




















Оглавление
- Что такое квантизация простыми словами
- Почему LLM так дорого запускать
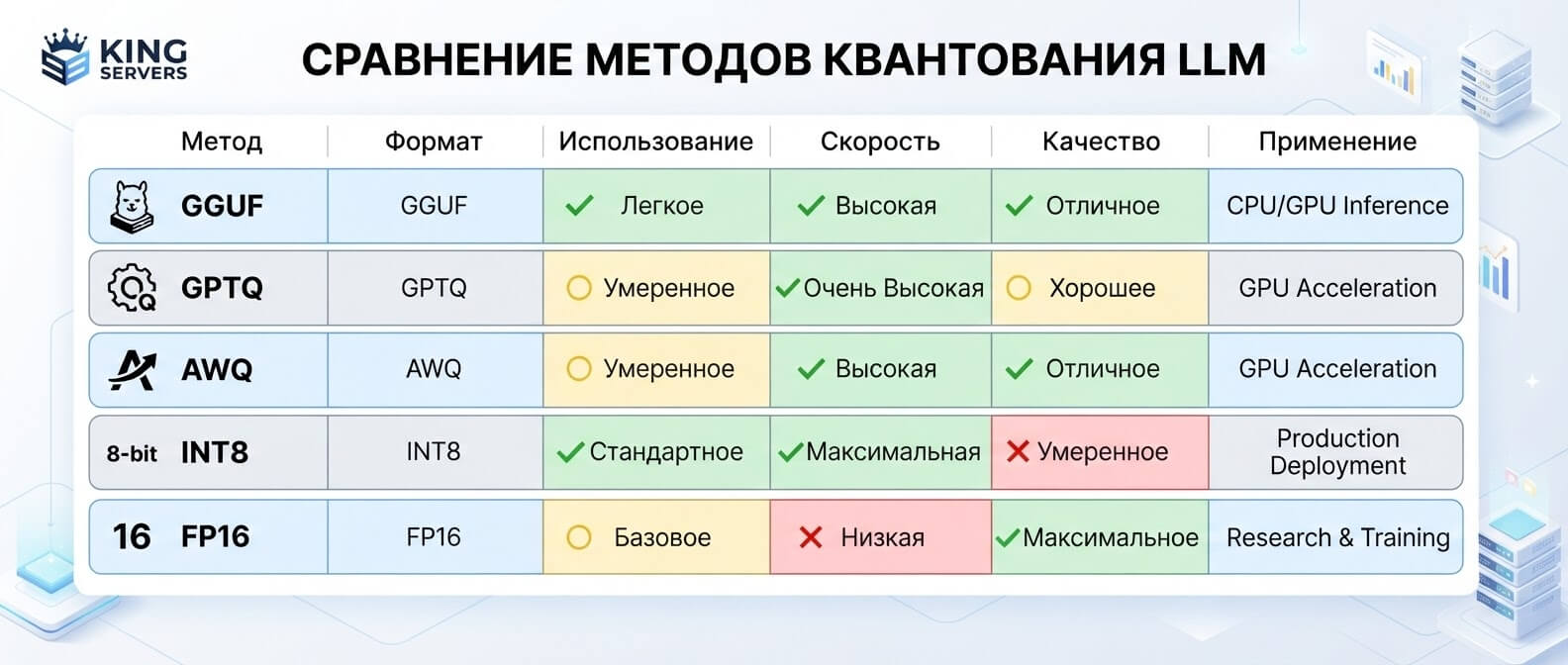
- FP16: надежная база, но не всегда экономичная
- INT8: аккуратная экономия без резкого падения качества
- 4-bit: максимум экономии, но нужна проверка
- GGUF: удобный формат для локального запуска и CPU/GPU сценариев
- GPTQ: пост-тренировочная квантизация для больших моделей
- AWQ: защита важных весов ради качества
- Как квантизация влияет на VRAM
- Как квантизация влияет на скорость
- Как квантизация влияет на качество ответов
- Когда FP16 лучше не трогать
- Когда INT8 — самый спокойный выбор
- Когда 4-bit действительно оправдан
- GGUF, AWQ или GPTQ: что выбрать
- Как правильно тестировать квантизованную модель
- Пример: как выбрать формат для LLM-сервиса
- На чем можно сэкономить благодаря квантизации
- Где экономить нельзя
- Частые ошибки при квантизации LLM
- Практический чек-лист перед запуском
- Хорошая стратегия: не одна модель, а несколько уровней качества
- Что выбрать для старта
- Вывод
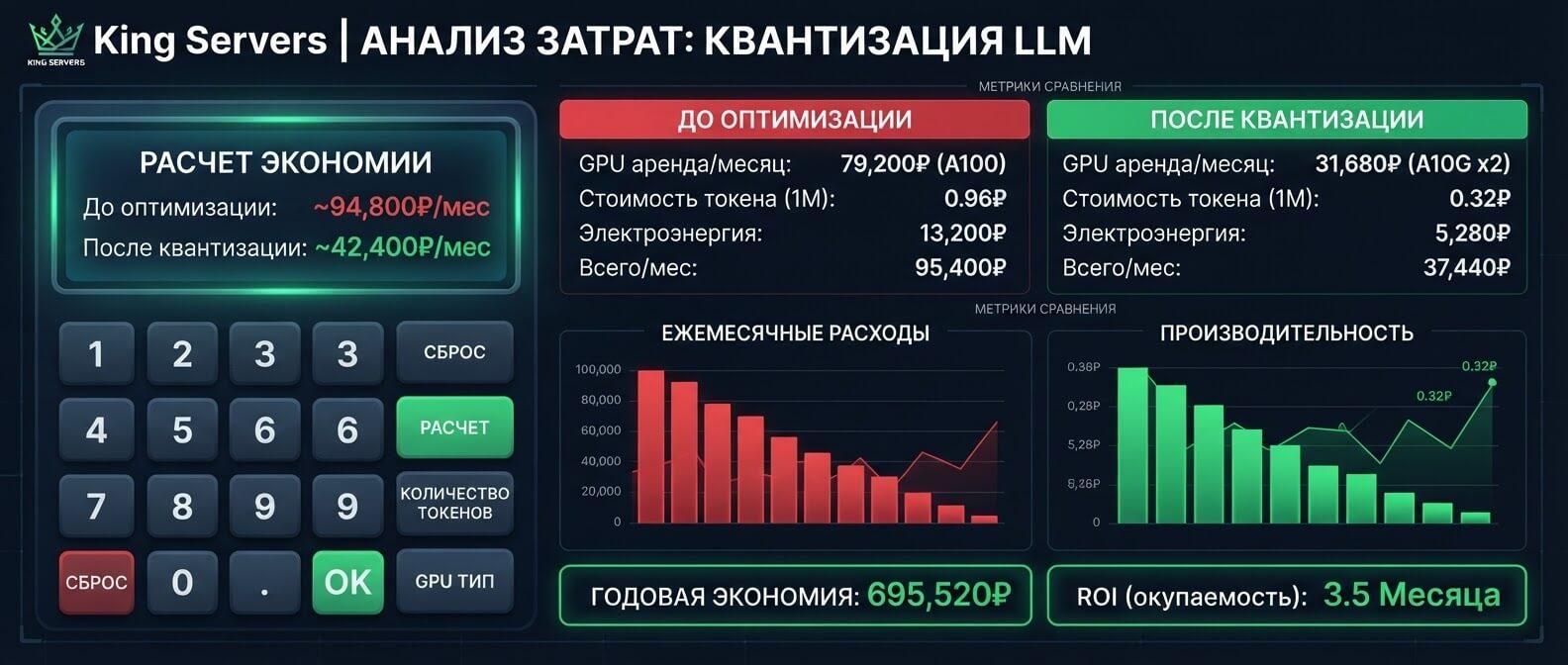
Большая языковая модель может отвечать красиво, быстро и полезно. Но у этой красоты есть цена: видеопамять, электричество, аренда GPU и постоянная борьба за скорость ответа. Особенно больно становится в момент, когда пилотный проект превращается в реальный сервис: пользователей больше, запросы длиннее, а счет за инфраструктуру уже не выглядит экспериментальным. Квантизация помогает снизить эту нагрузку. Не сделать модель “бесплатной” и не превратить маленький сервер в магический суперкомпьютер, а аккуратно уменьшить вес модели и требования к памяти. При правильном подходе LLM продолжает отвечать достаточно качественно, но запускать ее становится заметно дешевле.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Что такое квантизация простыми словами
