




















Обработка больших массивов данных и сложные математические расчеты требуют серьезных вычислительных мощностей. Обычные компьютеры могут работать с Big Data, но вычисления занимают слишком много времени. Теряется сам смысл их анализа и прогнозирования, так как данные быстро теряют актуальность.
Более эффективной является математика и аналитика «в облаке». Для расчетов используются особые сервера, оснащенные серверными видеокартами с графическими процессорами (GPU). Из-за особенностей архитектуры они лучше справляются с математическими операциями. Но обо всем по порядку.
Как появились серверные GPU-вычисления?
Впервые применять чипы видеокарт для обработки данных начали в 2016 году в США и Европе. В августе того года началось тестирование серверов с чипами от Nvidia, а начале осени появилось специализированное решение для математических вычислений. Компания Amazon представила свои облачные сервера, в которых помимо центрального процессора были установлены графические.
В конце 2016 года аналогичное решение стало доступно пользователям Microsoft Azure. Компания предлагала пользователям виртуальные сервера N-Series, в которых для вычислений использовались процессоры Nvidia. Чуть позже, в 2017 году, Google сообщил о том, что ее сервисы будут графические чипы видеокарт.
В России первые предложения серверов с GPU, пригодных для обработки Больших данных, стали появляться в 2017 году. Сейчас эта услуга достаточно популярна и востребована. Помимо производительных видеокарт для вычислений они оснащаются высокоскоростными твердотельными накопителями. Благодаря этому можно перенести в «облако» самые ресурсоемкие вычисления и решать задачи, недоступные для существующей на предприятии инфраструктуры.
Что такое GPU-вычисления?
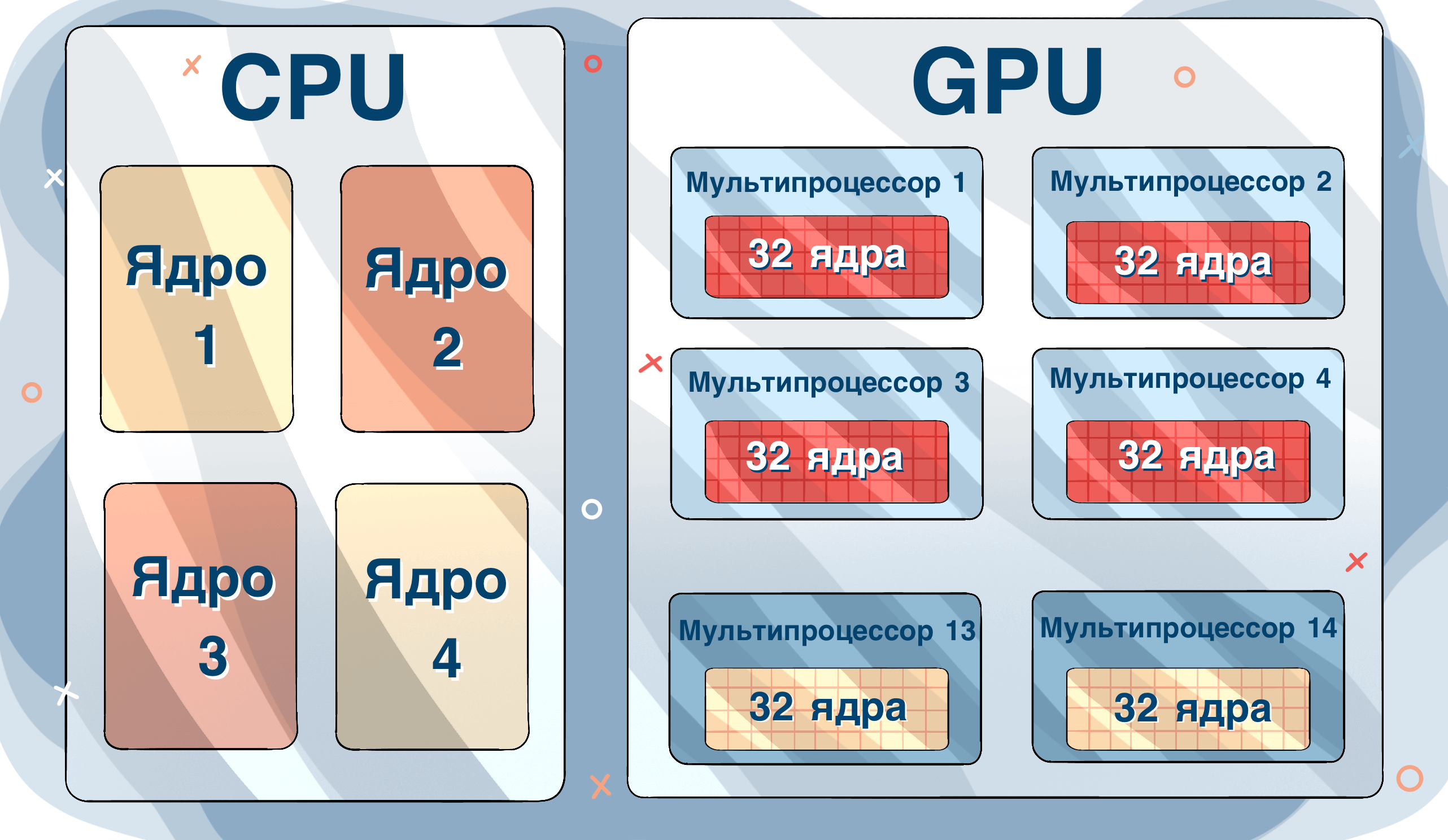
Решение математических и аналитических задач с большими объемами данных в облаке подразумевает использование виртуальных серверов, аппаратная часть которых включает в себя GPU-ускорители. Благодаря процессорам видеокарт виртуальная машина может обрабатывать большие объемы данных.
