



















Оглавление
- Введение
- Предпосылки и допущения
- MIG и MPS: как работает разделение GPU
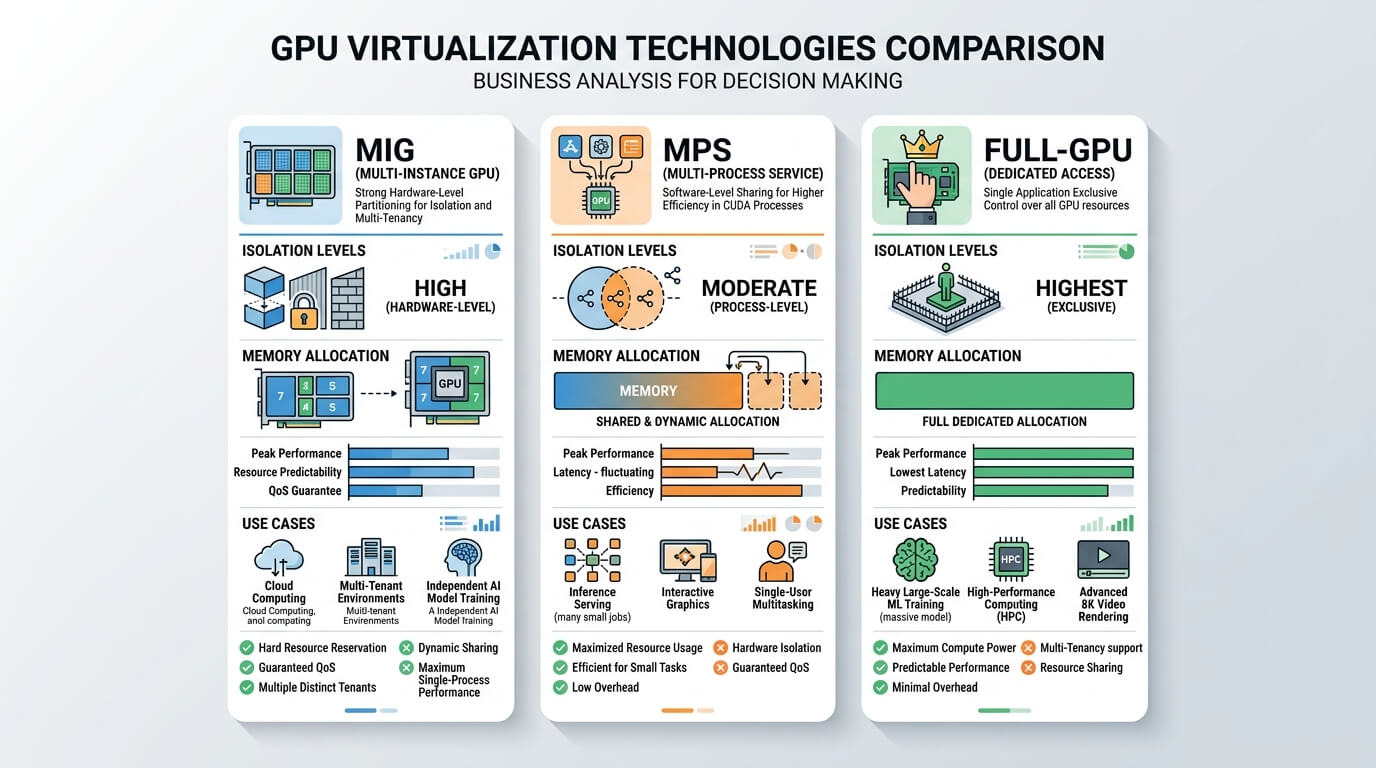
- Сравнение MIG vs MPS vs full-GPU
- Квоты и разделение GPU между командами
- cgroups и «SR‑IOV‑подобные»/виртуализационные решения
- Архитектура multi-tenant GPU в Kubernetes: reference design
- Политика: разделение, SLA, биллинг, безопасность
- Наблюдаемость: метрики, инструменты, алерты и дашборды
- Тестирование, валидация и план внедрения
- Сценарии использования и «как думать о размещении»
- Примеры Kubernetes-манифестов
- Бенчмарки и тестовая нагрузка
- Выбор между MIG и MPS и комбинирование
- План внедрения по шагам
- Чек-лист перед продакшен-запуском
Введение
Multi-tenant GPU — это не «поделить карту пополам», а выстроить систему, где команды получают предсказуемую производительность, понятные лимиты и прозрачный учёт, а платформа при этом не превращается в набор ручных костылей. Аппаратное разбиение (NVIDIA MIG) даёт наиболее жёсткую изоляцию и предсказуемость за счёт выделения фиксированных долей вычислений и памяти и независимых «GPU‑инстансов» внутри одной карты.
CUDA MPS решает другую задачу: повышает утилизацию, позволяя нескольким процессам эффективнее делить один GPU, снижая накладные расходы и улучшая параллелизм (особенно для «мелких» задач и многопроцессных сценариев). В Kubernetes реальная «многопользовательность» складывается из трёх слоёв: 1) как вы физически/логически делите GPU (MIG / full‑GPU / time‑slicing / MPS / виртуализация), 2) как вы ограничиваете потребление между командами (квоты, приоритеты, очереди), 3) как вы всё это наблюдаете и объясняете (метрики, алерты, отчёты, биллинг).
Практическая рекомендация для большинства платформенных команд: держать отдельные «пулы» нод под разные режимы — full‑GPU для training, MIG для inference/интерактива/общих сред и (опционально) time‑slicing как дешёвый режим для нестрогих задач; MPS использовать либо точечно (HPC/многопроцессные пайплайны), либо как эксперимент в Kubernetes с учётом ограничений.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Предпосылки и допущения
Чтобы говорить строго, важно зафиксировать, что именно «делим» и в каких рамках. Ниже — рабочие допущения; если у вас иначе (другой стек/версии), поменяются детали конфигураций и часть ограничений.
Предположим, что используются GPU семейства NVIDIA Ampere/Hopper/новее, поддерживающие MIG (например, A100/A30, H100/H200; профили и ограничения зависят от модели и объёма памяти). Для MIG критичны версия драйвера и ветка CUDA: документация указывает минимальные версии драйверов для разных GPU (например, для A100/A30 — ветка R525 и новее).
Предположим Kubernetes‑кластер, где GPU интегрируются через NVIDIA GPU Operator / NVIDIA device plugin, а наблюдаемость строится на Prometheus + Grafana и NVIDIA DCGM Exporter. Также предполагаем, что вы готовы разделять инфраструктуру по неймспейсам/проектам и управлять политиками через Kubernetes‑квоты и организационные правила (SLA, приоритеты, бюджетирование).