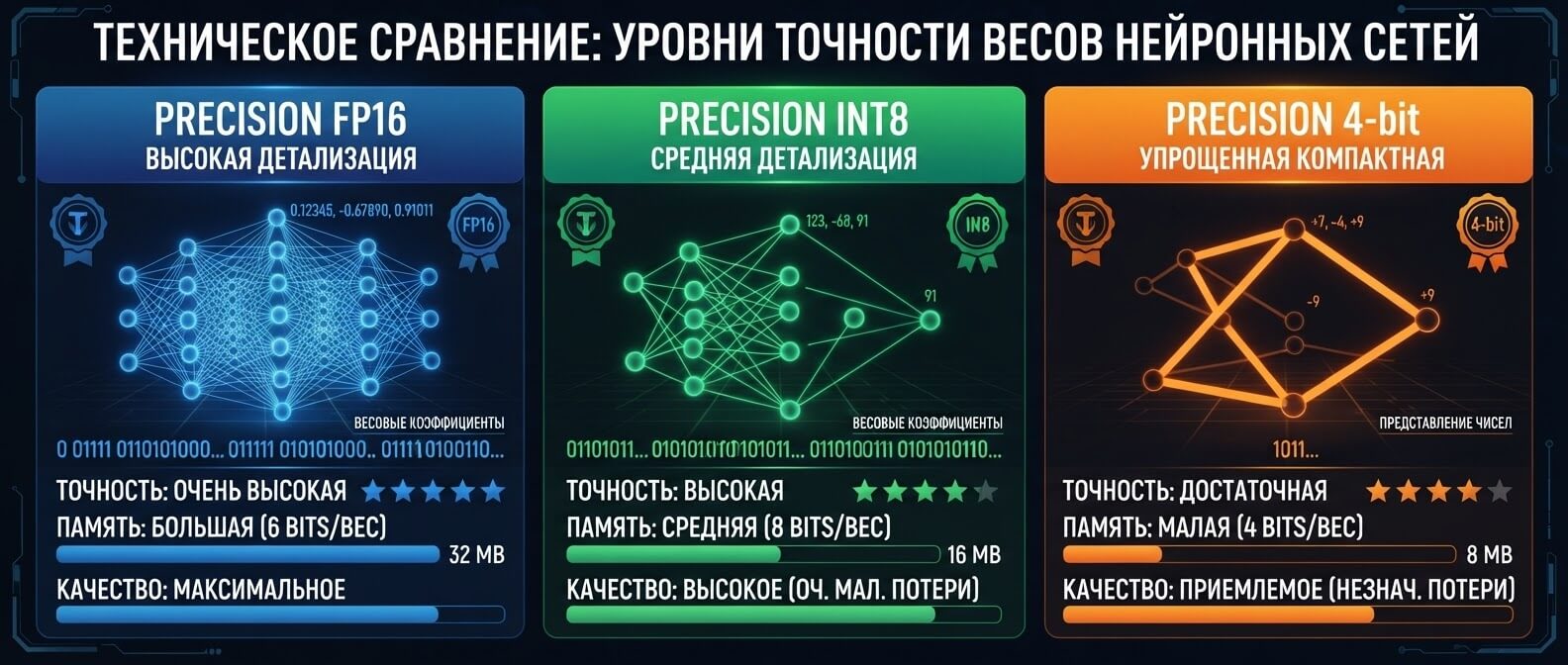
Квантизация нейросетей — это уменьшение точности чисел, которыми записаны веса модели. Внутри LLM нет “слов” в человеческом смысле. Там миллиарды чисел. Эти числа описывают связи между слоями модели и помогают ей предсказывать следующий токен. Чем больше модель, тем больше таких чисел нужно хранить в памяти и обрабатывать при каждом запросе. Упрощенная аналогия: представьте фотографию в очень высоком качестве. Ее можно сохранить в тяжелом формате без потерь, а можно слегка сжать. Если сжимать аккуратно, глаз почти не заметит разницы, зато файл станет меньше. С нейросетями похожая история, только вместо пикселей мы работаем с весами модели. Например, модель можно хранить в FP16, INT8 или 4-bit формате. Чем ниже точность, тем меньше места занимают веса. Но вместе с этим появляется риск: модель может чуть хуже рассуждать, чаще ошибаться в сложных задачах или терять стабильность на длинных контекстах. Важно не путать квантизацию с “обрезанием” модели. Мы не удаляем половину нейронов и не переписываем архитектуру с нуля. Мы меняем способ хранения и вычисления чисел.
Уровни точности
FP16 → INT8 → 4-bit: меньше VRAM, выше риск для качества.
Почему LLM так дорого запускать
Главный расход при инференсе LLM — это не только сама видеокарта. Важны три вещи
• сколько VRAM занимает модель
• сколько памяти уходит на контекст и KV cache
• сколько токенов в секунду может обслужить сервер.