Наличие GPU на сервере позволяет делегировать этому процессору ресурсоемкие математические вычисления. Речь идет не только о математических вычислениях как таковых.
Связка CPU+GPU позволяет решать такие задачи:
- Рендеринг трехмерной графики и видео в различных приложениях для работы с контентом;
- Анализ статистических данных и прогнозирование на их основе;
- Трехмерное моделирование и визуализация объектов;
- Исследования в сфере химии, биохимии, биологии, изменений климата и т. п.;
- Использование технологий машинного обучения и создание нейронных сетей.
В контексте сегодняшнего материала серверы с GPU рассматриваются для использования в анализе Big Data. Обработка больших массивов информации требует не только вычислительной мощности, но и распараллеливания процессов. Что достаточно эффективно можно реализовать с помощью чипов видеокарт, так как они имеют большое количество ядер.
Какие данные эффективно обрабатывать на серверах с GPU?
К Большим Данным относятся массивы информации, собранные большим количеством устройств или датчиков или полученные по результатам исследований. Например, данные о температуре в контейнерах для перевозки продуктов, собранные специальными датчиками. Либо информация по всем продажам во всех магазинах разветвленной торговой сети за месяц или за год.
К обычным данным относится статистика продаж в одном магазине частного предпринимателя. Либо информация о температуре воздуха за окном в течение недели.
Аренда серверов будет выгодной и быстро окупаться, если предстоит работать с данными, которые имеют следующие характеристики:
- Объем обрабатываемой информации превышает 150 Гб за один день.
- Данные для обработки поступают постоянно и очень быстро, поэтому их нужно обрабатывать без задержек. В противном случае они будут накапливаться как снежный ком, а целесообразность их обработки теряется, они устаревают.
- Данные сильно отличатся по типам. Они могут поставляться в виде структурированной таблицы или неструктурированными, полными или неполными.
- Объем поступающих данных может постоянно меняться в зависимости от времени суток, сезона, праздников, политических ситуаций и других внешних факторов. Поэтому важно всегда иметь возможность масштабировать вычислительные мощности для ускорения их обработки.
И главный признак — ценность данных. Обработка Big Data всегда ведется для получения консолидированной информации, выводов или прогнозов, на основании которых принимаются тактические или стратегические решения в работе компании, государства и т.п.
Вручную большие массивы информации по понятным причинам сформировать невозможно. Поэтому в большинстве случаев они генерируются с помощью уже существующих программ, датчиков и сенсоров, парсинга данных в интернете специальными скриптами.
Примеры источников больших данных, которые могут обрабатываться серверами с GPU:
- Результаты измерений с датчиков, сенсоров, IoT;
- Данные, получаемые с помощью RFID-идентификаторов;
- Информация из публикаций в социальных сетях;
- Данные международных метеорологических сервисов;
- Данные, получаемые операторами связи от абонентов.
Обратите внимание, что в большинстве случаев массив данных поступает обезличенными. Анализ позволяет выявить закономерности и сделать на их основе прогнозы или принять решения об изменении работы компании.
В каких отраслях можно использовать сервера с GPU для работы с Big Data?
В информационном обществе именно данные являются основным инструментом, с помощью которого можно достичь успеха в бизнесе. Анализ информации в больших объемах может понадобиться практически во всех сферах бизнеса.
Даже в тех, которые, на первый взгляд, не связаны с обработкой информации. В том числе:
Промышленное производство. Автоматизированные линии управления технологическими процессами — это IoT-решения, которые формируют большой массив данных. Их можно анализировать и использовать для оптимизации работы предприятия. Улучшение процессов производства позволит снизить себестоимость и повысить рентабельность работы компании.
Компании по добыче полезных ископаемых. Обнаружить залежи руды или нефтяное месторождение можно по косвенным данным, которые получают путем анализа собранной геологами информации. Анализ Больших данных дает возможность учитывать тип породы, температуру грунта и другие факторы, с помощью которых можно с высокой долей вероятности обнаружить месторождение.
Транспортные предприятия. Это одна из популярных сфер применения Big Data. Оптимальный маршрут доставки товара из одного пункта в другой позволяет значительно сократить расходы компании. Но для этого нужно учитывать интенсивность трафика, пропускную способность дорог, погоду, вероятность возникновения пробок, наличие заправочных станций. Поэтому построить качественный маршрут можно только путем анализа всего массива собранной информации. Этот способ успешно используют морские транспортные компании, которые перевозят грузы в контейнерах.
