




















Оглавление
- Почему AI inference требует отдельного подхода
- Базовая архитектура Kubernetes-платформы для inference
- KServe: Kubernetes-native serving для моделей
- GPU Operator: подготовка GPU-нод без ручной настройки
- Kueue: очередь и квоты для AI workloads
- Autoscaling: масштабирование не только по CPU
- Как связать KServe и autoscaling
- Online inference и batch inference: разные стратегии
- Практический сценарий: LLM-сервис в Kubernetes
- На что обратить внимание при проектировании
- Когда Kubernetes для AI inference оправдан
- Роль выделенной инфраструктуры
- Итоги
AI-проекты всё чаще выходят за пределы экспериментальных ноутбуков и одиночных GPU-серверов. Когда модель начинает обслуживать реальные запросы пользователей, на первый план выходят уже не только точность и размер модели, но и инфраструктура: задержка ответа, масштабирование под пики, утилизация GPU, контроль расходов, отказоустойчивость и удобство эксплуатации. Именно поэтому Kubernetes всё чаще рассматривают не просто как платформу для микросервисов, а как основу для AI workloads. Он позволяет объединить вычисления, сеть, хранилище, деплойменты, мониторинг и политики доступа в единую управляемую среду. Для AI inference это особенно важно: нагрузка может быть непредсказуемой, GPU стоят дорого, а задержка ответа напрямую влияет на пользовательский опыт. В этой статье разберём, как построить Kubernetes-платформу для inference-задач с помощью KServe, NVIDIA GPU Operator, Kueue и autoscaling. Рассмотрим, какую роль играет каждый компонент, как они связаны между собой и на что обратить внимание при проектировании production-инфраструктуры для ML и LLM-сервисов.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Почему AI inference требует отдельного подхода
Inference - это этап, на котором обученная модель отвечает на реальные запросы. Это может быть классификация изображений, генерация текста, ранжирование, поиск по эмбеддингам, speech-to-text, fraud detection или внутренний корпоративный AI-ассистент. На первый взгляд, inference похож на обычный backend-сервис: есть API, есть входящий трафик, есть SLA. Но на практике AI inference сложнее по нескольким причинам. Во-первых, ресурсы распределяются иначе. Классический веб-сервис часто масштабируется по CPU и памяти. ML-модель может упираться в GPU memory, CUDA kernels, batch size, длину контекста, количество одновременных запросов или скорость токенизации. Во-вторых, стоимость ошибки выше. Если обычный сервис держит лишние CPU-поды, это неприятно, но не всегда критично. Если же простаивают GPU, расходы растут намного быстрее. При этом агрессивное сокращение реплик может привести к холодным стартам и росту