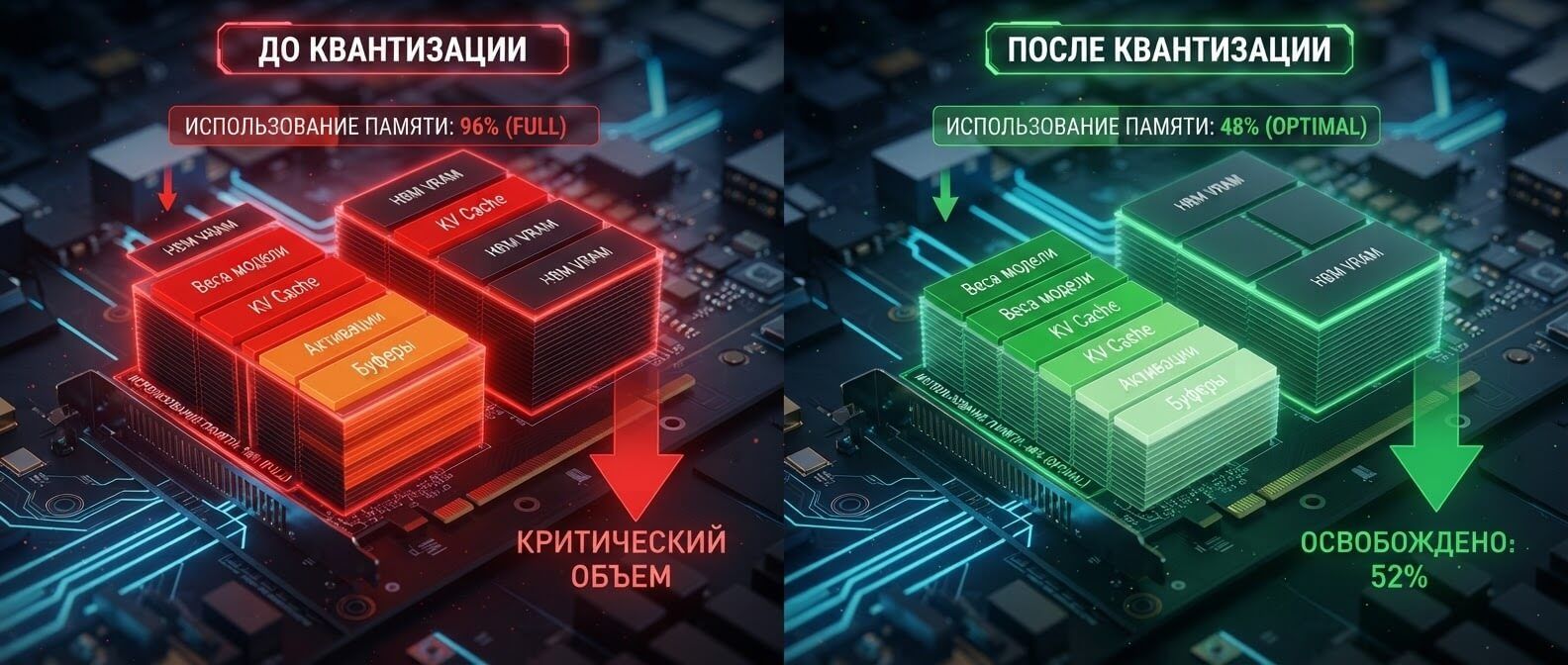
Модель на 7B параметров в FP16 только под веса может занимать примерно 14 ГБ: 7 миллиардов параметров умножаются на 2 байта. У модели 13B это уже около 26 ГБ, у 70B — около 140 ГБ. Это очень грубая оценка, но она хорошо показывает масштаб проблемы. И это еще не вся память. При реальной работе нужно учитывать служебные буферы, runtime, batch size, длину контекста и KV cache. Чем длиннее диалог, тем больше памяти нужно держать для внимания модели. Поэтому фраза “модель весит 14 ГБ” не означает, что она комфортно запустится на GPU с 16 ГБ VRAM. Квантизация снижает именно эту базовую нагрузку. Если веса занимают меньше места, появляется больше вариантов: можно взять GPU дешевле, поднять больше параллельных инстансов или обслуживать больше запросов на том же железе. Современные фреймворки прямо описывают квантизацию как способ уменьшить memory footprint и computational cost модели.
Три статьи расхода
Веса модели · KV cache · throughput.
FP16: надежная база, но не всегда экономичная
FP16 — один из самых привычных форматов для запуска LLM на GPU. Он использует 16-битные числа с плавающей точкой. Для многих моделей это комфортный баланс между качеством и производительностью. FP16 часто выбирают как базовую точку сравнения. Если модель в FP16 отвечает хорошо, ее уже можно пробовать сжимать дальше и смотреть, где начинается заметная потеря качества.
Плюсы FP16 понятны
• хорошая совместимость с GPU
• стабильное качество ответов
• меньше сюрпризов в сложных задачах
• удобно использовать как baseline для тестов.
Минус тоже очевиден: FP16 требует много VRAM. Для небольшой модели это терпимо. Для 70B уже начинается совсем другой уровень инфраструктуры: несколько GPU, tensor parallelism, более сложная настройка и более дорогая эксплуатация. Практический пример: если вы запускаете внутреннего ассистента для команды из 10 человек, FP16 может быть нормальным вариантом. Но если это публичный сервис с большим количеством запросов, каждая лишняя гигабайтная прослойка быстро превращается в деньги.
INT8: аккуратная экономия без резкого падения качества
INT8 — следующий шаг. Вместо 16-битных чисел используются 8-битные целые значения. В теории это почти в два раза меньше памяти под веса по сравнению с FP16. На практике INT8 часто воспринимается как “осторожная” квантизация. Она обычно дает хорошую экономию VRAM и при этом не так агрессивно влияет на качество, как 4-bit. Поэтому INT8 подходит для сценариев, где качество все еще критично, но инфраструктурные расходы уже хочется снизить. Например, у вас есть RAG-система для внутренней базы знаний: документация, регламенты, инструкции, ответы для поддержки. Если модель в INT8 почти не отличается от FP16 на ваших тестовых вопросах, держать ее в FP16 просто ради спокойствия может быть невыгодно. Но есть нюанс. INT8 не гарантирует ускорение само по себе. Если фреймворк, GPU или конкретные kernels плохо оптимизированы под выбранный формат, модель может стать меньше, но не обязательно быстрее. Иногда главный выигрыш — не latency одного запроса, а возможность запустить больше параллельных запросов на том же сервере. Hugging Face Transformers, например, поддерживает 8-bit и 4-bit quantization через bitsandbytes, а также методы AWQ и GPTQ для инференса. Это хороший показатель того, что квантизация давно стала не лабораторной экзотикой, а обычной частью production-инструментария.