Отдельно: поведение MIG‑режима в части «сохраняется ли после перезагрузки» зависит от поколения GPU. На Ampere MIG‑режим помечается как персистентный через InfoROM (пока вы явно не отключите), а на Hopper+ документация подчёркивает, что MIG‑режим персистентен только пока загружены драйверные модули, и после перезагрузки/перезагрузки модулей его нужно включать заново. При этом сами созданные MIG‑инстансы (GI/CI) не считаются «вечными» и обычно требуют автоматизации восстановления после reset/перезагрузки (типичный инструмент — mig‑parted и/или компоненты GPU Operator).

MIG и MPS: как работает разделение GPU
MIG
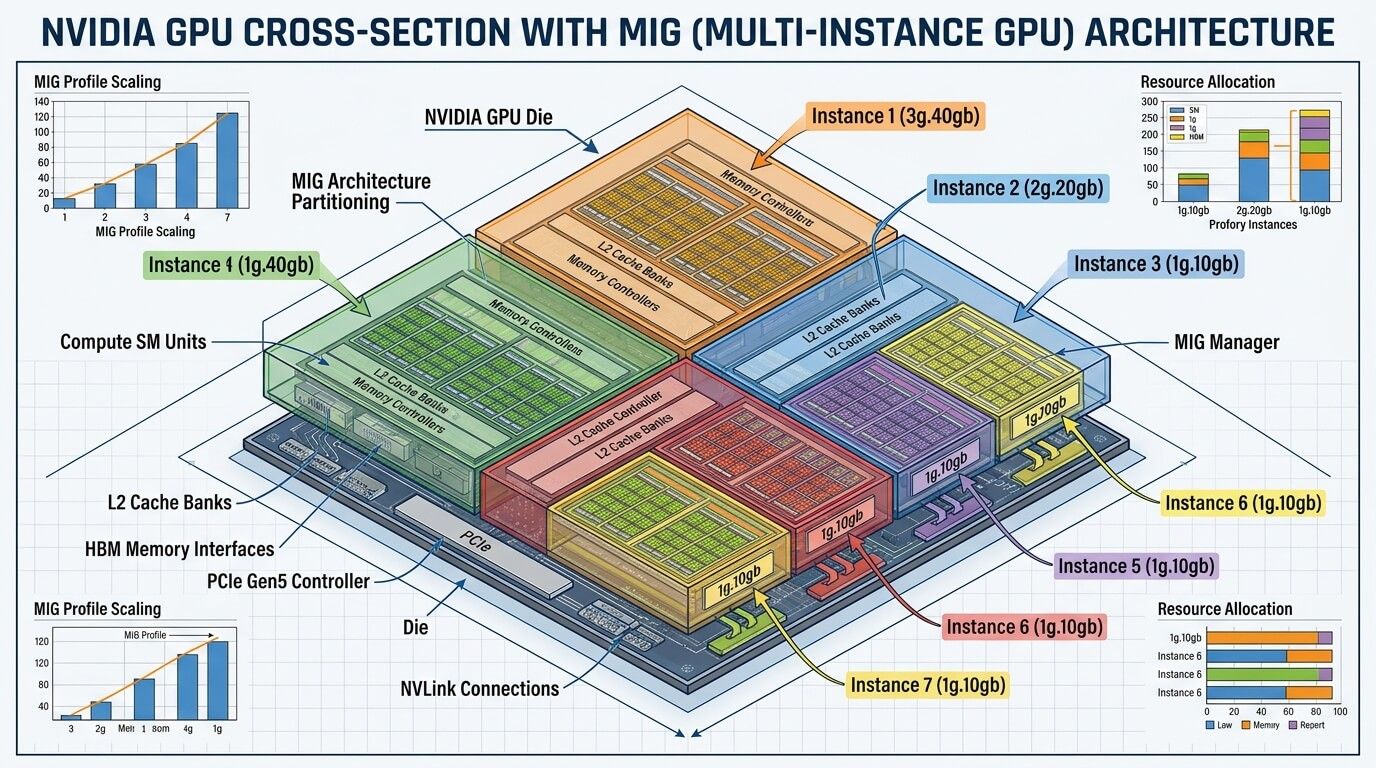
Идея MIG. MIG (Multi‑Instance GPU) делит один физический GPU на несколько изолированных GPU‑инстансов. Каждый инстанс получает выделенную долю вычислительных ресурсов и памяти, а также изоляцию по пути доступа к подсистеме памяти: отдельные порты кроссбара, банки L2, контроллеры памяти и шины DRAM назначаются уникально инстансу. Это ключ к предсказуемой задержке и пропускной способности даже при «шумных соседях».
Слои разбиения: GI и CI. В MIG существуют GPU Instances (GI) и Compute Instances (CI). GI собирается из «слайсов» памяти и «слайсов» вычислений; CI — дополнительное дробление вычислительной части внутри GI: CIs делят двигатели и память родительского GI, но получают выделенные SM‑ресурсы. Практический смысл: GI задаёт «коробку» по памяти/движкам, CI позволяет тоньше делить вычисления, если это нужно под модельные/инференс‑ворклоады.
Профили MIG и примеры геометрии. Доступные профили зависят от конкретной карты и объёма HBM. Например, для A100 40GB типичны профили вроде 1g.5gb, 2g.10gb, 3g.20gb, 7g.40gb, а для A100 80GB — аналогичные по долям, но с большими объёмами памяти (1g.10gb, 2g.20gb, 3g.40gb, 7g.80gb). Важно помнить про «размещение профилей» и фрагментацию: создание/удаление инстансов в разных позициях может приводить к ситуации, когда следующий желаемый профиль «не помещается» из‑за расположения уже созданных инстансов.
Операционная сторона: включение MIG и создание инстансов. На Ampere включение MIG может требовать reset GPU; на Hopper+ reset для включения MIG‑режима уже не требуется, но персистентность режима меняется (см. допущения). Кроме того, reset может блокироваться «клиентами драйвера» — мониторингом/телеметрией (например, DCGM), поэтому при включении MIG иногда приходится останавливать соответствующие сервисы.
Команды для bare‑metal (пример). Ниже — минимальный, «честный» набор команд, который удобно воспроизводить на стенде:
# 1) Проверить состояние MIGnvidia-smi -i 0 --query-gpu=pci.bus_id,mig.mode.current --format=csv# 2) Включить MIG на GPU 0 (на Ampere драйвер может попытаться сделать reset)sudo nvidia-smi -i 0 -mig 1# 3) Посмотреть доступные профили и размещенияsudo nvidia-smi mig -lgipsudo nvidia-smi mig -lgipp# 4) Создать два GI профиля 3g.20gb и сразу создать соответствующие CI (-C)sudo nvidia-smi mig -cgi 9,3g.20gb -C# 5) Посмотреть созданные GPU instancessudo nvidia-smi mig -lginvidia-smi
Семантика -cgi … -C и пример создания двух 3g.20gb показаны в руководстве (включая то, что «просто включить MIG недостаточно — без созданных GI/CI CUDA‑ворклоады не запустятся», и что созданные MIG‑устройства не являются персистентными после reboot/reset).
