostgreSQL-кластера. Не одной базы, не одной схемы, не отдельных таблиц, а всего data directory со всеми системными файлами, базами, настройками хранения и служебными данными. Для создания base backup обычно используют pg_basebackup. Он умеет делать копию работающего сервера без остановки PostgreSQL и корректно переводит сервер в режим backup на время операции. Пример команды: pg_basebackup \ -h 127.0.0.1 \ -U replicator \ -D /backups/postgresql/base/2026-06-18 \ -Fp \ -Xs \ -P
Что здесь происходит
• -h 127.0.0.1 - сервер PostgreSQL
• -U replicator - пользователь с правом репликации
• -D - каталог, куда сохраняется backup
• -Fp - обычный plain-формат
• -Xs - WAL передаются потоком во время backup
-P - показывает прогресс. В production часто используют tar-формат и сжатие, например: pg_basebackup \ -h 127.0.0.1 \ -U replicator \ -D /backups/postgresql/base/2026-06-18 \ -Ft \ -z \ -Xs \ -P Такой backup проще хранить, передавать и ротировать.
Важный момент про весь кластер
pg_basebackup копирует весь кластер PostgreSQL. Если у вас на одном инстансе несколько баз данных, они попадут в backup вместе. Это не инструмент для выборочного восстановления одной таблицы или одной базы. Для выборочного логического восстановления лучше подходит pg_dump или pg_restore. Для восстановления инфраструктурного состояния всего PostgreSQL - base backup и PITR.
Чем PITR отличается от dump и snapshot
Backup-стратегия часто ломается не из-за отсутствия копий, а из-за неверного понимания, что именно умеет конкретный тип backup.
PITR против pg_dump
pg_dump создаёт логическую копию данных. Она удобна, когда нужно перенести базу между версиями PostgreSQL, восстановить отдельную схему, сохранить структуру и данные в переносимом формате. Но pg_dump не знает, что происходило между двумя запусками. Если dump делается раз в сутки, между этими точками остаётся большой “слепой коридор”. PITR работает иначе. Он берёт физическую базовую копию и применяет WAL-записи до выбранного момента. Поэтому можно восстановиться не только “на 03:00”, а, например, “на 14:36:50”. Мини-пример:pg_dump похож на фотографию комнаты утром. PITR похож на видеозапись, где можно остановиться за секунду до того, как кто-то уронил вазу.
PITR против snapshot
Snapshot на уровне диска или гипервизора фиксирует состояние файловой системы на конкретный момент. Это быстро и удобно, особенно на VPS или выделенных серверах с поддержкой snapshot-инструментов. Но snapshot сам по себе обычно даёт только точку восстановления. Если snapshot сделан в 10:00, а ошибка произошла в 16:00, вернуть базу на 15:59 он не сможет. Кроме того, snapshot должен быть консистентным для PostgreSQL. Нельзя бездумно копировать файлы работающей базы и надеяться, что всё поднимется корректно. В идеале snapshot используют вместе с механизмами PostgreSQL, а не вместо них. PITR закрывает другой уровень задачи: он позволяет двигаться по истории изменений после base backup.
Когда использовать всё вместе
На практике зрелая схема часто сочетает несколько подходов
• pg_dump - для логических копий, миграций и точечного восстановления объектов
• snapshots - для быстрого инфраструктурного отката
• PITR - для восстановления кластера на конкретный момент
• репликация - для высокой доступности, но не как замена backup.
• Репликация, кстати, не спасает от логической ошибки. Если кто-то удалил таблицу на primary, это удаление быстро уедет на standby. Backup должен быть независимым от текущей ошибки, иначе он просто честно сохранит проблему.
Что нужно подготовить перед настройкой PITR
Перед включением PITR стоит спокойно пройтись по инфраструктуре. Это не сложный механизм, но он не любит импровизацию.
Проверьте
• где находится data directory PostgreSQL
• какой объём занимает кластер
• сколько WAL генерируется за час и за сутки
• где будут храниться base backups
• где будут храниться WAL-архивы
• сколько времени вы готовы хранить backup-цепочку
• как быстро нужно восстановиться при аварии.
Эти вопросы звучат скучно, пока не случается инцидент. Потом они внезапно становятся главными.