4-bit: максимум экономии, но нужна проверка
4-bit квантизация звучит особенно привлекательно: веса модели становятся примерно в четыре раза компактнее по сравнению с FP16. Условная 7B модель вместо 14 ГБ под веса может приблизиться к диапазону 3,5–5 ГБ, в зависимости от формата, группировки, служебных данных и реализации. Именно поэтому 4-bit так популярен для локального запуска LLM, on-device сценариев, демо, MVP и сервисов, где стоимость инференса нужно держать под контролем.
Но 4-bit — это уже не просто “сжали и забыли”. Здесь сильнее проявляются компромиссы
• модель может хуже справляться с математикой
• код может стать менее точным
• длинный контекст может деградировать заметнее
• ответы на редких языках или узких доменных задачах могут просесть
• чувствительность к промптам иногда становится выше.
Есть исследования, которые показывают: 8-bit квантизация в среднем может сохранять качество довольно близко к оригиналу, а 4-bit методы на long-context задачах иногда дают существенные потери, особенно при длинном вводе и неанглийском языке. Это не означает, что 4-bit плохой. Это означает, что его нельзя выбирать по одной красивой цифре в таблице. Нужен тест на ваших задачах. Если модель отвечает на короткие FAQ, классифицирует обращения или помогает с простыми текстами, 4-bit может быть отличным решением. Если она анализирует юридические документы на 100 страниц, пишет сложный код или работает с финансовыми расчетами, лучше не экономить вслепую.
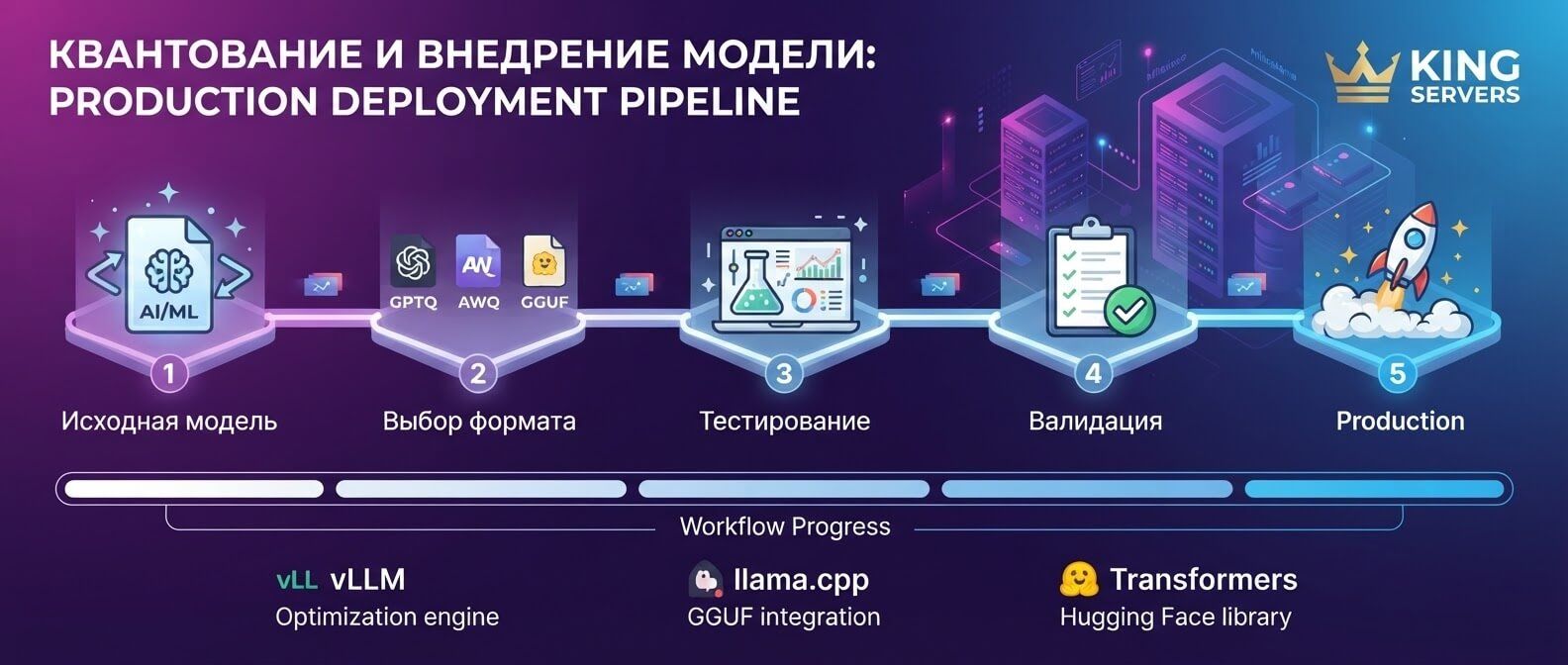
GGUF: удобный формат для локального запуска и CPU/GPU сценариев
GGUF чаще всего встречается рядом с llama.cpp и локальным запуском моделей. Это формат файлов, в котором удобно хранить модели, включая уже квантизованные варианты. Если говорить очень просто, GGUF — это не “метод качества” вроде GPTQ или AWQ, а формат упаковки модели для определенной экосистемы. Он стал популярным, потому что позволяет запускать LLM на разном железе: CPU, GPU, Apple Silicon, обычных рабочих станциях и серверах без сложной ML-инфраструктуры. llama.cpp описывает свой инструмент quantize как способ взять GGUF-модель в высокой точности, например F32 или BF16, и перевести ее в квантизованный формат, уменьшая размер и потенциально ускоряя инференс. При этом документация честно предупреждает: квантизация может вносить потерю точности, которую часто измеряют через perplexity или другие метрики.
Для практики GGUF особенно удобен в таких случаях
• нужно быстро поднять локального ассистента
• модель должна работать без тяжелого GPU-стека
• важна простая доставка файла модели
• нужно протестировать несколько уровней квантизации: Q4, Q5, Q6, Q8
• сервис не требует экстремального throughput.
Например, для внутреннего бота, который помогает сотрудникам искать ответы в документации, GGUF Q4 или Q5 может быть очень разумным стартом. Но для публичного API с высокой нагрузкой чаще смотрят в сторону vLLM, TensorRT-LLM, AWQ, GPTQ, FP8 и других production-ориентированных решений.