latency. В-третьих, разные типы AI-нагрузок требуют разных стратегий. Онлайн inference должен отвечать быстро. Batch inference может ждать в очереди, но должен эффективно использовать доступные ускорители. LLM inference может требовать особого autoscaling по числу запросов, tokens per second, queue depth или latency, а не только по CPU. Поэтому Kubernetes для AI inference - это не просто Deployment с контейнером модели. Это полноценный слой управления ML-сервисами, GPU-нодами, очередями, квотами и масштабированием.
Inference vs обычный backend
Разные узкие места, стоимость простоя и метрики масштабирования.
Базовая архитектура Kubernetes-платформы для inference
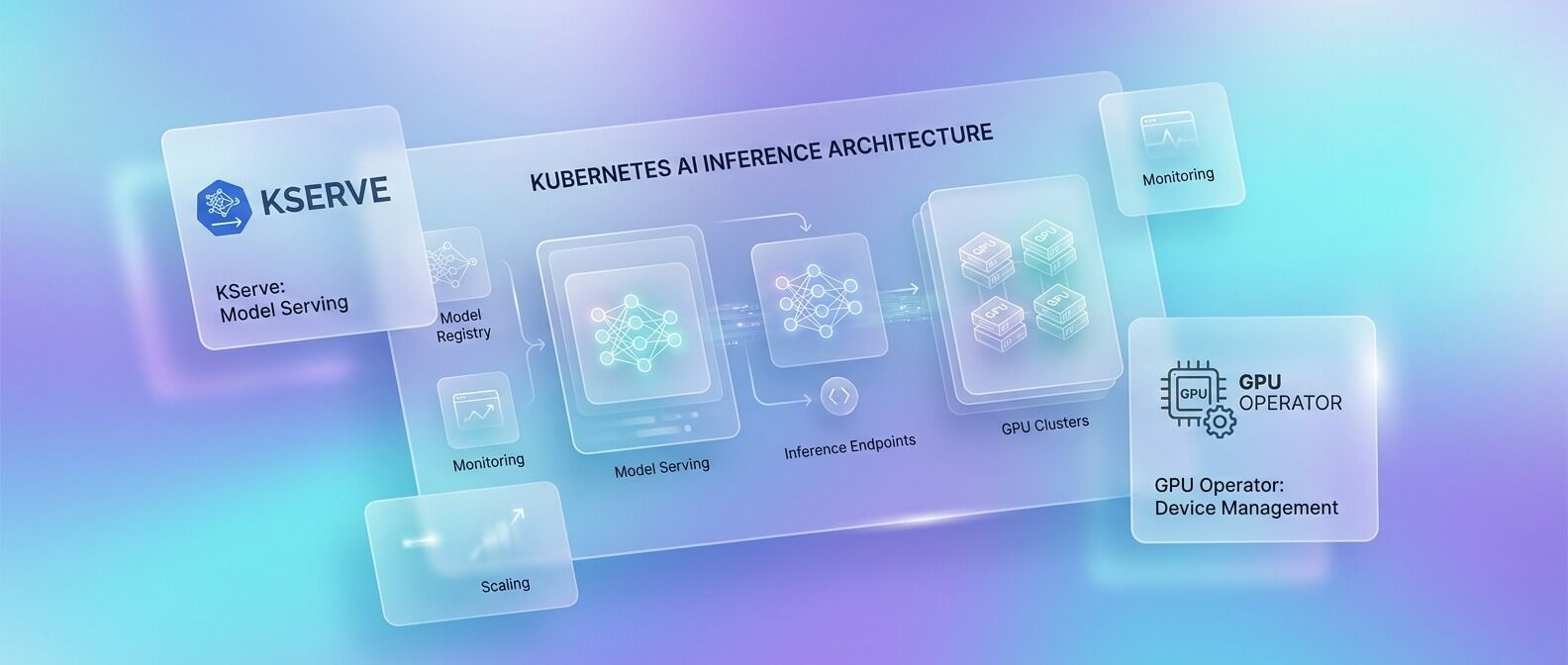
Типовая архитектура может выглядеть так
• GPU-ноды в Kubernetes-кластере предоставляют вычислительные ресурсы для моделей.
• NVIDIA GPU Operator подготавливает эти ноды: драйверы, device plugin, container runtime integration, мониторинг.
• KServe управляет деплоем моделей через Kubernetes-native API и создаёт InferenceService.
• Autoscaling масштабирует inference-сервисы по метрикам нагрузки.
• Kueue управляет очередями и квотами для batch inference, training jobs и других AI workloads.
• Observability-стек собирает метрики по latency, GPU utilization, памяти, очередям и ошибкам.
• CI/CD или MLOps-пайплайн доставляет новые версии моделей в production.
Такой подход позволяет разделить ответственность. GPU Operator отвечает за корректную работу GPU в Kubernetes. KServe отвечает за serving моделей. Kueue помогает управлять конкуренцией за дорогие ресурсы. Autoscaling снижает ручную работу и помогает балансировать производительность и стоимость.
Слои платформы inference
Каждый компонент закрывает свой уровень: железо, serving, очереди, масштаб.
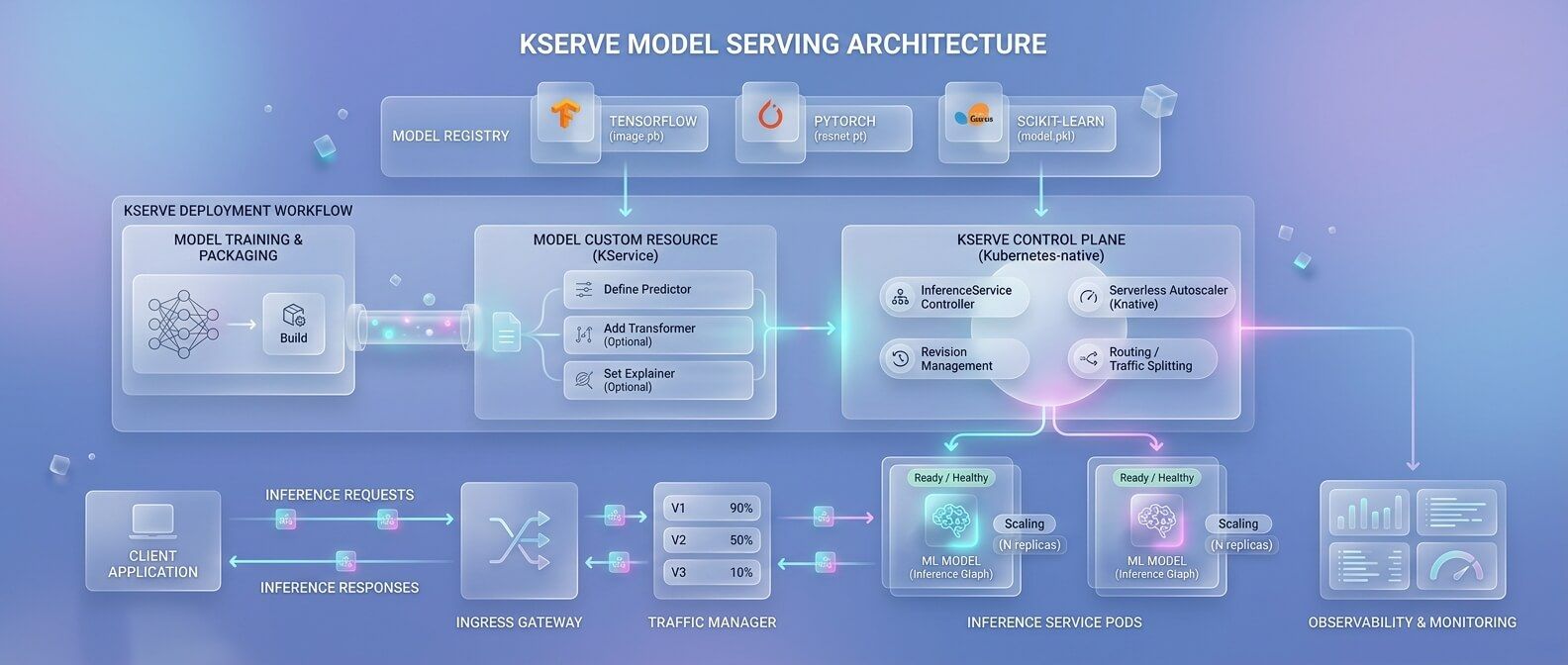
KServe: Kubernetes-native serving для моделей
KServe - один из ключевых компонентов для production inference в Kubernetes. Он предоставляет специальный Kubernetes Custom Resource Definition - InferenceService. Вместо того чтобы вручную собирать Deployment, Service, ingress, probes и autoscaling для каждой модели, команда описывает модель декларативно. Примерно на уровне идеи это выглядит так: инфраструктурная команда настраивает платформу, а ML-команда публикует модель через InferenceService, указывая формат модели, runtime, ресурсы и путь к артефактам. KServe полезен тем, что снимает часть операционной сложности. Он может управлять lifecycle модели, маршрутизацией трафика, canary rollout, health checks, pre/post-processing и масштабированием. Для разных типов моделей можно использовать разные serving runtimes: TensorFlow, PyTorch, ONNX, scikit-learn, XGBoost, Hugging Face, vLLM и другие варианты в зависимости от конкретной задачи. Для бизнеса это важно по простой причине: ML-модели перестают быть «ручными сервисами», которые каждый раз деплоятся по-своему. Появляется единый стандарт: как модель публикуется, как получает трафик, как мониторится, как масштабируется и как откатывается.