Kubernetes‑подход к MIG (через GPU Operator). В кластере MIG обычно управляют декларативно: GPU Operator разворачивает MIG Manager, который смотрит на label nvidia.com/mig.config на ноде и применяет нужный профиль, при необходимости останавливая GPU‑поды, меняя геометрию и (в некоторых средах) инициируя reboot. Пример включения MIG‑стратегии при установке:
helm install --wait --generate-name \ -n gpu-operator --create-namespace \ nvidia/gpu-operator \ --version=v26.3.0 \ --set mig.strategy=single
Дальше — назначение профиля на ноду через label, например all-1g.10gb.
MPS
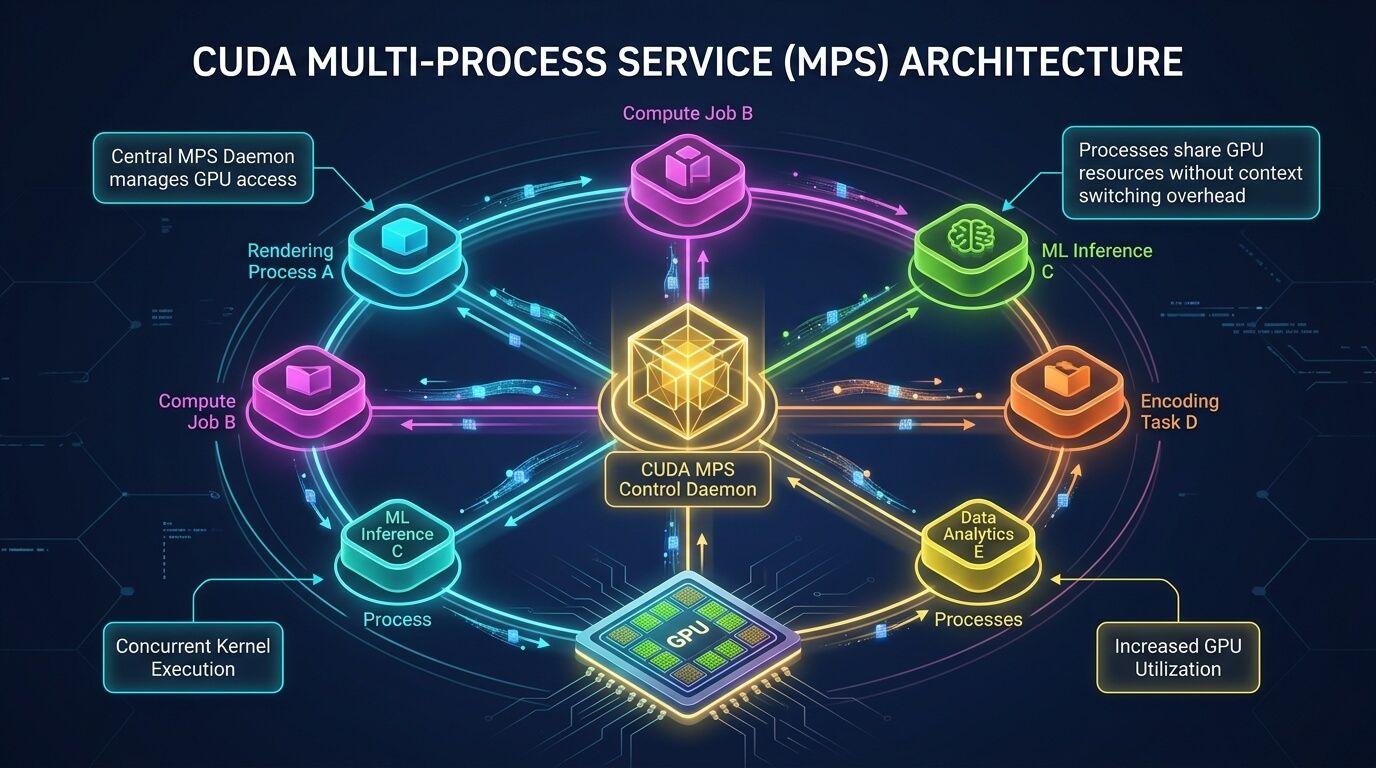
Идея MPS. MPS (Multi‑Process Service) — это runtime‑механизм, который позволяет нескольким CUDA‑процессам эффективнее работать на одном GPU, используя аппаратные возможности параллелизма (например, Hyper‑Q) и снижая накладные расходы от конкурирующих контекстов. Если упрощать до инженерной модели: MPS добавляет «арбитраж» и кооперативный доступ так, чтобы ядра и копирования из разных процессов могли лучше перекрываться, повышая утилизацию и уменьшая время выполнения в сценариях, где один процесс сам по себе не насыщает GPU.
Архитектура в двух процессах: control daemon и server. На Linux MPS обычно запускается как control daemon (nvidia-cuda-mps-control), который управляет MPS server (nvidia-cuda-mps-server) и связывает клиентов. В типичном сценарии указывают, какой GPU видим демону (через CUDA_VISIBLE_DEVICES), и запускают control daemon в фоне.
Почему часто включают EXCLUSIVE_PROCESS. Документация отмечает, что при использовании MPS рекомендуется EXCLUSIVE_PROCESS режим — как гарантия того, что ровно один MPS‑server является единой точкой арбитража для всех процессов на данном GPU.
Базовые команды запуска/остановки (пример).
# Выбрать GPU 0 для MPSexport CUDA_VISIBLE_DEVICES=0# Рекомендуемый режим: EXCLUSIVE_PROCESS (можно задать через nvidia-smi)sudo nvidia-smi -i 0 -c EXCLUSIVE_PROCESS# Запустить control daemon в фонеsudo nvidia-cuda-mps-control -d# (опционально) ограничить долю активных потоков (QoS) для следующих клиентов/серверов# Команды отправляются в интерактивный интерфейс nvidia-cuda-mps-controlecho "set_default_active_thread_percentage 50" | sudo nvidia-cuda-mps-control# Остановить MPSecho "quit" | sudo nvidia-cuda-mps-control
Команды запуска демона и смысл EXCLUSIVE_PROCESS прямо описаны в задачах/рекомендациях по MPS. Интерфейсы set_default_active_thread_percentage / set_active_thread_percentage задокументированы как механизм ограничения активных потоков (на Volta и новее это применяется как QoS‑ограничение).