GPTQ: пост-тренировочная квантизация для больших моделей

GPTQ — один из известных методов post-training quantization. Его смысл в том, чтобы квантизовать уже обученную модель без полноценного переобучения. Это удобно: не нужно снова тратить огромные ресурсы на training pipeline. В оригинальной работе GPTQ описывается как one-shot weight quantization метод, который использует приближенную информацию второго порядка и может снижать разрядность весов до 3–4 бит с небольшой потерей качества на ряде сценариев. На практике GPTQ часто выбирают, когда нужна 4-bit модель для GPU-инференса. Он хорошо известен, поддерживается многими инструментами и часто встречается на Hugging Face в виде уже готовых квантизованных чекпоинтов. Но GPTQ не стоит воспринимать как универсальную кнопку “сделать дешевле”. Качество зависит от модели, датасета для калибровки, параметров квантизации, группы весов, используемого backend и типа задач. Простой пример: GPTQ-модель может отлично отвечать на общие вопросы и хорошо писать короткие тексты, но начать ошибаться в длинной цепочке рассуждений. Поэтому правильный вопрос звучит не “GPTQ хороший?”, а “GPTQ хороший именно для нашего набора запросов?”.
AWQ: защита важных весов ради качества
AWQ расшифровывается как Activation-aware Weight Quantization. Идея звучит довольно человечно: не все веса одинаково важны, поэтому нужно лучше защитить те, которые сильнее влияют на ответы модели. Авторы AWQ показывают, что защита небольшой доли “salient weights” может заметно снижать ошибку квантизации. Метод ориентируется не только на сами веса, но и на распределение активаций, то есть на то, как модель реально “работает” при прохождении данных через слои. В production-сценариях AWQ часто рассматривают как хороший вариант для 4-bit inference, особенно когда важны скорость и качество на GPU. Он хорошо ложится на идею: сжать модель агрессивно, но не грубо.
Где AWQ может быть уместен
• чат-боты с большим числом запросов
• ассистенты для поддержки
• генерация описаний, писем, ответов
• RAG-сервисы с коротким и средним контекстом
• сценарии, где нужно держать баланс между VRAM и качеством.
Но снова: тест обязателен. Если ваша модель работает с медицинскими, юридическими, финансовыми или технически критичными ответами, нельзя выбирать метод только потому, что он популярен.
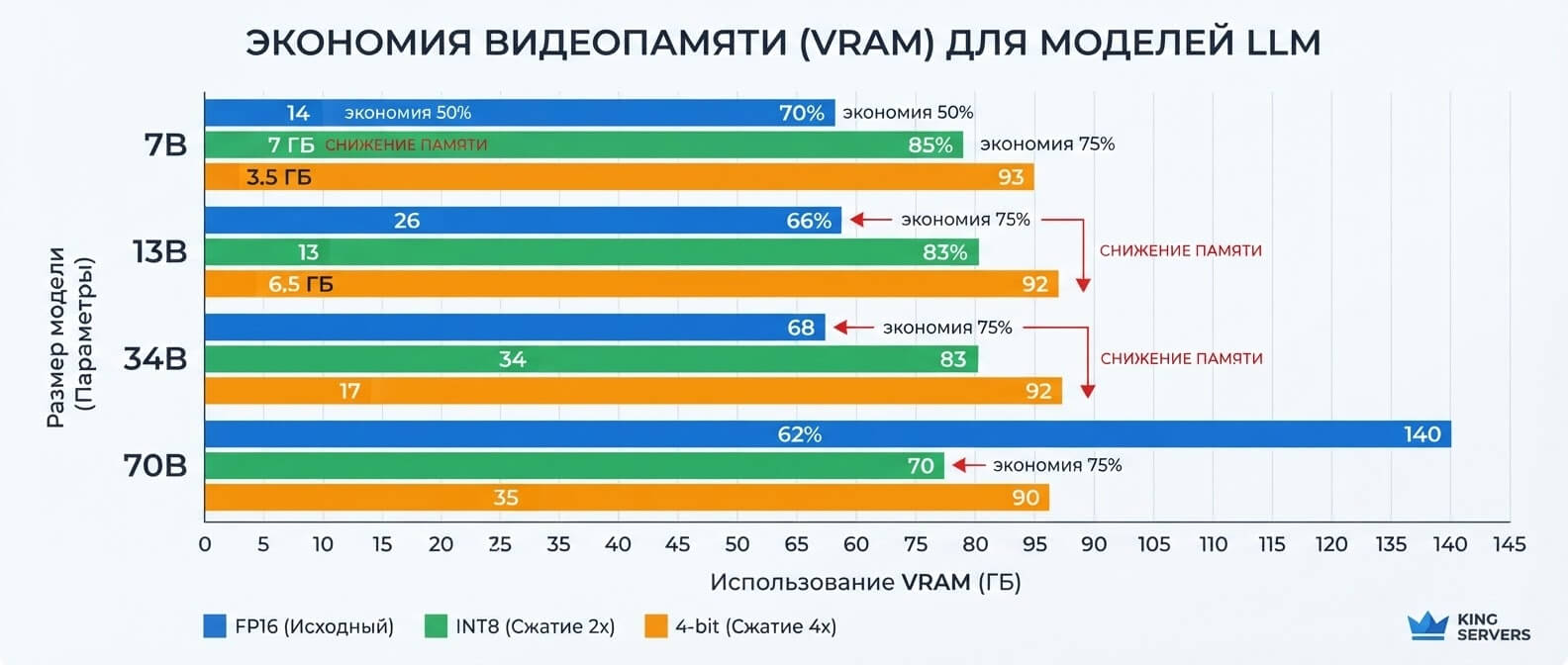
Как квантизация влияет на VRAM
Самый понятный эффект квантизации — снижение потребления памяти.
Упрощенно можно считать так
Размер модели
FP16, только веса
INT8, только веса
4-bit, только веса
7B
около 14 ГБ около 7 ГБ около 3,5–5 ГБ
13B
около 26 ГБ около 13 ГБ около 6,5–9 ГБ
34B
около 68 ГБ около 34 ГБ около 17–23 ГБ
70B
около 140 ГБ около 70 ГБ около 35–45+ ГБ Это не точные требования к серверу, а ориентир по весам. Реальная VRAM будет выше, потому что добавляются: KV cache; batch size; длина контекста; служебные буферы; особенности backend; tensor parallelism; выбранный режим внимания; overhead конкретного формата. Например, если вы запускаете 7B модель с коротким контекстом, 4-bit может позволить использовать более доступную GPU. Но если вы хотите обрабатывать длинные документы на десятки тысяч токенов, KV cache может стать отдельной проблемой, даже если веса модели уже сильно сжаты. Именно поэтому в расчетах стоимости важно смотреть не только на размер файла модели. Нужно считать весь профиль нагрузки.