Торговая сфера. Независимо от способа продажи (интернет-магазин или обычный), а также сферы продаж (продукты питания или элитные яхты) анализ больших объемов данных позволяет эффективно планировать маркетинговые мероприятия для увеличения продаж. Также этот инструмент позволяет выявить «узкие места» в работе, устранить их и повысить рентабельность бизнеса.
Финансы и банкинг. Работа этих организаций неразрывно связана с анализом большого количества цифр. При использовании правильных алгоритмов для обработки финансовой информации можно делать точные прогнозы об изменении экономической ситуации, лучше оценивать риски при выдаче займов, оптимизировать налогообложение.
Кроме очевидных отраслей, анализ Big Data с помощью облачных серверов с графическими картами может понадобится в таких сферах:
- Сельское хозяйство для организации точного земледелия и оптимального использования земель;
- Медицина для повышения качества диагностирования и анализа результатов назначенной терапии;
- Фармацевтика для поиска лучших компонентов лекарственных препаратов, сбора информации об эффективности лекарств и возможных побочных явлениях;
- Беттинг и слоты для анализа действий клиентов и разработки новых вариантов привлечения аудитории.
Использование серверных решений позволит улучшить такие направления работы:
- Качество обслуживания клиентов;
- Информационную инфраструктуру компании;
- Продажи;
- Планирование и учет;
- Маркетинговые мероприятия;
- Поиск и работа с персоналом;
- Транспортировка товаров.
Почему для анализа Big Data не стоит использовать собственную инфраструктуру?
Как только у пользователя возникает необходимость в анализе Больших Данных, он пытается решить стоящую задачу с помощь существующей IT-инфраструктуры или путем покупки собственных серверов.
Такой подход нельзя назвать эффективным по двум причинам:
- Высокие капитальные затраты. Для приобретения сервера с видеокартами необходимо потратить много денег, а также времени на его доставку, развертывание, настройку и подключение. Кроме того, в будущем придется постоянно тратить средства на поддержание серверов.
- Низкая масштабируемость. Если в процессе решения математических задач станет понятно, что мощности оборудования недостаточно, придется вновь тратить много денег и времени на ее развертывание. А в случае, когда данные поступают не постоянно, а волнами, такой подход к масштабированию будет невыгодным.
Например, торговой компании в дни распродаж и праздников нужно анализировать огромные объемы данных. А в остальное время серверы стоят практически не нагруженными. Такая избыточная вычислительная мощность будет просто «съедать» деньги компании. Но и менее мощные компьютеры ставить нельзя, так как они не справятся с пиковой нагрузкой.
Кроме того, обычные игровые карты не адаптированы для математических вычислений.
Серверные GPU отличаются такими особенностями:
- Они рассчитаны на постоянную высокую нагрузку, что гарантируется производителем. Поэтому можно нагружать ее на 100% вычислениями и не бояться перегрева или выхода из строя.
- Они адаптированы для виртуализации. Поэтому корректно работают с серверным программным обеспечением и программами пользователя.
- В них встроен механизм коррекции ошибок, что повышает стабильность работы в интенсивном режиме.
- Они поддерживают технологии параллельных потоков или Hyper-Q для распараллеливания задач, которые возникают в процессе вычислений. Например. один поток может загружать данные, а второй запускать их анализ.
Преимущества использования облачных решений
В настоящее время в 4 случаях из 5 в случае необходимости в обработке Big Data компании используют облачные решения.
- Минимальное время на запуск проекта. Достаточно подобрать провайдера виртуальных или выделенных серверов с GPU, выбрать тарифный план и заключить договор. Настройка виртуальной машины занимает минимум времени, после чего можно сразу приступать к обработке данных.
- Оптимизация затрат. Пользователь выбирает тарифный пакет, который соответствует его запросам. Нет необходимости покупать избыточно мощные серверы, которые большую часть времени будут простаивать.
- Отсутствие дополнительных трат. Помимо оплаты услуг провайдера, пользователь не платит за электричество, кондиционирование помещений, не оплачивает услуги администратора, аренду помещения и т. п.
- Возможность для масштабирования. В случае, если вычислительной мощности недостаточно, можно просто купить больший тариф и продолжить работу. Нет необходимости покупать серверы, подключать их в сеть и настраивать. Масштабирование занимает минимум времени. И всегда можно «откатиться» назад, если в этом возникнет необходимость.
- Высокоскоростная связь и накопители. Помимо GPU, серверы оснащаются скоростными твердотельными накопителями для быстрой загрузки данных. Связь с дата-центрами обычно происходит по скоростным каналам. Поэтому в процессе обработки данных не будет «бутылочных горлышек», которые замедляют процесс.
- Обеспечение бесперебойной работы. При аренде виртуального сервера не нужно следить за его бесперебойной работой, прокладывать дублирующие каналы и делать аварийную систему энергообеспечения.
Хотите обрабатывать данные в облаке? Обращайтесь за помощью к нашим специалистам.