Ограничения и «тонкие места» MPS. Во‑первых, есть архитектурные лимиты по числу клиентов (классический ориентир — до 48 клиентов на Volta‑классе), и это реально «упирается» в практических деплоях. Во‑вторых, ошибка одного клиента может приводить к деградации/остановке группы клиентов: документация описывает ограниченное error containment на Volta и поведение сервера в состоянии FAULT (ожидание завершения клиентов, отказ новым). В‑третьих, важный нюанс для комбинации: CUDA MPS поддерживается поверх MIG, но максимальное число клиентов уменьшается пропорционально размеру Compute Instance.
Сравнение MIG vs MPS vs full-GPU
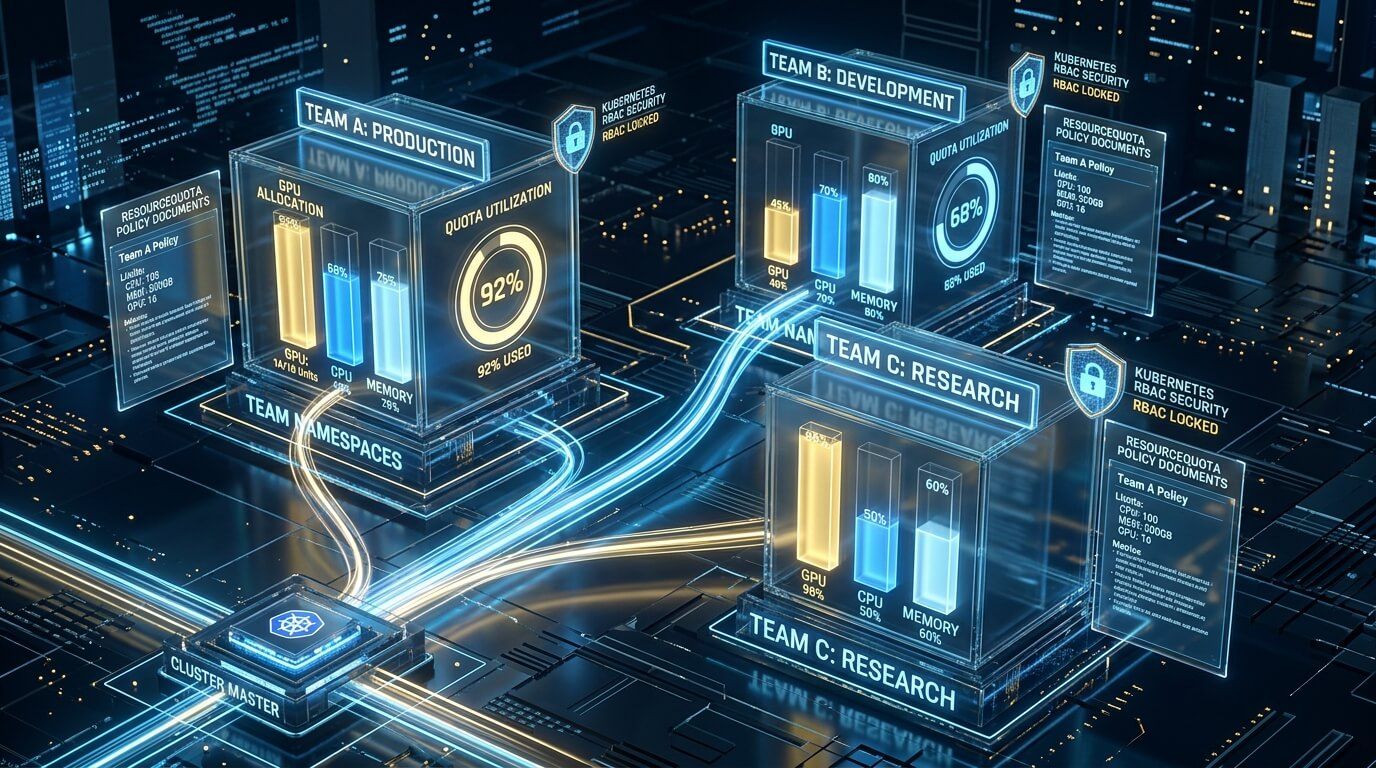
Квоты и разделение GPU между командами
Ключевой момент: «квота» — это не столько про «проценты SM», сколько про право занять ограниченный ресурс. В Kubernetes это реализуется комбинацией (а) объявленных ресурсов на нодах, (б) правил допуска/квот в неймспейсах, (в) политики планирования на уровне нодпулов/лейблов/таинтов и (г) очередей/приоритетов для batch‑нагрузок.
Квоты в Kubernetes на уровне команд/проектов
Самая понятная управленческая модель — неймспейс = проект/команда, а GPU‑лимиты задаются через ResourceQuota на extended resources. Механика ResourceQuota стандартная: при нарушении квоты API‑сервер отклоняет создание/обновление объекта (403) и возвращает сообщение о нарушенном ограничении.
Пример: команда может использовать максимум 4 MIG‑инстанса 1g.10gb (или другой профиль — подставляете свой ресурс):
apiVersion: v1kind: ResourceQuotametadata: name: team-a-gpu-quota namespace: team-aspec: hard: nvidia.com/mig-1g.10gb: "4"
Идея ресурсов вида nvidia.com/mig-<slice>g.<mem>gb — типовая для Kubernetes‑экспонирования MIG.
Тонкость: при time‑slicing / oversubscription вы можете «нарисовать» больше логических GPU‑ресурсов через replicas — и тогда квоты начнут работать по этим логическим штукам, но это не означает гарантию пропорциональной производительности: даже в документации device plugin подчёркивается, что запрос «2 shared‑GPU» не даёт «2× времени».
GPU sharing в Kubernetes: MIG, time‑slicing, MPS
В реальном кластере часто нужен не один, а несколько режимов GPU‑шеринга — потому что training и inference живут по разным законам.
MIG в Kubernetes. Лучший выбор, когда нужны: предсказуемость, изоляция между командами, понятный биллинг «по инстансам». GPU Operator поддерживает MIG Manager, который применяет профили через label nvidia.com/mig.config и управляет жизненным циклом (останавливает GPU‑поды, настраивает геометрию, возвращает компоненты обратно).
Пример применения профиля на ноде:
kubectl label nodes <node-name> nvidia.com/mig.config=all-1g.10gb --overwrite
Состояние отражается label’ами nvidia.com/mig.config.state (pending, success, и т. п.).
Time‑slicing (в Kubernetes). Это «самый дешёвый» путь к oversubscription: device plugin/оператор объявляет несколько «реплик» одного GPU ресурса, а CUDA по сути делит время между процессами. При этом нет изоляции памяти и fault‑domain общий (краш одного может уронить остальных на том же физическом GPU). GPU Operator описывает декларативную настройку через ConfigMap, где задаются replicas и опции вроде renameByDefault и failRequestsGreaterThanOne.