GPU Operator: подготовка GPU-нод без ручной настройки
GPU в Kubernetes требуют больше подготовки, чем обычные CPU-ноды. Нужны драйверы NVIDIA, CUDA-совместимая среда, container runtime integration, Kubernetes device plugin, node labels, мониторинг и дополнительные компоненты для корректного распределения GPU между подами. Если всё это настраивать вручную, инфраструктура быстро становится хрупкой. Разные версии драйверов, разные образы нод, разные runtime-настройки и ручные обновления создают риск простоев. NVIDIA GPU Operator решает эту проблему через operator-подход. Он автоматизирует установку и сопровождение необходимых компонентов для GPU-нод внутри Kubernetes. В результате администратор может добавлять GPU-ноды в кластер более предсказуемо, а Kubernetes начинает видеть GPU как schedulable resource, например nvidia.com/gpu. Это особенно полезно в сценариях, где кластер должен масштабироваться: добавляются новые GPU-ноды, меняется пул оборудования, обновляются драйверы или появляются разные типы ускорителей. GPU Operator помогает стандартизировать этот слой и уменьшить количество ручных операций.
Kueue: очередь и квоты для AI workloads

Не все AI-задачи одинаковы. Онлайн inference должен отвечать сразу, а batch inference или training job могут подождать, если сейчас нет свободных GPU. Но если все команды запускают задачи напрямую в Kubernetes, начинается конкуренция за ресурсы: одни workload забирают GPU, другие не стартуют, приоритеты неочевидны, а capacity planning превращается в ручное администрирование. Kueue добавляет Kubernetes-native механизм очередей для batch, HPC и AI/ML workloads. Его задача - решить, когда workload можно допустить к выполнению с учётом доступных ресурсов, квот, приоритетов и политик. Это особенно важно для multi-tenant AI-платформы, где одним кластером пользуются разные команды: ML-инженеры, data science, backend, research, internal tools. Kueue позволяет вводить локальные очереди, кластеры ресурсов, квоты и правила распределения capacity между командами. В контексте inference Kueue особенно полезен для batch inference: например, когда нужно обработать миллионы документов, пересчитать эмбеддинги, прогнать offline scoring или выполнить массовую генерацию. Такие задачи не всегда должны конкурировать с latency-sensitive online inference. Их можно поставить в очередь, ограничить квотой и запускать тогда, когда есть свободные GPU.