VRAM по форматам (7B–70B)
Ориентир только по весам, без KV cache.
Как квантизация влияет на скорость
Здесь есть популярное заблуждение: “модель стала меньше, значит она всегда будет быстрее”. Не всегда. Квантизация может ускорить инференс, потому что меньше данных нужно читать из памяти. Для LLM это особенно важно: во многих режимах узким местом становится не чистая математика, а пропускная способность памяти. Если веса компактнее, GPU или CPU быстрее их “кормит” в вычисления.
Но скорость зависит от нескольких факторов
• поддерживает ли железо выбранный формат
• есть ли оптимизированные kernels
• какой backend используется
• какой batch size
• какая длина prompt и generation
• идет ли речь о prefill или decode фазе
• квантизованы только веса или еще активации/KV cache.
Например, 4-bit GGUF на CPU может быть спасением для локального запуска, но не обязательно даст лучший throughput для публичного API. А AWQ/GPTQ на GPU могут быть хороши, если inference engine действительно умеет эффективно с ними работать. vLLM описывает квантизацию как способ уменьшить memory footprint и поддерживает разные форматы через LLM Compressor, включая FP8, INT8 и INT4. Это хороший пример того, что современные inference stack уже строятся вокруг разных уровней точности, а не только вокруг FP16.
Скорость ≠ размер файла
Железо, kernels, batch, prefill/decode.
Как квантизация влияет на качество ответов
Качество падает не линейно. Нельзя сказать: “INT8 теряет 3%, 4-bit теряет 8%”. Так не работает. Одна и та же квантизация может почти не повлиять на ответы в простом FAQ, но заметно испортить результат в задачах с длинным контекстом, кодом, математикой или строгим следованием инструкциям.
Чаще всего проблемы проявляются так
Модель начинает хуже держать длинную логику
На коротком вопросе все выглядит нормально. Но если дать большой документ, несколько условий и попросить сделать вывод, модель может потерять часть деталей. Это похоже на человека, которому дали слишком сжатый конспект вместо полной инструкции. Главный смысл он уловил, но мелкие ограничения начал пропускать.
Ответы становятся менее стабильными
Сегодня модель отвечает правильно, завтра на похожий запрос дает странный поворот. Особенно это заметно при высокой температуре генерации или слабом системном промпте.
Код и математика страдают сильнее обычного текста
Для маркетингового описания небольшая неточность может быть незаметной. Для кода одна ошибка в синтаксисе уже ломает результат. Для математической задачи неверный промежуточный шаг портит весь ответ.
Неанглийские языки могут проседать заметнее
Многие модели обучены с сильным перекосом в сторону английского. Если добавить агрессивную квантизацию, редкие языковые паттерны могут пострадать сильнее. Для русскоязычных сервисов это особенно важно проверять отдельно. Поэтому лучший способ оценить квантизацию — не смотреть только на benchmark из интернета, а собрать свой набор тестов. Пусть там будут реальные вопросы пользователей, сложные документы, типичные ошибки, длинные диалоги и пограничные случаи.
Когда FP16 лучше не трогать
Иногда экономия на VRAM выглядит заманчиво, но цена ошибки слишком высокая.
FP16 или BF16 лучше оставить, если
• модель используется для критичных решений
• нужно максимальное качество рассуждений
• ответы проходят в юридический, финансовый или медицинский контекст
• модель пишет production-код
• важна работа с длинными документами
• вы еще не собрали тестовый набор и не понимаете, где модель ошибается.
FP16 также полезен как эталон. Сначала запускаете модель в FP16, фиксируете качество, скорость, расход памяти и стоимость. Потом сравниваете с INT8, AWQ, GPTQ или GGUF. Без baseline тест превращается в гадание.
Когда INT8 — самый спокойный выбор
INT8 часто хорошо подходит для первого шага оптимизации.
Его стоит рассмотреть, если
• FP16 слишком дорогой
• качество критично, но небольшой компромисс допустим
• сервис работает с поддержкой, FAQ, классификацией, короткими ответами
• нужна более высокая плотность размещения моделей на GPU
4-bit пока выглядит слишком рискованно. Например, компания запускает ассистента для отдела продаж. Он помогает быстро находить информацию по продукту, генерирует черновики писем и отвечает на типовые вопросы. Здесь INT8 может дать хорошую экономию, не превращая проект в постоянную охоту за странными ошибками.
Когда 4-bit действительно оправдан
4-bit хорош там, где экономия инфраструктуры напрямую влияет на жизнеспособность проекта.
Типичные сценарии
• MVP с ограниченным бюджетом
• локальный ассистент
• внутренний инструмент для небольшой команды
• массовая генерация простых текстов
• RAG с короткими фрагментами
• edge/on-device inference
тестирование нескольких моделей без покупки дорогой GPU-инфраструктуры. Например, вы хотите поднять несколько LLM под разные задачи: одна для поддержки, вторая для анализа логов, третья для генерации контента. В FP16 это может потребовать отдельной дорогой конфигурации. В 4-bit часть моделей можно разместить гораздо плотнее. Но 4-bit нужно вводить не “вслепую”, а через контроль качества. Хорошая практика — сравнивать ответы FP16 и 4-bit на одном наборе промптов и смотреть не только на “понравилось/не понравилось”, а на конкретные ошибки.
GGUF, AWQ или GPTQ: что выбрать
Универсального ответа нет, но можно ориентироваться на сценарий.
Для локального запуска и простого деплоя: GGUF
GGUF хорошо подходит, если нужно быстро запустить модель на CPU/GPU без тяжелого production stack. Это удобный вариант для локальных ассистентов, прототипов, небольших внутренних сервисов и тестов. Особенно удобно, что для популярных моделей часто уже есть несколько GGUF-файлов с разной степенью квантизации. Можно взять Q4, Q5, Q8 и быстро сравнить поведение.
Для GPU-инференса с 4-bit: AWQ или GPTQ
AWQ и GPTQ чаще выбирают, когда модель должна работать на GPU и обслуживать реальные запросы. Здесь важно смотреть на поддержку в вашем inference engine: vLLM, TensorRT-LLM, Transformers, TGI или другом стеке. AWQ часто привлекателен как метод, который старается сохранить важные веса. GPTQ популярен и широко распространен в готовых чекпоинтах. Но итоговый выбор все равно должен опираться на тесты.
Для осторожной оптимизации: INT8
Если проект уже в production и качество важнее максимальной экономии, INT8 может быть самым здравым первым шагом. Он снижает VRAM, но обычно менее агрессивен, чем 4-bit.