Пример ConfigMap (4 реплики на 1 GPU):
apiVersion: v1kind: ConfigMapmetadata: name: time-slicing-config namespace: gpu-operatordata: any: |- version: v1 flags: migStrategy: none sharing: timeSlicing: renameByDefault: false failRequestsGreaterThanOne: true resources: - name: nvidia.com/gpu replicas: 4
Оператор дополняет ноды лейблами вроде nvidia.com/gpu.replicas=<N> и модифицирует nvidia.com/gpu.product суффиксом -SHARED, что удобно для nodeSelector/affinity. Важный операционный нюанс: конфиг‑мапы time‑slicing оператор автоматически не «подхватывает» — чтобы применить изменения, нужно вручную рестартнуть daemonset device plugin.
MPS‑шаринг в Kubernetes (через device plugin). NVIDIA device plugin описывает MPS‑режим как альтернативу time‑slicing и подчёркивает ограничения: time‑slicing и MPS взаимно исключаются; MPS‑поддержка была отмечена как экспериментальная (по состоянию на указанные версии), и MPS‑шаринг не поддерживается на устройствах с включённым MIG. Это критично для архитектуры: если вы хотите MIG как «песочницы» для команд, то device‑plugin‑MPS как общий механизм шаринга на той же ноде упрётся в ограничение.
Мини‑пример MPS‑конфига для device plugin (репликация full‑GPU):
apiVersion: v1kind: ConfigMapmetadata: name: device-plugin-mps-config namespace: nvidia-device-plugindata: config: |- version: v1 sharing: mps: renameByDefault: true resources: - name: nvidia.com/gpu replicas: 10
Смысл replicas: нода начинает рекламировать больше ресурсов, а «каждый ресурс» получает долю памяти/compute (по описанию механизма) как 1/N. При этом документация подчёркивает: пока что поддерживается только nvidia.com/gpu и только на full‑GPU.
cgroups и «SR‑IOV‑подобные»/виртуализационные решения
cgroups в контексте GPU чаще используются не для «дедлайнов» или жёстких долей SM, а как часть контроля доступа к устройствам (/dev‑узлам) и системным интерфейсам. Документация MIG отдельно отмечает, что старый /proc‑механизм системных интерфейсов депрекейтнут и рекомендуется /dev‑ориентированный механизм контроля доступа через cgroups, доступный на драйверах 450.80.02+ (и новее). Практический вывод: в многоарендных средах важно, чтобы контейнеры не получали «лишние» device nodes и capabilities, а доступ к MIG‑управлению был только у платформенных компонентов.
Виртуализация. MIG официально рассматривается в нескольких режимах: bare‑metal/контейнеры, passthrough виртуализация и vGPU на поддерживаемых гипервизорах; при этом MIG позволяет нескольким vGPU/VM одновременно работать на одном физическом GPU, сохраняя гарантии изоляции vGPU. Если говорить «SR‑IOV‑подобно», то в индустриальных стеках виртуализация GPU может включать SR‑IOV и/или mediated devices (mdev/VFIO‑mdev), но конкретная поддержка и licensing‑модель зависят от вендора/платформы (например, NVIDIA vGPU — отдельная история и часто требует лицензий).
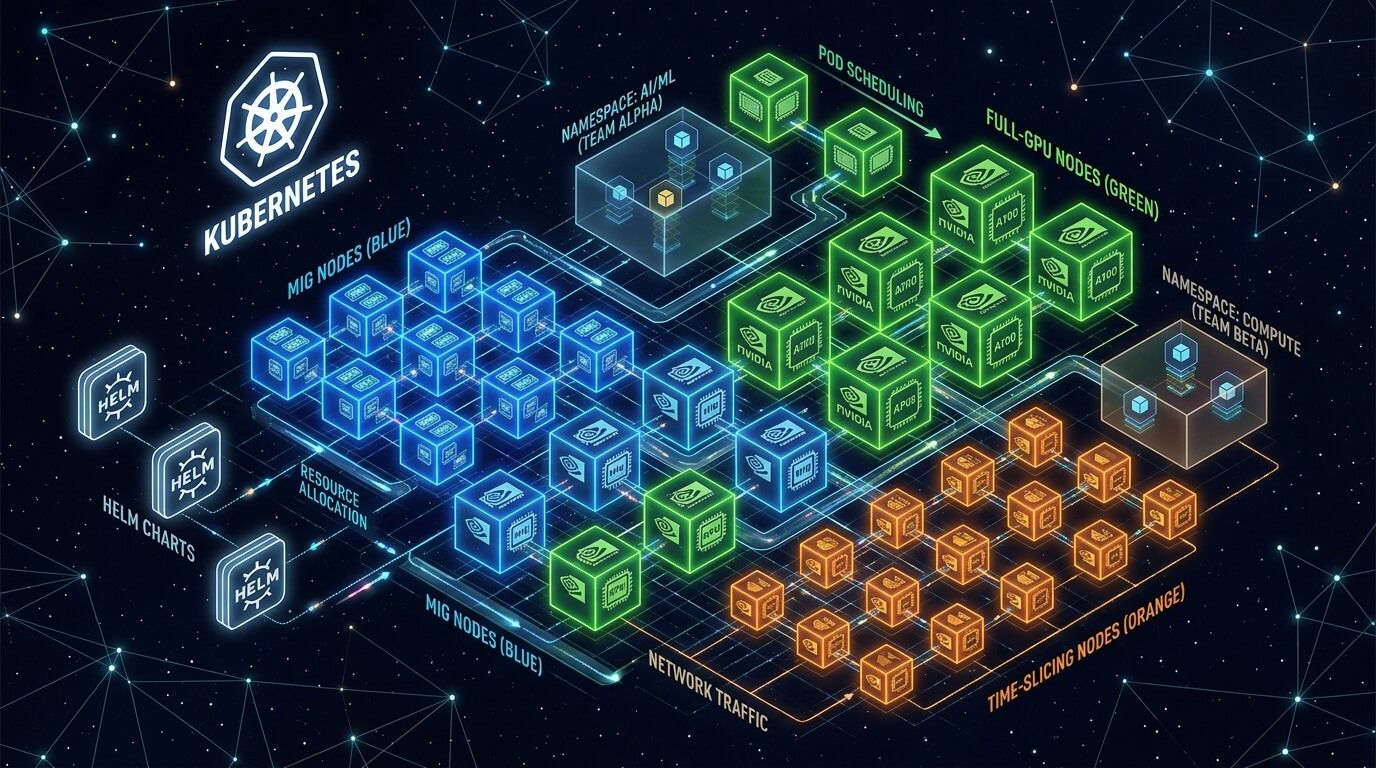
Архитектура multi-tenant GPU в Kubernetes: reference design
Ниже — практический «скелет» архитектуры, который хорошо масштабируется, когда GPU просят сразу несколько команд с разными типами нагрузки.