RPO и RTO: две метрики, которые стоит назвать вслух
Для backup-политики важны две метрики. RPO - сколько данных допустимо потерять. Например, 5 минут, 1 час или 24 часа. RTO - за сколько времени нужно восстановить сервис. Например, 15 минут, 2 часа или рабочий день. PITR помогает снизить RPO, потому что WAL-архивы позволяют восстановиться почти к нужной точке. Но RTO зависит от размера базы, скорости дисков, доступности backup-хранилища и того, насколько хорошо вы отрепетировали восстановление. Если база весит 800 ГБ, а backup лежит в медленном удалённом хранилище, сама технология PITR не сделает чудо. Ей нужна нормальная инфраструктура.
Настройка WAL-архивации в PostgreSQL
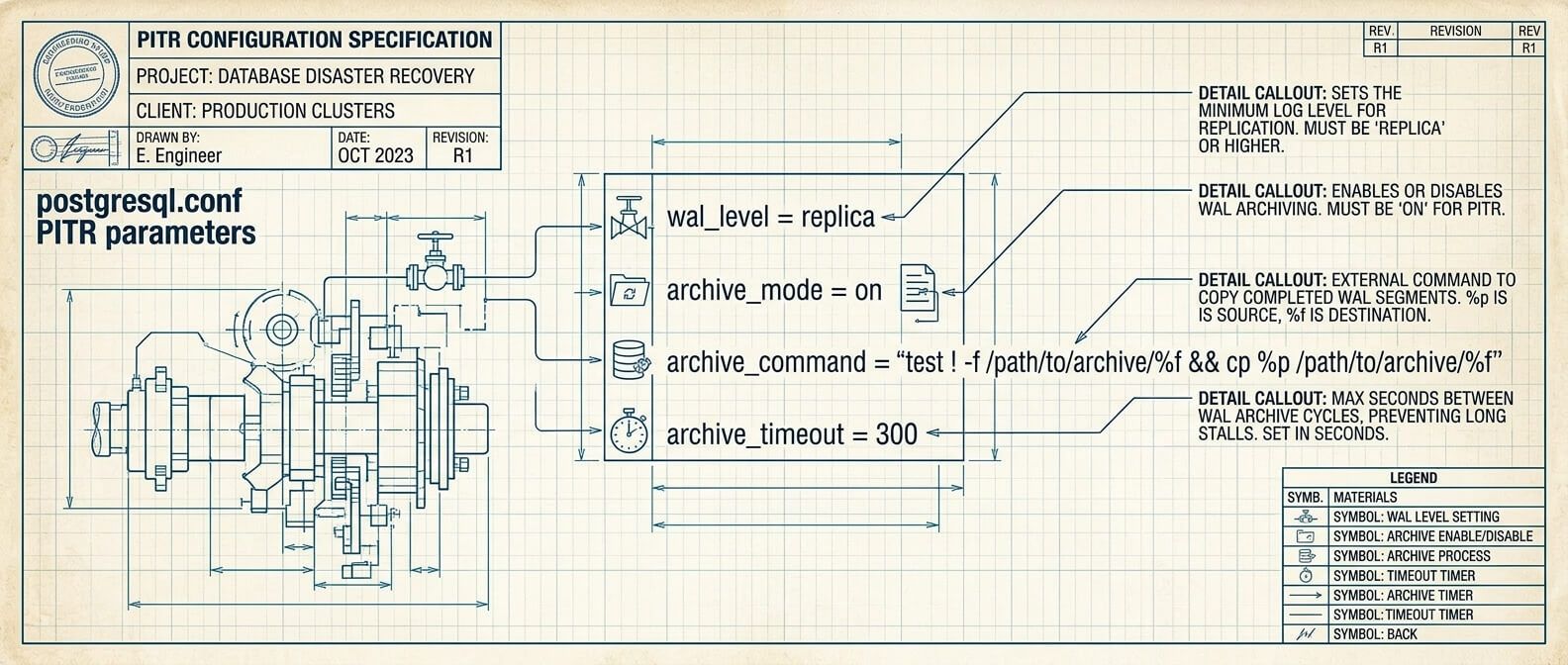
Для начала нужно включить архивацию WAL. Настройки обычно находятся в postgresql.conf. Базовый пример: wal_level = replicaarchive_mode = onarchive_command = 'test ! -f /var/lib/postgresql/wal_archive/%f && cp %p /var/lib/postgresql/wal_archive/%f'archive_timeout = 300 Разберём по частям.