Для тонкой настройки: bitsandbytes и QLoRA
Если задача не только запускать модель, но и дообучать адаптеры, стоит смотреть в сторону 4-bit подходов из экосистемы bitsandbytes и QLoRA. Hugging Face описывает QLoRA как метод, который квантизует модель до 4 бит и обучает LoRA-адаптеры поверх замороженной квантизованной модели. Для бизнеса это может быть полезно, когда нужно адаптировать модель под свой стиль ответов, документацию или доменную лексику, не оплачивая полноценное дообучение всей модели.
Форматы и методы
GGUF · GPTQ · AWQ · INT8 — разные сценарии.
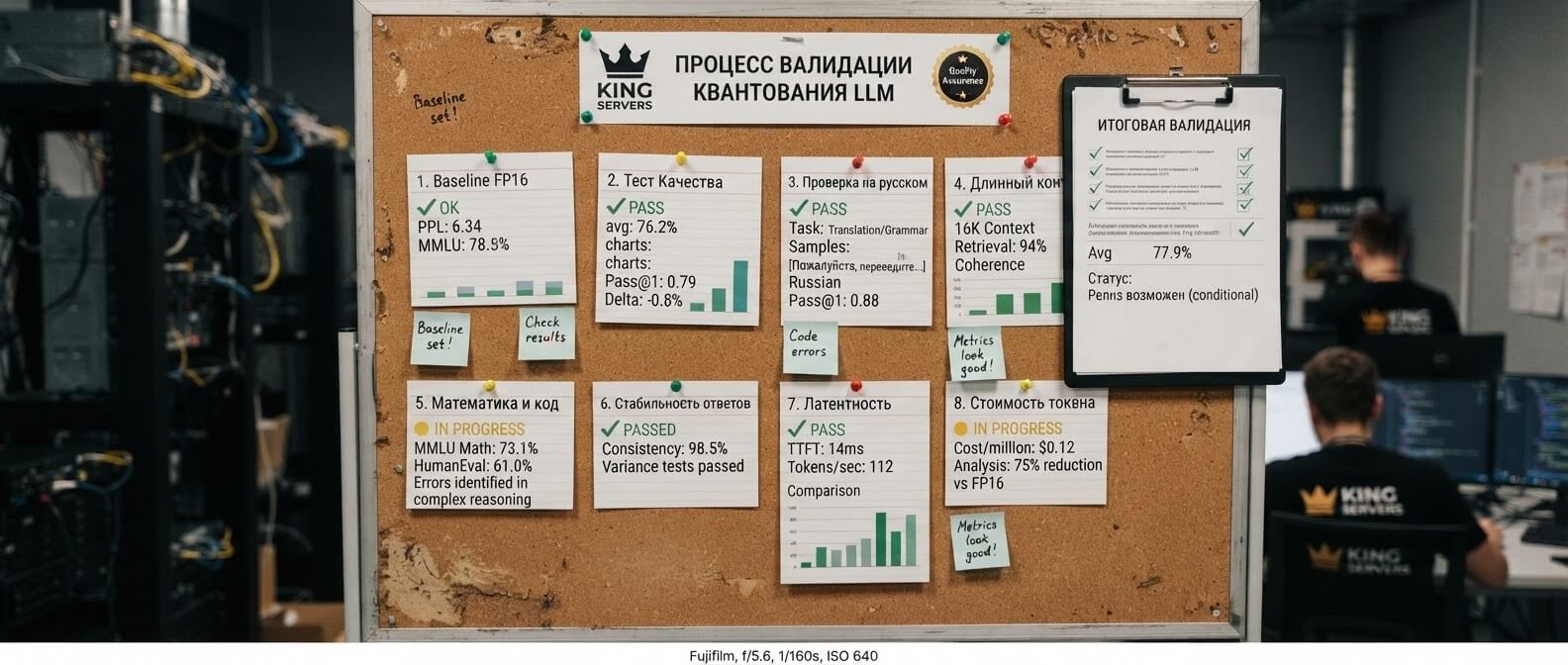
Как правильно тестировать квантизованную модель
Главная ошибка — проверить модель на трех красивых вопросах и решить, что все готово.
Нормальный тест должен быть ближе к реальной эксплуатации. Минимальный набор выглядит так
1. Соберите реальные промпты
Возьмите 50–200 запросов, которые похожи на будущую нагрузку. Не только простые, но и неприятные: длинные, неоднозначные, с ошибками, с несколькими условиями. Если это бот поддержки, добавьте вопросы от клиентов. Если ассистент для DevOps, добавьте реальные логи, конфиги, ошибки запуска. Если RAG по документации, добавьте документы разной длины и качества.
2. Сравните с FP16 baseline
Сначала прогоните модель в FP16. Затем ту же модель в INT8, AWQ, GPTQ или GGUF. Не меняйте одновременно промпт, температуру, retrieval и модель. Иначе вы не поймете, что именно повлияло на результат.
3. Оценивайте не только красоту текста
Для production важны конкретные метрики
• правильность фактов
• полнота ответа
• следование инструкции
• количество галлюцинаций
• стабильность на повторных запусках
• latency
• tokens per second
• VRAM usage
• стоимость 1 000 или 1 000 000 токенов
• поведение на длинном контексте.
4. Проверьте худшие случаи
Именно они ломают сервис. Обычные вопросы модель пройдет почти всегда. А вот длинный документ, смешанный русский и английский текст, таблица, код, лог ошибки или запрос с несколькими ограничениями быстро покажут, насколько квантизация безопасна.
5. Зафиксируйте “порог приемлемости”
Например: “мы готовы принять 2–3% ухудшения по ручной оценке, если стоимость инференса снизится на 35%”. Или наоборот: “качество должно быть почти идентичным FP16, экономия вторична”. Без такого порога команда будет спорить вкусовыми аргументами.
Тест квантизации
Baseline FP16 → тот же датасет → метрики и порог.
Пример: как выбрать формат для LLM-сервиса
Представим сервис, который отвечает клиентам на вопросы по документации хостинг-провайдера: VPS, выделенные серверы, GPU, сеть, биллинг, базовая настройка Linux.
Что важно
• ответы должны быть точными
• русский язык критичен
• длинный контекст бывает, но не всегда
• нагрузка растет вечером и в рабочие дни
стоимость GPU нужно держать под контролем.
Разумный путь может выглядеть так
• Запустить выбранную модель в FP16 и собрать baseline.
• Проверить INT8 на 100–200 реальных вопросах.
• Проверить AWQ или GPTQ 4-bit на тех же вопросах.
• Отдельно протестировать длинные инструкции и русскоязычные документы.
• Посчитать стоимость ответа при разном batch size.
• Оставить FP16 для сложных внутренних задач, а INT8/4-bit использовать для массовых типовых запросов.