Логика такая: не пытаться одним режимом удовлетворить всё, а сегментировать кластер на понятные домены: training (full‑GPU), shared‑inference/interactive (MIG), best‑effort (time‑slicing). Управление профилями — через GPU Operator (MIG Manager, конфиги time‑slicing), а квоты/политики — через неймспейсы, ResourceQuota и правила планирования (labels/taints/affinity).
1) MIG‑переконфигурация требует чистоты ноды: MIG Manager отмечает, что для конфигурации профилей не должно быть пользовательских GPU‑ворклоадов; иногда требуется cordon/maintenance window. 2) Time‑slicing не даёт изоляции памяти/fault domain, поэтому ему место там, где SLA мягкий (best‑effort). 3) Комбинация MIG и MPS в Kubernetes: на уровне CUDA MPS поверх MIG поддерживается, но device‑plugin‑MPS в Kubernetes не дружит с MIG (по крайней мере в описанной реализации).
Политика: разделение, SLA, биллинг, безопасность
Разделение по командам/проектам. Самый управляемый вариант — «одна команда = один неймспейс», плюс отдельные nodepool’ы/лейблы под разные режимы GPU. Лейблы nvidia.com/gpu.product и -SHARED, а также MIG‑лейблы от оператора позволяют направлять поды на «правильные» ноды без магии.
SLA. Более жёсткий SLA (предсказуемая задержка/throughput) почти всегда тянет вас в сторону MIG или full‑GPU. MIG про это прямо говорит: предсказуемость обеспечивается выделением ресурсов на уровне подсистемы памяти и кэшей.
Биллинг. Самая понятная единица учёта:
- full‑GPU: GPU‑час (nvidia.com/gpu занятый подом);
- MIG: slice‑час или «профиль‑час» (например, mig-1g.10gb‑час);
- time‑slicing/MPS: «shared‑GPU‑час» (реплика‑час), но с пометкой, что это best‑effort и отражает право доступа, а не гарантированную долю производительности.
Безопасность. MIG даёт наиболее сильную изоляцию между «арендаторами» на одной карте; time‑slicing и MPS хуже подходят как security boundary, потому что делят один физический GPU и один fault‑domain. На уровне Kubernetes важно не допускать привилегированных подов в общих неймспейсах и жёстко контролировать доступ к нодам/daemonset’ам GPU‑инфраструктуры (иначе злоумышленник будет бороться не с MIG, а с вашим RBAC). Сама документация MIG подчёркивает, что управление MIG по умолчанию требует привилегий, но может делегироваться через права на MIG capabilities — это отдельная зона риска и её лучше держать у платформенной команды.
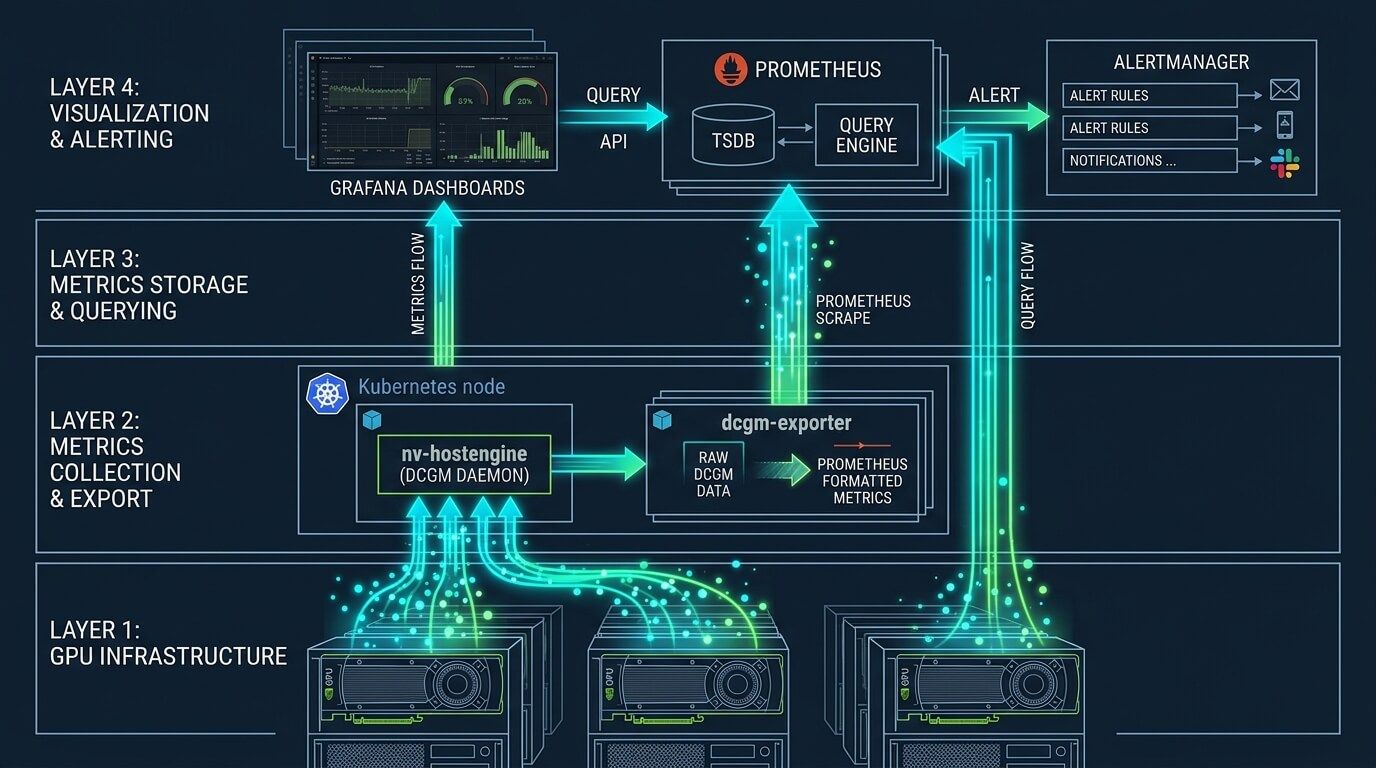
Наблюдаемость: метрики, инструменты, алерты и дашборды
GPU без наблюдаемости — это вечные споры «мне не дали карту» vs «ты сам её не грузишь». Наблюдаемость нужна в трёх проекциях: здоровье железа, эффективность утилизации, и привязка потребления к командам/подам.