wal_level
wal_level = replica Для PITR нужен уровень WAL, который содержит достаточно информации для восстановления. Обычно используют replica. Это стандартный выбор для архивации и репликации.
archive_mode
archive_mode = on Эта настройка включает режим архивации WAL. После изменения обычно требуется перезапуск PostgreSQL.
archive_command
archive_command = 'test ! -f /var/lib/postgresql/wal_archive/%f && cp %p /var/lib/postgresql/wal_archive/%f' Это команда, которую PostgreSQL выполняет для каждого готового WAL-сегмента. Здесь: %p - путь к WAL-файлу внутри PostgreSQL; %f - имя файла; test ! -f ... - защита от перезаписи уже сохранённого WAL; cp - копирование в архивную директорию. Для тестового стенда такой вариант понятен. Для production лучше использовать более надёжный способ: rsync, scp, aws s3 cp, rclone, специализированный backup-инструмент или скрипт с проверкой ошибок. Главное правило: archive_command должен завершаться с кодом 0 только тогда, когда WAL действительно сохранён. Если команда “притворилась успешной”, PostgreSQL может удалить WAL, который на самом деле не попал в архив. Это тихая катастрофа.
archive_timeout
archive_timeout = 300 PostgreSQL архивирует WAL-сегмент, когда он заполнен. На тихой базе это может происходить редко. archive_timeout заставляет сервер закрывать текущий WAL-сегмент через заданное время, даже если он не заполнен. Например, 300 секунд - это 5 минут. Такой параметр может уменьшить потенциальную потерю данных при аварии, но увеличит количество WAL-файлов. Баланс зависит от нагрузки и требований к RPO.
Создаём пользователя для base backup
Для pg_basebackup нужен пользователь с правом репликации. Создать его можно так: CREATE ROLE replicator WITH REPLICATION LOGIN PASSWORD 'strong_password_here'; Также нужно разрешить подключение в pg_hba.conf. Пример для локальной сети: host replication replicator 10.0.0.0/24 scram-sha-256 После изменения конфигурации примените reload: systemctl reload postgresql Или через SQL: SELECT pg_reload_conf(); Не используйте слабый пароль и не открывайте replication-доступ на весь интернет. Пользователь с replication-правами получает доступ к физическому потоку данных. Это не та дверь, которую стоит оставлять приоткрытой.
Проверяем, что WAL действительно архивируется
После изменения настроек нужно убедиться, что архив работает. Можно принудительно переключить WAL: SELECT pg_switch_wal(); Затем проверьте каталог архива: ls -lh /var/lib/postgresql/wal_archive/ Если файл появился, это хороший знак. Но одного файла мало. Проверьте логи PostgreSQL: нет ли ошибок archive command failed. Также полезно посмотреть статистику архивации: SELECT archived_count, last_archived_wal, last_archived_time, failed_count, last_failed_wal, last_failed_timeFROM pg_stat_archiver; Если failed_count растёт, проблему нельзя откладывать. WAL-архив - это цепь. Один пропущенный сегмент может испортить восстановление после него. Практический вопрос к себе: вы уверены, что заметите сбой архивации не через неделю, а в день возникновения? Если нет, добавьте мониторинг.
Делаем base backup
Когда WAL-архивация настроена и проверена, можно создавать base backup. Пример: mkdir -p /backups/postgresql/base/2026-06-18pg_basebackup \ -h 127.0.0.1 \ -U replicator \ -D /backups/postgresql/base/2026-06-18 \ -Fp \ -Xs \ -P После завершения проверьте, что backup действительно создан: du -sh /backups/postgresql/base/2026-06-18ls -la /backups/postgresql/base/2026-06-18 Если используете tar-формат: pg_basebackup \ -h 127.0.0.1 \ -U replicator \ -D /backups/postgresql/base/2026-06-18 \ -Ft \ -z \ -Xs \ -P Вы получите архивы, которые удобно переносить в отдельное хранилище.
Где хранить base backup
Минимальный здравый вариант - не хранить единственную копию на том же диске, где работает PostgreSQL.
Лучше
• отдельный диск на том же сервере как быстрый локальный слой
• удалённый сервер backup-хранилища
• объектное хранилище
комбинация локального и удалённого хранения. Если сервер потерян полностью, backup на его единственном диске не поможет. Это простая мысль, но она регулярно всплывает уже после аварии.