Kueue: кто получает GPU
Online inference — сразу; batch — в очередь с квотами и приоритетами.
Autoscaling: масштабирование не только по CPU

Для обычных Kubernetes-приложений часто достаточно Horizontal Pod Autoscaler, который масштабирует поды по CPU или memory metrics. Для AI inference этого обычно мало. Модель может быть перегружена, даже если CPU выглядит нормально. Узким местом может быть GPU memory, очередь запросов, batch latency, число активных sequence, tokens per second, requests per second или P95/P99 latency. Поэтому autoscaling для inference должен опираться на метрики, которые действительно отражают состояние модели.
В Kubernetes-экосистеме есть несколько подходов
• HPA для базового масштабирования по CPU, памяти или custom metrics.
• KEDA для event-driven autoscaling и масштабирования по внешним метрикам.
• Knative-based scaling, включая request/concurrency-based подходы и scale-to-zero в подходящих сценариях.
• Cluster Autoscaler или аналоги для добавления и удаления нод.
• GPU-aware metrics через DCGM Exporter, Prometheus и observability-стек.
Для LLM inference часто имеет смысл масштабироваться не по CPU, а по метрикам очереди и производительности модели: queue depth, active requests, time to first token, tokens per second, GPU utilization, memory usage. Если использовать только CPU, autoscaler может не увидеть реальную перегрузку или среагировать слишком поздно.
Как связать KServe и autoscaling
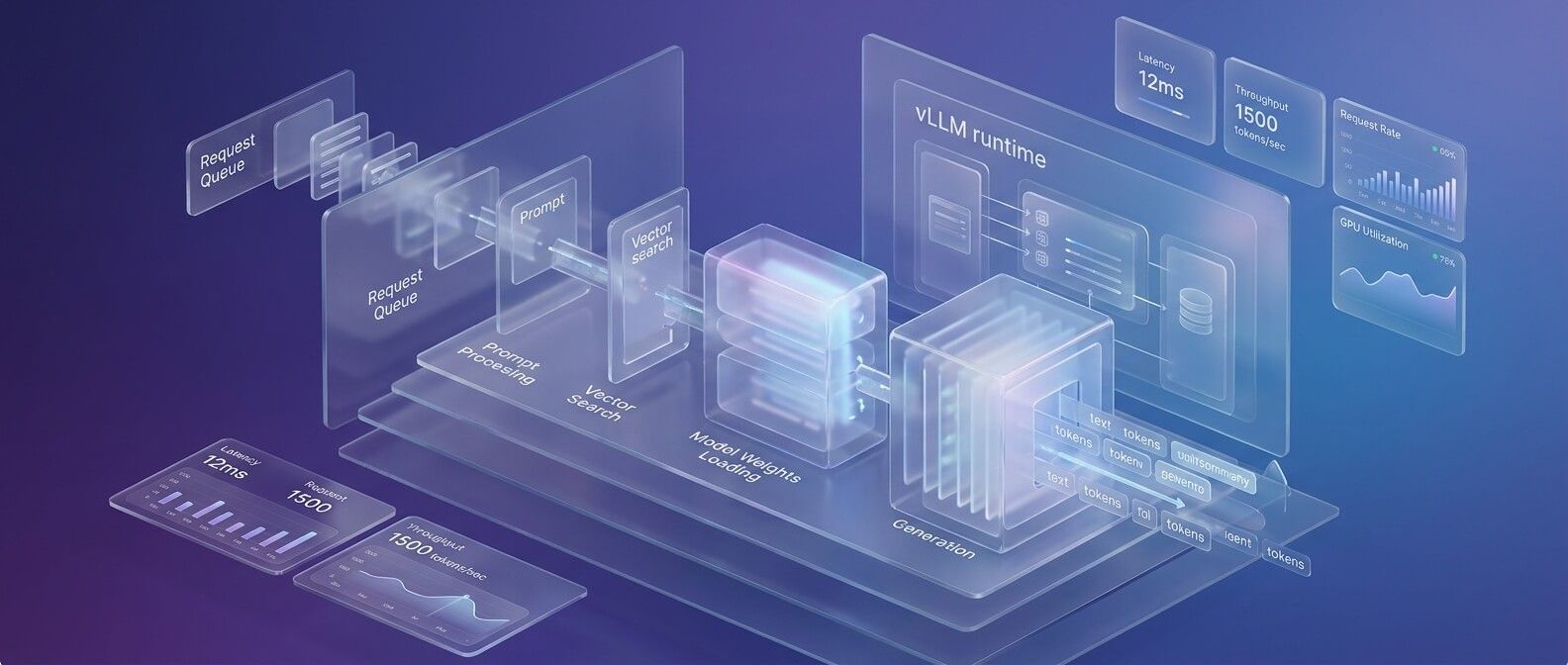
KServe помогает стандартизировать serving, а autoscaling делает его адаптивным к нагрузке. В простом сценарии модель разворачивается как InferenceService, а масштабирование настраивается через поддерживаемые механизмы платформы. Для небольших моделей можно начать с базового autoscaling по concurrency или request metrics. Для более сложных LLM-сервисов лучше подключать Prometheus и KEDA, чтобы масштабировать InferenceService по кастомным метрикам. Например, если очередь запросов растёт, KEDA может увеличить число реплик inference runtime. Если нагрузка падает, количество реплик сокращается. Однако для GPU inference важно учитывать один нюанс: масштабирование подов и