Инструментальная база
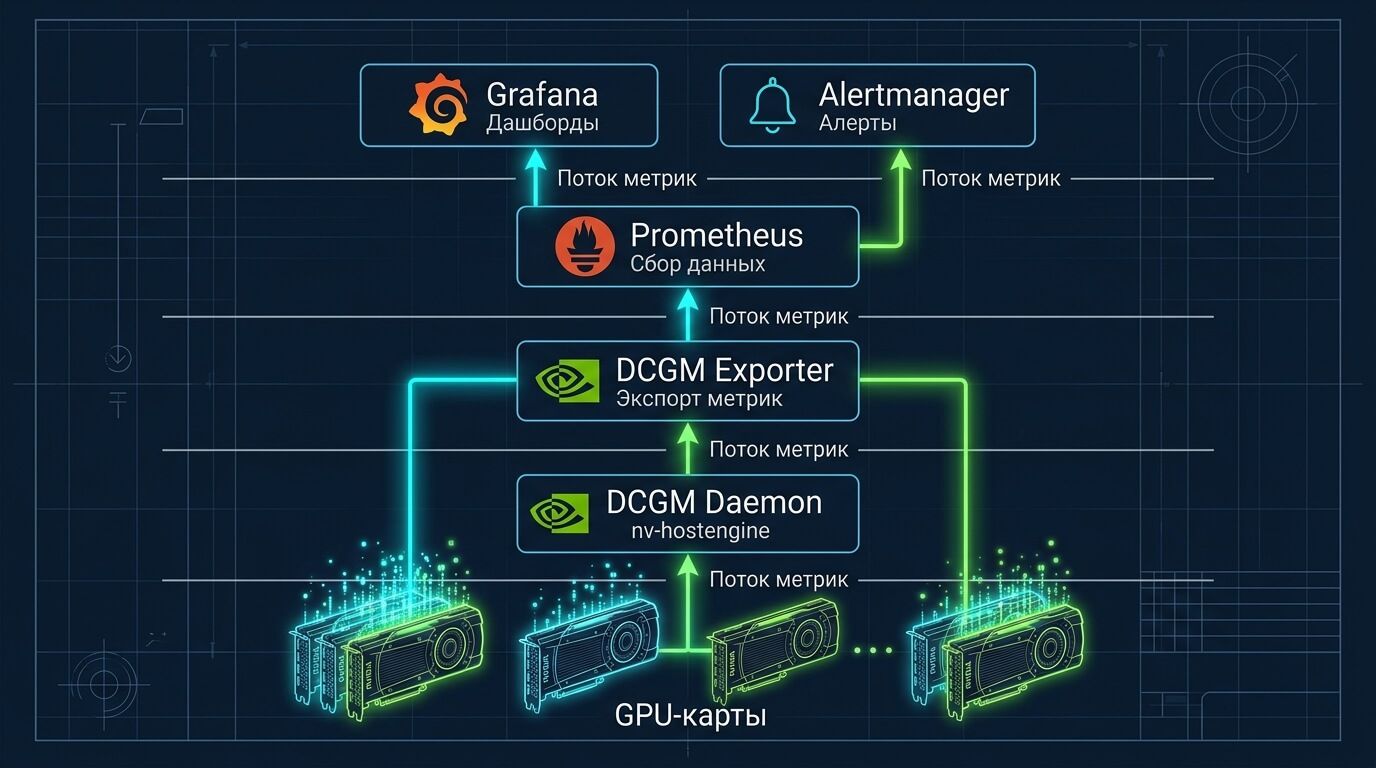
DCGM Exporter — стандартный способ выгружать GPU‑метрики в Prometheus: он публикует метрики на HTTP endpoint /metrics и может работать как standalone контейнер или DaemonSet в Kubernetes. DCGM Exporter запускает nv-hostengine встроенно, но на системах, где DCGM уже работает (например, DGX), рекомендуется подключаться к существующему nv-hostengine, чтобы избежать несовместимостей версий.
MIG‑поддержка в метриках. DCGM Exporter умеет публиковать метрики как по GPU целиком, так и по отдельным MIG‑инстансам; документация также уточняет, что в MIG‑режиме имеет смысл репортить на уровне GPU instance (а не «GPU целиком», который не назначается подам).
Prometheus/Grafana. Вариант «по умолчанию» — kube‑prometheus‑stack + дашборды на Grafana. DCGM Exporter официально позиционируется как компонент для интеграции с Prometheus/Grafana.
Что собирать: метрики и привязка к подам
Короткая, практичная таблица «что мерить и чем»:
DCGM Exporter показывает в примерах конкретные метрики (clock/temp/power/XID/FB used/free), а также описывает параметры включения Kubernetes‑маппинга.
Поток данных наблюдаемости
flowchart LR GPU[(GPU / MIG instances)] --> DCGM[nv-hostengine/DCGM] DCGM --> EXP[DCGM Exporter /metrics] EXP -->|scrape| PROM[Prometheus] PROM --> GRAF[Grafana Dashboards] PROM --> AM[Alertmanager] PROM --> BI[Cost/Billing pipeline]
DCGM Exporter по сути является мостом между DCGM (nv-hostengine) и Prometheus, публикуя метрики на /metrics.
Алерты и дашборды: «скелет», который окупается
Ниже — базовые алерты, которые чаще всего ловят реальные инциденты (примерно; названия метрик — DCGM):
Перегрев / питание
DCGM_FI_DEV_GPU_TEMP > 85
XID errors (часто коррелируют с падениями драйвера/ворклоадов)
increase(DCGM_FI_DEV_XID_ERRORS[5m]) > 0
Подозрительно низкая утилизация при «занятом» GPU(полезно для «я взял GPU и забыл» — дальше вы связываете с namespace/pod и решаете организационно)
avg_over_time(DCGM_FI_DEV_GPU_UTIL[30m]) < 10
DCGM Exporter явно демонстрирует наличие DCGM_FI_DEV_GPU_TEMP, DCGM_FI_DEV_POWER_USAGE, DCGM_FI_DEV_XID_ERRORS и базовых метрик потребления памяти.
Рекомендация по дашбордам: сделать минимум три уровня: 1) Infra‑дашборд (по нодам/GPU): температура/питание/ошибки/занятость; 2) Capacity‑дашборд (по пулам MIG/full/shared): сколько «единиц ресурса» доступно/занято; 3) Chargeback‑дашборд (по namespace/team): GPU‑часы / MIG‑инстанс‑часы / shared‑реплика‑часы + эффективность (утилизация).DCGM Exporter и его Kubernetes‑интеграция поддерживают обогащение метрик контекстом, а GPU Operator — маркировку нод под режимы шаринга, что упрощает агрегации.
Тестирование, валидация и план внедрения
Сценарии использования и «как думать о размещении»
ML training. Обычно требует full‑GPU (или хотя бы больших MIG‑профилей) из‑за памяти, пропускной способности и коммуникаций. Обратите внимание на ограничения MIG в части P2P и NCCL: документация перечисляет нюансы P2P (в т.ч. ограничения между инстансами на разных GPU) и отдельно отмечает, что NCCL «currently not supported with MIG» — это повод обязательно прогонять ваш distributed training на стенде, прежде чем обещать его на MIG‑нодпуле.