Шаги PITR recovery
Stop → base backup → recovery.signal → restore_command → verify.
Retention: сколько хранить base backup и WAL
Retention - это политика хранения резервных копий и WAL-архивов. Она отвечает на вопрос: что можно удалить, а что ещё нужно для восстановления. Самая частая ошибка: удалить старые WAL раньше времени. Base backup без нужной WAL-цепочки может восстановить только состояние на момент самой копии или вообще оказаться бесполезным для нужной точки.
Простая логика retention
Допустим: base backup делается каждый день в 02:00; WAL архивируются постоянно; нужно иметь возможность восстановиться за последние 7 дней.
Тогда нужно хранить
• base backups минимум за этот период
все WAL, которые нужны для восстановления от самого раннего сохранённого base backup до текущего момента. Нельзя удалить WAL за понедельник, если вы ещё хотите восстановиться из base backup понедельника на среду. История должна быть непрерывной.
Пример политики
Для небольшого проекта можно начать так
• ежедневный base backup
• WAL-архивы хранятся 7 дней
• еженедельный backup хранится 4 недели
• ежемесячный backup хранится 3-6 месяцев
• раз в месяц выполняется тестовое восстановление.
Для нагруженной базы retention считают аккуратнее. Важны объём WAL в сутки, стоимость хранения, требования бизнеса и скорость восстановления. Пример: база весит 150 ГБ, но WAL генерирует 80 ГБ в день. За неделю получится 150 ГБ base backup плюс сотни гигабайт WAL. Это нормально, если бизнесу нужен PITR. Но это нужно планировать заранее, а не обнаруживать по заполненному диску.
Как выполнить восстановление PostgreSQL на нужную точку времени

Теперь главное: как выглядит сам процесс PITR. Предположим, ошибка произошла 18 июня 2026 года в 14:37:10. Нужно восстановиться на 14:37:00. Важно: восстановление лучше сначала делать на отдельный сервер или в отдельный каталог. Не затирайте production-кластер, пока не убедились, что восстановленная база корректна.
Шаг 1. Остановите PostgreSQL на сервере восстановления
systemctl stop postgresql Если это тестовый сервер, убедитесь, что старый data directory не нужен. Если нужен, переименуйте его: mv /var/lib/postgresql/16/main /var/lib/postgresql/16/main.oldmkdir -p /var/lib/postgresql/16/main Путь зависит от дистрибутива и версии PostgreSQL. На Debian/Ubuntu он часто выглядит как /var/lib/postgresql/16/main, на других системах может быть /var/lib/pgsql/16/data.
Шаг 2. Разверните base backup
Если backup был в plain-формате, можно скопировать каталог: rsync -a /backups/postgresql/base/2026-06-18/ /var/lib/postgresql/16/main/ Если backup был в tar-формате: tar -xzf base.tar.gz -C /var/lib/postgresql/16/main/ Проверьте владельца файлов: chown -R postgres:postgres /var/lib/postgresql/16/mainchmod 700 /var/lib/postgresql/16/main
Шаг 3. Настройте recovery
В современных версиях PostgreSQL для запуска восстановления создают файл recovery.signal в data directory. touch /var/lib/postgresql/16/main/recovery.signalchown postgres:postgres /var/lib/postgresql/16/main/recovery.signal Дальше нужно указать параметры восстановления в postgresql.conf или через отдельный конфигурационный файл, если у вас так организованы настройки. Пример: restore_command = 'cp /var/lib/postgresql/wal_archive/%f %p'recovery_target_time = '2026-06-18 14:37:00+00'recovery_target_action = 'pause' restore_command говорит PostgreSQL, где брать WAL-файлы. recovery_target_time задаёт момент восстановления. recovery_target_action = 'pause' означает, что PostgreSQL дойдёт до нужной точки и остановит replay, не переводя сервер сразу в обычный режим. Это удобно для проверки: можно посмотреть данные, убедиться, что выбран правильный момент, и только потом продолжить. Если время указывается в UTC, убедитесь, что вы не ошиблись с часовым поясом. Ошибка на один час при PITR выглядит особенно обидно: технология сработала, но человек выбрал не тот момент.
Шаг 4. Запустите PostgreSQL
systemctl start postgresql Проверьте логи. PostgreSQL должен начать читать WAL через restore_command и применять изменения до целевой точки. В логах обычно видно, до какого момента дошло восстановление и почему оно остановилось.