масштабирование GPU-нод - разные процессы. Если в кластере уже есть свободные GPU, новая реплика может стартовать быстро. Если свободных GPU нет, Kubernetes должен дождаться появления новой ноды или освобождения ресурсов. Поэтому autoscaling нужно проектировать вместе с node provisioning, квотами и приоритетами. Также нельзя забывать о cold start. Большая модель может загружаться десятки секунд или минуты, особенно если нужно скачать веса из object storage и инициализировать runtime. Для latency-sensitive production-сервисов scale-to-zero нужно использовать осторожно. Он хорошо подходит для dev, staging, внутренних инструментов или нерегулярных задач, но для публичного API может быть неприемлемым.
KServe + autoscaling
Масштабирование подов и появление GPU-нод — разные контуры.
Cold start больших моделей: scale-to-zero осторожно для публичного API.
Online inference и batch inference: разные стратегии
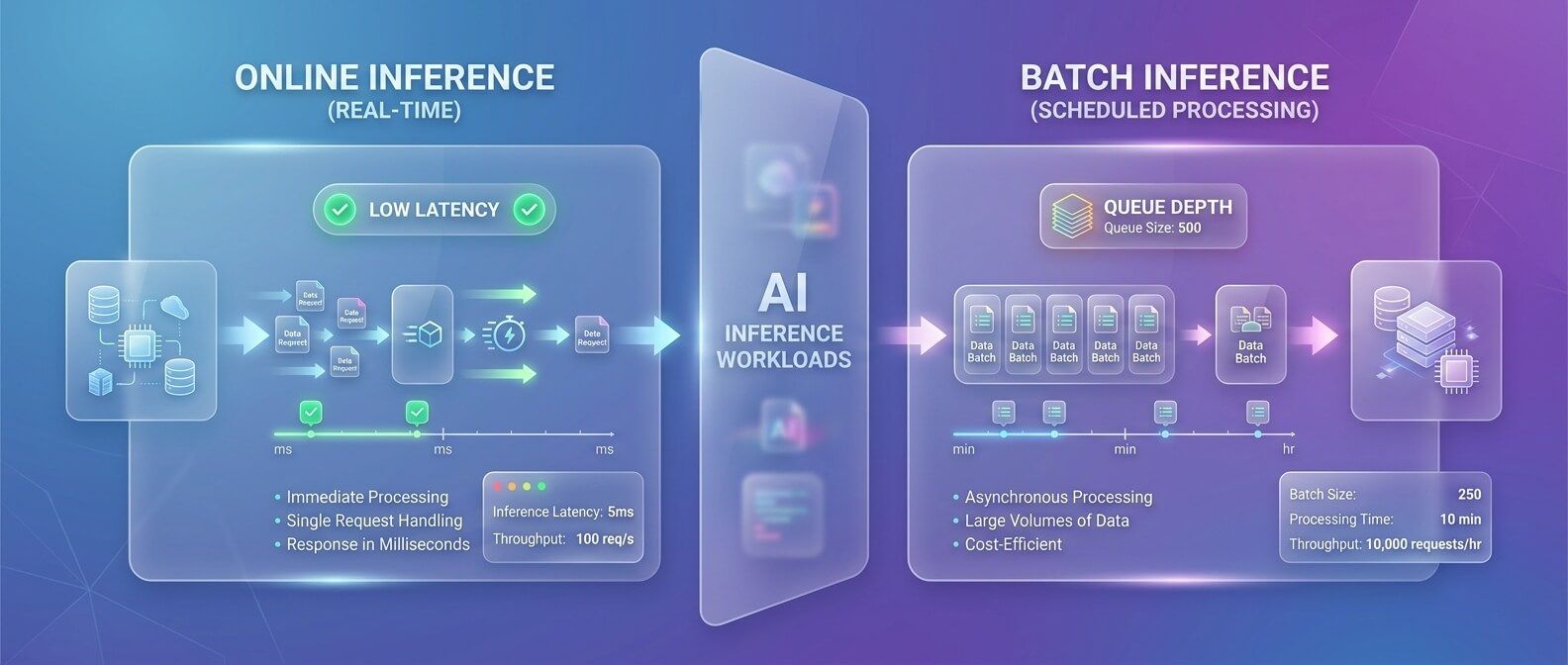
Одна из частых ошибок - пытаться обслуживать все AI-нагрузки одинаково. На практике online inference и batch inference нужно проектировать по-разному. Online inference требует низкой задержки и предсказуемой доступности. Здесь важны: минимальное количество всегда доступных реплик; быстрый health checking; защита от перегрузки; autoscaling по latency, concurrency или queue depth; отдельные GPU-пулы для production; понятные SLO и алерты. Batch inference оптимизируется иначе. Здесь важны: высокая утилизация GPU; очереди и приоритеты; квоты между командами; возможность запускать большие job без влияния на production API; контроль стоимости; повторяемость и логирование результатов. Kueue хорошо закрывает именно batch-часть. KServe хорошо закрывает online serving. В зрелой платформе эти подходы не конкурируют, а дополняют друг друга.
Практический сценарий: LLM-сервис в Kubernetes
Представим, что компания запускает внутреннего AI-ассистента на базе LLM. На старте это может быть один GPU-сервер с моделью, поднятой через vLLM или другой inference runtime. Но затем появляются новые пользователи, растёт количество запросов, добавляются новые модели, появляются batch-задачи для обработки документов.