Inference. Отлично ложится на MIG (несколько независимых «мини‑GPU» под разные модели/версии), либо на time‑slicing для best‑effort, если SLA мягкий и модели не конфликтуют по памяти.
Batch jobs / ETL на GPU. Часто идеально подходит под time‑slicing (если это «пожевать данные» небольшими ядрами) или под мелкие MIG‑профили — в зависимости от того, насколько важна предсказуемость и изоляция.
Interactive workloads (ноутбуки, эксперименты). MIG даёт понятный «песочный» ресурс с предсказуемым объемом памяти; time‑slicing — опасен тем, что один «любитель логов» может положить соседей.

Примеры Kubernetes-манифестов
Time‑slicing + валидация «реплик» на ноде. После применения time‑slicing конфигурации GPU Operator описывает, что Capacity/Allocatable на ноде возрастает (например, при 4 репликах на 4 физических GPU вы увидите 16 логических).
Валидация MIG/MPS: что проверять перед тем, как пускать команды
MIG:
- состояние MIG mode и факт создания GI/CI (nvidia-smi, nvidia-smi mig -lgi);
- соответствие профилей ожиданиям (например, 1g.10gb действительно создан на нужных нодах через label nvidia.com/mig.config);
- восстановление после reboot/reset (автоматизация через mig‑parted / MIG Manager).
MPS:
- что клиенты действительно заходят через MPS (демон поднят, видимость GPU задана CUDA_VISIBLE_DEVICES);
- что EXCLUSIVE_PROCESS включён там, где это часть политики;
- что QoS‑ограничения (active thread percentage) применяются так, как вы ожидаете (и что вы понимаете, когда они применяются — часто это важно «когда стартовал клиент/сервер»).
Наблюдаемость как часть валидации: убедиться, что DCGM Exporter публикует метрики, и (в MIG) что метрики появляются на уровне GPU instance; документация прямо показывает пример вывода метрик и поведение в MIG‑режиме.
Бенчмарки и тестовая нагрузка
Для платформенной валидации полезно разделить тесты на три корзины:
1) Synthetic: короткие CUDA‑тесты/VectorAdd для проверки «GPU доступен, драйвер ок». GPU Operator даже включает/упоминает CUDA‑валидацию в своём контуре. 2) Model‑level: фиксированные модели (например, небольшие трансформеры для inference) с измерением latency/throughput на разных профилях MIG и при разных replicas time‑slicing.3) Contention tests: два‑три типа ворклоада одновременно (инференс + тяжелый batch) — чтобы увидеть «шумных соседей» и подтвердить, что MIG действительно держит предсказуемость, а time‑slicing честно «пилит время» без гарантий.
Для MPS полезно повторить тесты на конкурентность (throughput при росте числа клиентов) и упереться в лимит клиентов, который в документации/примерах указывается как порядка десятков (для Volta‑класса — 48, и в MIG+MPS уменьшается по размеру CI).
Выбор между MIG и MPS и комбинирование
Практическая матрица принятия решения выглядит так:
- Если вам нужен security boundary и гарантии ресурса между командами — начинать с MIG. Он даёт аппаратную изоляцию и предсказуемость за счёт выделенных путей через память/кэш/контроллеры.
- Если вам нужно уплотнить мелкие процессы (особенно многопроцессные/кооперативные CUDA‑задачи) и вы готовы жить с общим fault‑domain — MPS может дать прирост утилизации и производительности за счёт лучшего перекрытия операций.
- Если вам нужна самая простая операционка и «без сюрпризов» — full‑GPU остаётся базовым выбором для training.
Комбинация возможна на двух уровнях: 1) CUDA MPS поверх MIG (на уровне драйвера/рантайма): документация допускает это и предупреждает про уменьшение лимита клиентов пропорционально CI. 2) Kubernetes device plugin MPS как режим шаринга ресурсов: тут ограничение жёстче — MPS‑шаринг device plugin не поддерживается при включённом MIG и отмечается как экспериментальный.
Именно поэтому в продакшене чаще встречается схема «MIG‑ноды для multi‑tenant + отдельные full‑GPU/возможно time‑slicing ноды», а MPS оставляют для узких задач или для non‑Kubernetes окружений/специализированных кластеров.
План внедрения по шагам
Ниже — реалистичный пошаговый план, который минимизирует простои и «магические» инциденты:
1) Инвентаризация: какие модели GPU, какие драйверы, какие типы нагрузок (training/inference/batch/interactive), какие требования по SLA. Минимальные версии драйвера для MIG и нюансы reset/персистентности зависят от поколения GPU. 2) Сегментация нодпулов: выделить хотя бы два пула — full‑GPU и MIG; третий (time‑slicing) добавлять только если понимаете, зачем best‑effort. 3) Установка GPU Operator и базовая валидация (поды оператора, device plugin, dcgm-exporter). 4) Включение MIG стратегии (single/mixed) и применение первых профилей на 1–2 нодах; учесть, что MIG Manager требует отсутствия пользовательских ворклоадов и может потребовать reboot в отдельных средах. 5) Модель квот: неймспейсы по командам + ResourceQuota на MIG‑ресурсы/full‑GPU; описать правила доступа и эскалации. 6) Наблюдаемость: Prometheus scrape DCGM Exporter, базовые дашборды, алерты по температуре/XID/утилизации; отдельно убедиться в MIG‑уровневых метриках. 7) Тест‑набор: synthetic + model‑level + contention; затем пилот с 1–2 командами.8) Расширение: добавление профилей MIG под типовые use cases (например, «инференс‑профиль» и «интерактив‑профиль»), автоматизация восстановления конфигурации после reboot/reset (mig‑parted/MIG Manager), формализация биллинга.
Чек-лист перед продакшен-запуском
- MIG‑геометрия воспроизводится и восстанавливается после reboot/reset (автоматизация есть, ручной runbook есть).
- Для Ampere/Hopper учтены различия reset/персистентности MIG‑режима.
- DCGM Exporter отдаёт метрики, включая MIG‑инстансы; Prometheus их реально скрейпит; есть базовые алерты.
- Для shared‑режимов вы осознанно приняли риск общего fault‑domain и отсутствия memory/fault isolation (time‑slicing), и политики SLA это отражают.
- Если планируется MPS: подтверждены лимиты клиентов, режим EXCLUSIVE_PROCESS (если требуется политикой) и понятен эффект QoS‑настроек.
- Для distributed training на MIG отдельно проверена совместимость вашего стека (учесть ограничения, описанные для NCCL/P2P).
Когда multi‑tenant GPU сделан правильно, он перестаёт быть «ресурсом для драки» и становится обычной платформенной услугой: с профилями, квотами, прозрачной стоимостью и дашбордами, которым верят. MIG здесь чаще всего — фундамент, MPS и time‑slicing — инструменты точечной оптимизации, а наблюдаемость и политика — то, что превращает всё это в управляемую систему.