Шаг 5. Проверьте данные
Подключитесь к базе: psql -h 127.0.0.1 -U postgres Проверьте критичные таблицы, записи, время последней корректной операции. Например: SELECT now();SELECT *FROM ordersORDER BY created_at DESCLIMIT 10; Если вы восстанавливались после ошибочного SQL-запроса, проверьте, что повреждённых изменений ещё нет, а полезные данные до инцидента уже есть.
Шаг 6. Завершите recovery
Если база восстановлена в нужное состояние и recovery_target_action был pause, можно продолжить: SELECT pg_wal_replay_resume(); После завершения recovery сервер станет обычным primary-кластером. С этого момента его история WAL пойдёт в новую сторону. Не пытайтесь “слить” её обратно с прежним production без отдельного плана.
Шаги PITR recovery
Stop → base backup → recovery.signal → restore_command → verify.
Как выбрать правильную точку восстановления
Самая сложная часть PITR часто не техническая. Команды умеют настроить WAL, сделать base backup, поднять сервер. А потом возникает вопрос: “На какое время восстанавливаемся?” Если ошибка произошла в 14:37:10, не всегда нужно брать 14:37:09. Возможно, транзакция началась раньше. Возможно, приложение писало некорректные данные несколько минут. Возможно, ошибочный cron стартовал в 14:35.
Поэтому полезно хранить
• логи приложения
• логи PostgreSQL
• audit trail для критичных операций
• время деплоев
• историю миграций
метки релизов. PITR даёт инструмент, но точку выбирает человек. Чем лучше наблюдаемость, тем меньше гадания.
Restore point вместо времени
PostgreSQL позволяет создавать именованные restore point. Это удобно перед рискованными операциями: миграциями, массовыми изменениями, обновлениями приложения. Пример: SELECT pg_create_restore_point('before_price_migration_2026_06_18'); Потом при восстановлении можно использовать не время, а имя: recovery_target_name = 'before_price_migration_2026_06_18'recovery_target_action = 'pause' Это как поставить яркую закладку в истории базы: “сюда можно вернуться”. Не стоит создавать restore point на каждое мелкое действие. Но перед крупными изменениями это очень полезная привычка.
Тест восстановления: backup без теста ещё не backup
Самая опасная фраза в администрировании: “backup должен работать”. Должен - не значит работает. PITR нужно регулярно проверять на отдельном сервере. Не в день аварии, не во время ночного инцидента, не под давлением менеджмента. Спокойно, по расписанию.
Что проверять
Минимальный тест восстановления должен отвечать на несколько вопросов: base backup разворачивается без ошибок; WAL-архив доступен; цепочка WAL непрерывна; restore_command работает; база стартует после recovery; нужные таблицы читаются; приложение может подключиться к восстановленной базе; команда понимает, сколько времени занял процесс. Даже простой тест раз в месяц резко повышает уверенность. Вы уже знаете команды, пути, узкие места и примерное время восстановления.
Мини-сценарий теста
Поднимите отдельный сервер или временную виртуальную машину. Скопируйте последний base backup. Подключите WAL-архив. Восстановитесь на точку “час назад”. Проверьте данные. Запишите фактическое время восстановления. Обновите инструкцию, если нашли расхождения. Документация, написанная после реального теста, всегда лучше красивого регламента, который никто не выполнял.
Типичные ошибки при настройке PITR
PITR достаточно надёжен, если настроен аккуратно. Но у него есть несколько ловушек.
WAL архивируется на тот же диск
Это удобно до первой аварии. Потом выясняется, что вместе с data directory потерян и WAL-архив. Лучше хранить WAL отдельно. Если используется локальный диск, добавьте удалённую копию. Если используется объектное хранилище, проверьте права доступа и скорость скачивания. archive_command не проверяет результат Команда копирования должна честно сообщать PostgreSQL, удалось сохранить WAL или нет. Плохой скрипт может возвращать успешный код даже при ошибке. Внешне всё будет спокойно, но восстановление потом оборвётся. Добавьте проверку, логирование и мониторинг.
Нет мониторинга pg_stat_archiver
Если failed_count растёт, нужно реагировать быстро. Сбой WAL-архивации нельзя оставлять “до понедельника”. Чем дольше проблема живёт, тем больше риск потерять возможность PITR.