На этом этапе архитектура может развиваться так
• GPU-серверы объединяются в Kubernetes-кластер.
• NVIDIA GPU Operator управляет GPU-нодами.
• Модель разворачивается через KServe как InferenceService.
• Метрики runtime отправляются в Prometheus.
• KEDA масштабирует сервис по queue depth, concurrency или другим метрикам.
• Kueue управляет batch-задачами: пересчётом эмбеддингов, offline inference, тестовыми прогонами.
• Production inference и batch workloads разделяются по node pools, taints, tolerations, quotas и priority classes.
• Observability показывает не только CPU и память, но и GPU utilization, GPU memory, latency, error rate, throughput и стоимость простоя.
Такой подход позволяет постепенно перейти от «одна модель на одном сервере» к полноценной AI-платформе без полного переписывания инфраструктуры.
Эволюция LLM-сервиса
От одного GPU-сервера к платформе без полного переписывания.
На что обратить внимание при проектировании
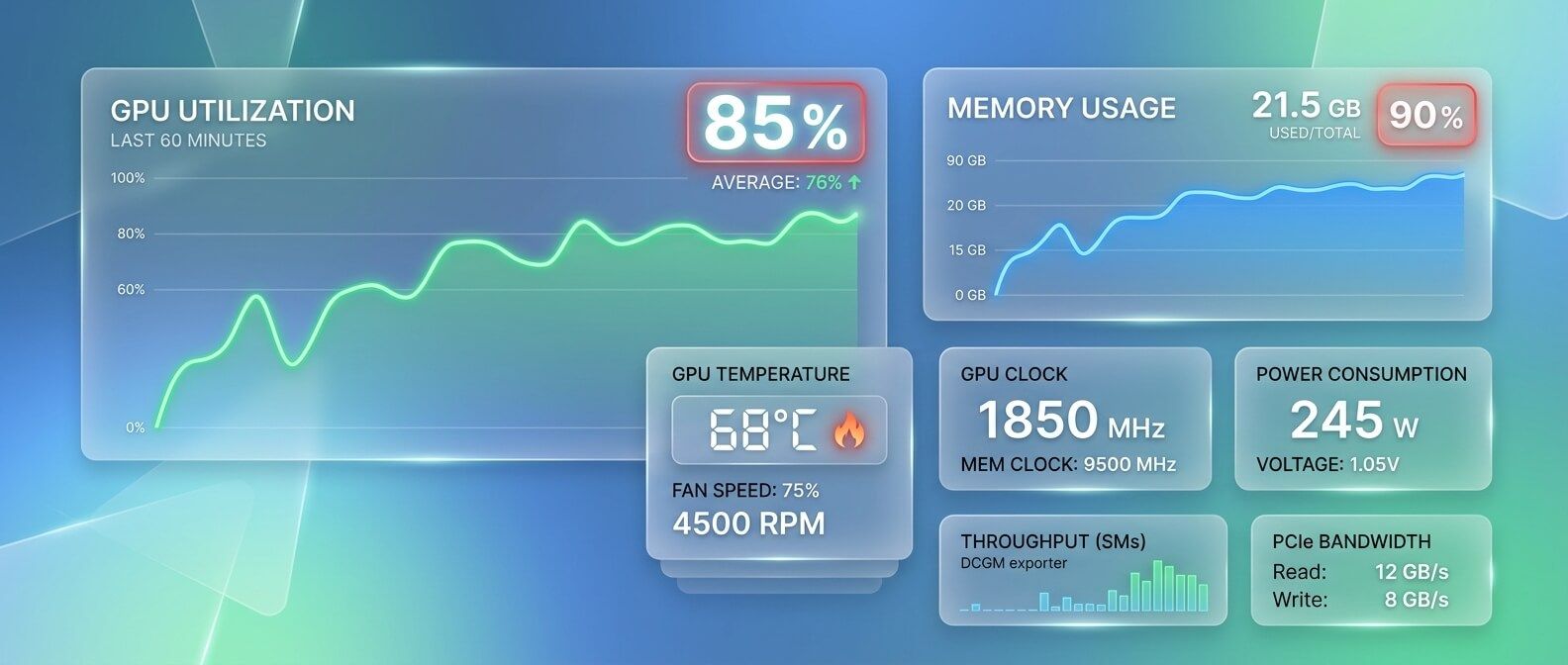
1. GPU - самый дорогой ресурс
Главная цель инфраструктуры для AI inference - не просто «запустить модель», а эффективно использовать GPU. Если GPU простаивают, проект переплачивает. Если GPU перегружены, растёт latency. Поэтому нужно мониторить не только Kubernetes-метрики, но и GPU-метрики: utilization, memory, temperature, throttling, ошибки, распределение нагрузки между подами.
2. Метрики autoscaling должны соответствовать workload
CPU-based autoscaling может быть недостаточным. Для LLM и heavy inference лучше использовать метрики, связанные с реальным поведением модели: длина очереди, активные запросы, latency, tokens per second, batch size, GPU memory.
3. Не все модели стоит масштабировать одинаково
Маленькая модель может стартовать быстро и масштабироваться агрессивно. Большая LLM может долго загружаться и требовать warm pool. Для критичных API лучше держать минимальное количество реплик, даже если нагрузка временно упала.
4. Batch-задачи нужно изолировать от production inference
Если batch inference запускается в том же GPU-пуле без ограничений, он может вытеснить production-нагрузку. Kueue, quotas, priority classes, node pools и taints помогают разделить эти сценарии.