Такой подход лучше, чем спорить “какой формат моднее”. В production побеждает не мода, а предсказуемость.
На чем можно сэкономить благодаря квантизации
Квантизация влияет сразу на несколько статей расходов.
Меньше VRAM на одну модель
Это самый прямой эффект. Если модель помещается на более доступную GPU, снижается стоимость сервера. Иногда это разница между “нужна дорогая карта” и “можно стартовать на более простой конфигурации”.
Больше моделей на одном сервере
Если каждая модель занимает меньше памяти, можно держать несколько специализированных моделей рядом. Например, одну для классификации, вторую для генерации, третью для анализа логов.
Больше параллельных запросов
Освободившаяся память может уйти на batch size и KV cache. Это помогает увеличить throughput, особенно если inference engine хорошо работает с batching.
Проще масштабировать MVP
На раннем этапе не всегда понятно, какая модель победит. Квантизация позволяет дешевле тестировать варианты, не покупая “с запасом” слишком дорогую инфраструктуру.
Где экономить нельзя
Есть задачи, где цена ошибки выше цены GPU.
Не стоит агрессивно квантизовать модель, если она
• дает рекомендации по безопасности без проверки человеком
• анализирует юридические договоры
• принимает финансово значимые решения
• пишет критичный production-код
• работает с медицинскими данными
• должна строго следовать длинным инструкциям
• обрабатывает документы с высокой ответственностью.
В таких случаях квантизация все равно возможна, но только после серьезной валидации. Иногда правильнее оставить FP16/BF16 для сложных задач, а квантизованную модель использовать для черновиков, поиска, классификации или предварительной обработки.
Частые ошибки при квантизации LLM
Ошибка 1. Смотреть только на размер файла
Маленький файл выглядит приятно. Но если модель стала чаще ошибаться, экономия может быстро исчезнуть: пользователи уйдут, поддержка получит больше жалоб, а команда начнет вручную исправлять ответы.
Ошибка 2. Не учитывать KV cache
Можно уменьшить веса модели в четыре раза, но забыть, что длинный контекст все равно требует памяти. Для RAG и анализа документов это особенно важно.
Ошибка 3. Сравнивать разные модели
Нельзя честно сравнивать “Model A FP16” и “Model B 4-bit” и делать вывод о квантизации. Сначала сравнивайте одну и ту же модель в разных форматах.
Ошибка 4. Использовать чужие benchmark как единственный аргумент
Открытые benchmark полезны, но они не знают вашу аудиторию, язык, промпты, документы и требования к ошибкам.
Ошибка 5. Игнорировать backend
Одна и та же квантизованная модель может вести себя по-разному в разных inference stack. Где-то будет отличная скорость, где-то слабая поддержка kernels, где-то проблемы с совместимостью. TensorRT-LLM, например, поддерживает разные quantization recipes, включая FP8, FP4, INT8/AWQ и другие варианты, но конкретный выигрыш зависит от модели, GPU и сборки engine.
Практический чек-лист перед запуском
Перед тем как переносить квантизованную LLM в production, стоит пройти короткий чек-лист.
1. Есть FP16 baseline.
Без него невозможно понять, насколько модель деградировала.
2. Есть тестовый набор реальных запросов.
Не синтетические “расскажи про космос”, а настоящие вопросы пользователей.
3. Проверены короткие и длинные контексты.
Особенно если сервис работает с RAG, документами или историей диалога.
4. Измерены latency и throughput.
Важно знать не только “помещается в VRAM”, но и “успевает отвечать под нагрузкой”.
5. Посчитана стоимость токена.
Иногда формат дает меньше экономии, чем ожидалось, если backend плохо оптимизирован.
6. Проверены языки.
Для русскоязычного продукта тесты на английском почти бесполезны.
7. Есть fallback.
Для сложных запросов можно отправлять задачу на более качественную модель, а типовые обслуживать квантизованной.
8. Настроен мониторинг качества.
После релиза нужно смотреть на жалобы, повторные запросы, ручные оценки, hallucination cases и падение полезности ответов.
Хорошая стратегия: не одна модель, а несколько уровней качества
В реальном сервисе не обязательно выбирать один формат навсегда.
Можно построить каскад
• простые запросы идут на 4-bit модель
• средние по сложности — на INT8
• критичные или длинные — на FP16/BF16
• сомнительные ответы отправляются на повторную проверку более сильной моделью.
Такой подход похож на службу поддержки. Не каждый вопрос должен сразу попадать к самому дорогому специалисту. Типовые обращения закрывает первая линия, сложные — эскалируются выше. Для LLM это работает так же. Квантизация становится не компромиссом “хуже, но дешевле”, а инструментом маршрутизации нагрузки.
Каскад моделей
4-bit → INT8 → FP16 по сложности запроса.
Что выбрать для старта
Если нужен короткий практический ориентир, можно идти так
• FP16/BF16 — для baseline, максимального качества и сложных задач.
• INT8 — для аккуратного снижения VRAM без сильного риска.
• 4-bit AWQ/GPTQ — для GPU-инференса, где важна экономия и есть тесты качества.
• GGUF Q4/Q5/Q8 — для локального запуска, CPU/GPU сценариев, быстрых прототипов.
• bitsandbytes/QLoRA — для задач, где нужно дообучать адаптеры поверх компактной модели.
Главное — не начинать с самого агрессивного формата только потому, что он кажется выгодным. В инфраструктуре LLM дешевле не всегда значит лучше. Хороший выбор — тот, который выдерживает реальные запросы.
Вывод
Квантизация нейросетей — один из самых практичных способов запускать LLM дешевле. Она уменьшает потребление VRAM, помогает плотнее использовать GPU и делает большие модели доступнее для MVP, внутренних инструментов и production-сервисов. Но это не волшебная кнопка. FP16 дает надежную базу, INT8 часто становится спокойным первым шагом оптимизации, а 4-bit форматы вроде AWQ, GPTQ и GGUF позволяют серьезно снизить требования к железу, если качество проверено на реальных задачах. Самый здравый путь — начать с baseline, собрать тестовый набор, сравнить несколько форматов и считать не только память, но и скорость, стоимость токена, стабильность ответов и поведение на длинном контексте. Тогда квантизация перестает быть экспериментом “на удачу” и становится нормальным инженерным инструментом. Если вы планируете запускать LLM на своих серверах, тестировать RAG, строить AI-ассистента или оптимизировать стоимость инференса, начните с простого: выберите модель, зафиксируйте качество в FP16 и проверьте, насколько далеко можно сжать ее без заметной потери пользы для пользователя. Иногда именно этот шаг превращает дорогой AI-прототип в рабочий продукт.
Итог
Baseline → тест → формат под задачу → каскад при необходимости.