Retention удаляет нужные WAL
Автоматическая очистка backup-хранилища должна понимать зависимость между base backup и WAL. Нельзя удалять WAL только по принципу “старше 3 дней”, если они ещё нужны для сохранённых base backup.
Восстановление никогда не тестировали
Это классика. Backup есть, скрипты есть, директории есть, уверенность есть. А при проверке оказывается, что пароль не подходит, WAL лежат не там, команда восстановления не работает, а инструкция написана для старой версии PostgreSQL. Тест занимает время. Но авария без теста занимает больше.
Перепутали часовой пояс
recovery_target_time чувствителен к времени. Если инфраструктура живёт в UTC, приложение показывает локальное время, а команда в чате пишет “около трёх”, легко ошибиться. Для инцидентов фиксируйте точное время с часовым поясом. Например: 2026-06-18 14:37:00+00.
Где запускать восстановление: на production или отдельно
В большинстве случаев безопаснее восстанавливаться на отдельный сервер. Это может быть VPS, временный выделенный сервер, тестовая машина или отдельный каталог на изолированном окружении.
Почему так лучше
• production-данные не затираются до проверки
• можно выбрать точку восстановления без спешки
• можно сравнить старую и восстановленную базу
проще выгрузить только нужные данные, если полный откат не требуется. Иногда после PITR не нужно заменять весь production-кластер. Например, пользователь удалил важные записи из одной таблицы. Вы можете восстановить базу на отдельном сервере, выгрузить нужные строки и аккуратно вернуть их в production. PITR в таком сценарии становится не кнопкой “откатить всё”, а инструментом расследования и точечного спасения.
PITR и инфраструктура: что важно на VPS и выделенном сервере
PostgreSQL часто работает на VPS или dedicated server, где администратор сам отвечает за storage, backup, firewall и мониторинг. Это даёт гибкость, но требует дисциплины. Обратите внимание на несколько вещей.
Диск под WAL и backup
WAL может расти быстро. Если архивная директория заполнит диск, PostgreSQL начнёт испытывать проблемы. На production это может привести к остановке записи или деградации сервиса. Лучше заранее выделить отдельный раздел или отдельный диск под backup-процессы. И обязательно настроить alert по свободному месту.
Сеть до backup-хранилища
Если WAL отправляются на удалённый сервер, сеть становится частью backup-системы. При сбое сети archive_command может начать падать, а WAL будут накапливаться локально. Проверьте, что сервер выдерживает временную недоступность хранилища. Иногда помогает очередь, повторные попытки, локальный буфер и отдельный процесс отправки.
Права доступа
Backup содержит все данные базы. WAL тоже может содержать чувствительную информацию. Не храните архивы в директории, доступной случайным пользователям или веб-серверу.
Минимум
• отдельный системный пользователь
• закрытые права на каталог
• шифрование при передаче
• шифрование в хранилище
• регулярная проверка доступа.
Автоматизация
Ручной backup хорош только для первого теста. Дальше процесс должен быть автоматизирован.
Обычно автоматизируют
• создание base backup
• отправку WAL
• проверку ошибок архивации
• очистку по retention
• тестовое восстановление
• уведомления в мониторинг.
Можно написать собственные скрипты, но для production часто удобнее использовать специализированные инструменты: pgBackRest, Barman, WAL-G. Они помогают управлять WAL, retention, сжатием, проверками и восстановлением. Но даже с ними важно понимать базовый принцип PITR, иначе инструмент превращается в чёрный ящик.
Минимальный чек-лист настройки PostgreSQL PITR
Перед тем как считать задачу закрытой, пройдитесь по короткому чек-листу.
Настройка
• WAL-архивация включена.
• archive_command сохраняет WAL в отдельное хранилище.
• Ошибки архивации мониторятся.
• Создан пользователь для pg_basebackup.
• Доступы ограничены и защищены.
• Base backup создаётся по расписанию.
• WAL-архивы не удаляются раньше нужного срока.
• Retention учитывает связь base backup и WAL.
Восстановление
• Есть инструкция восстановления.
• В инструкции указаны реальные пути.
• Тестовое восстановление выполнялось хотя бы один раз.
• Известно примерное время восстановления.
• Команда понимает, как выбрать recovery_target_time.
• Проверено восстановление на отдельный сервер.
• Есть план действий после successful recovery.
Контроль
• Проверяется свободное место.