5. Storage влияет на скорость старта
Большие модели требуют быстрой доставки весов. Если каждый pod заново скачивает десятки или сотни гигабайт, autoscaling будет медленным. Нужны продуманные стратегии хранения: object storage, локальный cache, pre-pulled artifacts, persistent volumes или специализированные механизмы кеширования.
6. Observability должна быть end-to-end
Недостаточно видеть, что pod работает. Нужно понимать, сколько времени занимает запрос, где возникает очередь, как загружен GPU, сколько ошибок возвращает runtime, как меняется P95/P99 latency и какие модели потребляют больше всего ресурсов.
Когда Kubernetes для AI inference оправдан

Kubernetes не всегда нужен с первого дня. Если у проекта одна модель, один GPU-сервер и небольшая команда, проще начать с более прямой архитектуры. Но Kubernetes становится оправданным, когда появляются: несколько моделей или версий моделей; несколько команд, которым нужны общие GPU-ресурсы; переменная нагрузка; требования к отказоустойчивости; batch inference и online inference одновременно; необходимость в квотах и приоритетах; CI/CD и MLOps-пайплайны; требования к мониторингу, безопасности и изоляции. Иными словами, Kubernetes нужен тогда, когда AI-инфраструктура становится платформой, а не единичным сервером.
Роль выделенной инфраструктуры
Для AI inference важна не только оркестрация, но и базовая инфраструктура: CPU, GPU, сеть, диски, пропускная способность, отказоустойчивость и предсказуемость ресурсов. Kubernetes может эффективно управлять workload, но он не компенсирует слабую аппаратную базу. Выделенные серверы и GPU-инфраструктура дают больше контроля над производительностью, сетью, хранением данных и стоимостью. Это особенно важно для проектов, где нужно держать стабильную latency, работать с чувствительными данными, строить приватные AI-сервисы или избегать непредсказуемости shared-среды. Для бизнеса оптимальная стратегия часто выглядит как поэтапный рост: сначала отдельный GPU-сервер для прототипа, затем несколько серверов под production inference, затем Kubernetes-кластер с GPU Operator, KServe, Kueue и полноценным мониторингом.
Поэтапный рост инфраструктуры
Kubernetes не заменяет сильную аппаратную базу — он управляет workload поверх неё.
Итоги
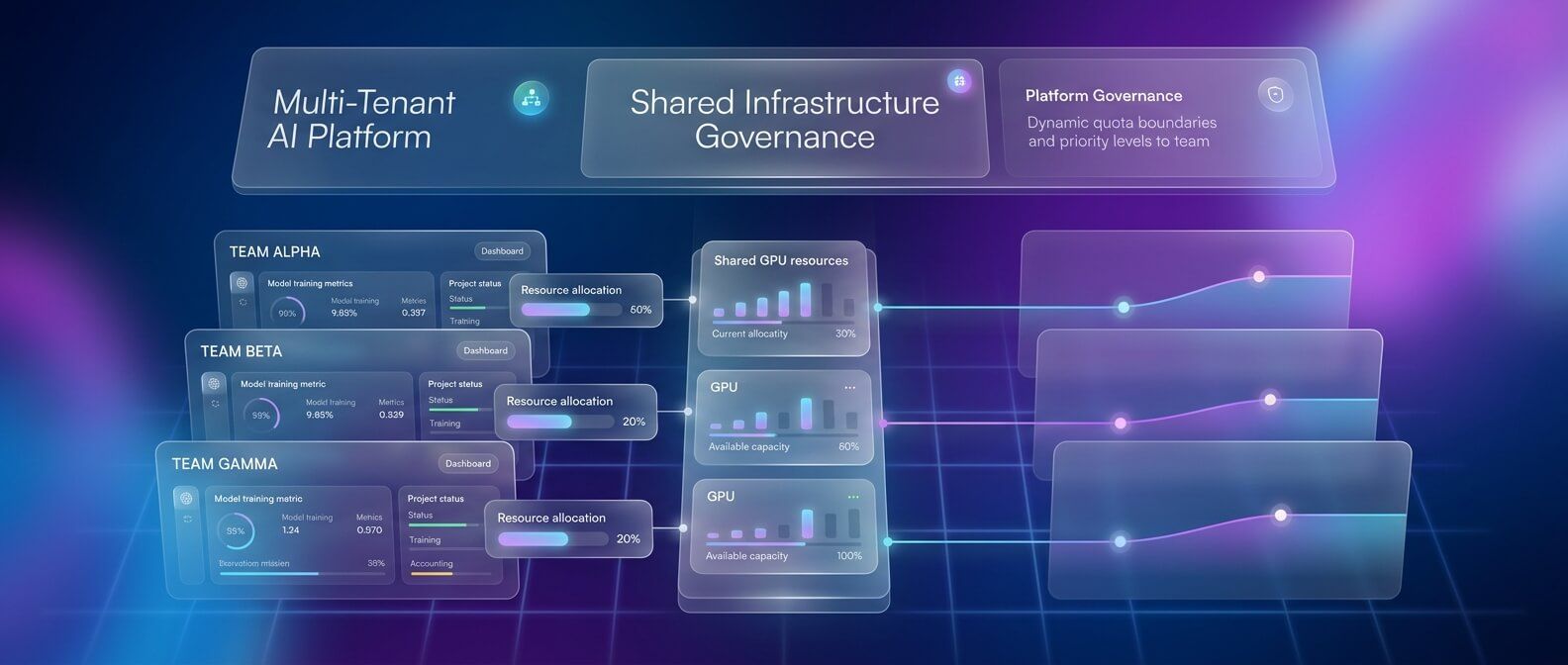
Kubernetes становится одной из ключевых платформ для AI workloads, потому что позволяет управлять моделями, GPU, очередями и масштабированием в единой среде. Но для inference-задач важно использовать правильные компоненты. KServe стандартизирует публикацию моделей и превращает serving в Kubernetes-native процесс. NVIDIA GPU Operator упрощает подготовку и сопровождение GPU-нод. Kueue помогает управлять batch-задачами, квотами и конкуренцией за ресурсы. Autoscaling позволяет адаптировать inference-сервисы к реальной нагрузке, если он построен на правильных метриках. Главный принцип такой архитектуры - разделять типы нагрузок и управлять GPU как дорогим, ограниченным ресурсом. Online inference требует низкой задержки и предсказуемости. Batch inference требует очередей и высокой утилизации. Kubernetes позволяет объединить оба сценария, но только при грамотной настройке scheduling, autoscaling, observability и инфраструктурного слоя. Если AI-проект уже вырос из одного сервера и требует масштабирования, отказоустойчивости и контроля затрат, Kubernetes-стек с KServe, GPU Operator, Kueue и продуманным autoscaling может стать основой зрелой production-платформы для inference.