• Проверяется pg_stat_archiver.
• Логи backup-процесса сохраняются.
• Уведомления приходят ответственным людям.
• Backup-хранилище защищено.
• Старые backup удаляются по понятной политике.
Чек-лист простой, но именно он отделяет “у нас вроде есть backup” от “мы действительно можем восстановиться”.
Практический пример: ошибка после миграции

Представим типичную ситуацию. В 12:00 команда выкатила новую версию приложения. В 12:08 стало видно, что миграция некорректно пересчитала статусы заказов. В 12:15 разработчики остановили запись и подтвердили проблему.
Что делать с PITR
• Найти точное время начала опасной миграции, например 2026-06-18 12:03:20+00.
• Поднять отдельный сервер восстановления.
• Развернуть последний base backup до этого времени.
• Указать recovery_target_time = '2026-06-18 12:03:19+00'.
• Запустить recovery.
Проверить таблицы заказов. Принять решение: полный откат production или точечная выгрузка корректных данных. Без PITR выбор был бы хуже: либо откатиться на ночной backup и потерять часы нормальных операций, либо вручную чинить повреждённые данные, надеясь ничего не пропустить. PITR не отменяет анализа инцидента, но даёт пространство для нормального решения.
Пример: ошибка после миграции
12:00 deploy → 12:08 проблема → recovery на 12:03:19.
PITR не должен быть единственным планом

Важно не превратить PITR в магическую кнопку. Он решает конкретную задачу: восстановление PostgreSQL на точку времени. Но полноценная стратегия защиты данных шире.
Нужны
• мониторинг базы
• репликация для высокой доступности
• логические dumps для отдельных сценариев
• snapshots для инфраструктурных операций
• проверка целостности backup
• документация
• регулярные fire-drill тесты.
Хорошая backup-стратегия похожа на страховочную систему у альпиниста. Там не один карабин, а несколько уровней защиты. Если один элемент не сработал, остаётся следующий.
Слои защиты данных
PITR — один карабин, не вся страховочная система.
Короткие ответы на частые вопросы
Можно ли настроить PITR без WAL-архивации?
Нет. Для восстановления на точку времени нужна история изменений после base backup. Эту историю дают WAL-файлы. Без архива WAL вы ограничены состоянием base backup.
Можно ли восстановить одну таблицу через PITR?
PITR восстанавливает весь кластер. Но можно восстановить кластер на отдельный сервер, затем выгрузить нужную таблицу или строки и перенести их обратно в production.
Нужно ли останавливать PostgreSQL для base backup?
При использовании pg_basebackup останавливать сервер не нужно. Инструмент предназначен для создания base backup работающего кластера.
Заменяет ли PITR репликацию?
Нет. Репликация помогает при отказе сервера и снижает простой, но не защищает от логических ошибок. Ошибочный DELETE уедет на реплику так же быстро, как полезная транзакция.
Как часто делать base backup?
Зависит от размера базы, скорости восстановления и retention. Часто начинают с ежедневного base backup, но для больших или критичных баз график подбирают индивидуально. Чем реже base backup, тем больше WAL придётся применять при восстановлении.
Где лучше хранить WAL?
На отдельном надёжном хранилище, не зависящем от основного диска PostgreSQL. Хороший вариант - удалённый backup-сервер или объектное хранилище с ограниченными правами доступа.
Итог: PITR стоит настроить до первого серьёзного инцидента

PostgreSQL PITR - один из тех механизмов, о которых лучше вспомнить заранее. Когда база работает спокойно, настройка WAL-архивации, base backup, retention и тестового восстановления кажется технической задачей из списка “потом”. Но в момент ошибки именно она решает, потеряете ли вы часы данных или вернётесь на минуту до инцидента. Сама идея проста: base backup даёт стартовую точку, WAL-архив хранит историю изменений, recovery target выбирает нужный момент. Важно не только включить настройки, но и проверить весь путь восстановления от начала до конца. Если PostgreSQL хранит важные данные, PITR стоит воспринимать не как дополнительную опцию, а как часть нормальной эксплуатации. Настройте архивацию, продумайте retention, проведите тест восстановления и держите инструкцию под рукой. В спокойное время это выглядит как аккуратная инженерная работа. В аварийный день - как решение, которое сохранило бизнесу данные, время и нервы.
Итог PITR
Архивация → base backup → retention → тест restore.




