




















Оглавление
Введение
Сегодня нейросетевые модели работают с контекстом, о котором пару лет назад и мечтать было сложно. GPT-4, например, поддерживает до 32 000 токенов в контексте, MosaicML MPT – до 65 000, а модель Claude от Anthropic – вплоть до 100 000 токенов. Это открывает потрясающие возможности – от анализа длинных документов до сложных диалогов. Но есть и обратная сторона: классическое самовнимание (self-attention) в Transformer-ах не справляется с такими объемами без ощутимых тормозов. Его вычислительная сложность растет квадратично с длиной последовательности, и на больших вводах модель начинает «тормозить», требуя гигабайты памяти и секунды, а то и минуты вычислений. А время – это не только ожидание пользователя, но и прямые расходы на GPU.
Хорошая новость: ускорить Transformer-модель можно в разы без потери качества ответа и без замены всего вашего ML-стека. Звучит почти как магия, но это реальность. Встречайте FlashAttention и специальные fused attention-ядра – методы, благодаря которым механизм внимания работает молниеносно, а стоимость вывода снижается. В этой статье мы разберемся, что это за техники, почему о них сейчас говорят все, и – главное – как внедрить такое ускорение Transformer-моделей в существующую инфраструктуру (PyTorch, Hugging Face и др.) без лишней боли. К слову, ничего кардинально переписывать не придется. Поехали!

Узкое место Transformer: внимание, которое все замедляет
Чтобы понять ценность FlashAttention, давайте сначала посмотрим, почему стандартный механизм внимания стал бутылочным горлышком. В архитектуре Transformer именно слои самовнимания позволяют модели учитывать взаимосвязи между всеми токенами входа. Но плата за эту “магию контекста” – квадратичная сложность. Если последовательность из 1000 токенов еще не проблема, то при 16 000 токенах требования растут взрывным образом. Пик использования памяти и число операций растут пропорционально $N^2$, где $N$ – длина последовательности. Представьте: увеличить контекст в 2 раза – и вычислений потребуется примерно в 4 раза больше.
Почему так происходит? В классическом алгоритме внимание необходимо вычислить матрицу размером $N \times N$ (для каждого из $N$ токенов степень важности всех $N$ токенов-входов). Эта матрица весов внимания затем нормируется через Softmax и применяется к значениям $V$. В наивной реализации приходится хранить огромную промежуточную матрицу весов и выполнять тонну операций над ней. Более того, все эти данные хранятся в памяти GPU и многократно читаются-записываются.
Метафора: представьте офис, где у вас есть быстрый, но маленький стол и большой, но медленный архив с документами в соседней комнате. Стандартный алгоритм attention действует так: для каждого пары слов он бегает в “архив” (глубокая память GPU, часто называемая HBM – High Bandwidth Memory) за данными, делает небольшую работу и снова пишет результат в архив. И так тысячи раз – отсюда и квадратичные задержки. Неудивительно, что при длинных последовательностях модель тратит больше времени на передачи данных, чем на сами вычисления. В итоге ваши дорогие GPU простаивают в ожидании данных, а пользователи – в ожидании ответа.

FlashAttention и fused attention: в чем суть и почему это важно
Как сделать так, чтобы самовнимание работало быстрее? Идея FlashAttention родилась из наблюдения: а что, если изменить порядок вычислений и хранить промежуточные результаты не в “медленной” памяти, а прямо в сверхбыстром внутреннем кеше GPU? GPU имеют небольшую on-chip SRAM – условно, “рабочий стол” – которая намного быстрее, чем основная память (HBM), но традиционный алгоритм attention неэффективно ее использует. FlashAttention – это алгоритм, который переупорядочивает вычисления внимания и выполняет их блочно (tile-based), так чтобы все промежуточные шаги укладывались в быстрый SRAM кэш. Проще говоря, модель обрабатывает внимание не целиком на все 10000 токенов сразу, а небольшими блоками – загружает пару сотен токенов из HBM в быстрый SRAM, вычисляет частичные результаты softmax для них, сразу применяет их к значениям и переходит к следующим. Благодаря этому больше не нужно хранить всю огромную матрицу внимания (размером $N \times N$) в памяти – она обрабатывается по частям. Итог – использование памяти снижается с квадратичного до линейного по $N$! Все промежуточные данные “живут” на чипе и не гоняются туда-сюда по шине памяти.
И правда, FlashAttention оправдывает свое название – внимание “вспыхивает” и работает гораздо быстрее. Убирая лишние чтения-записи, алгоритм достигает 2–4-кратного ускорения wall-clock времени по сравнению со стандартными реализациями уже в первой версии. Причем это точный метод: он выдает те же самые результаты, что и обычный softmax-attention, только делает это эффективнее. Никаких приближений, никакой потери качества – просто лучше организация вычислений. Математически FlashAttention эквивалентен классическому вниманию, так что вам не нужно беспокоиться о точности вывода или регрессиях.
Важно отметить: современные GPU способны выполнять ошеломляющее число операций в секунду, но узким местом все чаще становится не сама математика, а скорость доступа к памяти. FlashAttention как раз сокращает объем лишней работы – он “сливает” несколько шагов внимания в один и держит данные там, где GPU может работать с ними максимально быстро (в SRAM). По сути, FlashAttention – это уже и есть fused attention-ядро для современных ускорителей. Он объединяет в одном CUDA-ядре сразу несколько операций: расчет матрицы $QK^T$, вычисление softmax, умножение на $V$ и применение масок. В классическом PyTorch эти шаги выполнялись бы раздельно, с сохранением результатов каждого шага в памяти. FlashAttention делает их за один проход, на лету сохраняя необходимые промежуточные скалярные величины для корректного softmax-нормирования. Такой fusion экономит тонны времени на запуск ядер и на обращения к памяти.
Раз уж мы заговорили о fused attention: под этим термином обычно понимают любые специально оптимизированные реализации механизма внимания, где стандартные операции “склеены” в единый высокопроизводительный CUDA- или Triton-ядро. FlashAttention – яркий пример fused-ядра, разработанный изначально исследователями Стэнфорда (Tri Dao и коллегами). Параллельно сообществом были созданы и другие fused attention реализации – например, в библиотеке xFormers от Meta есть свой Memory-Efficient Attention. По сути, xFormers предлагает аналогичные идеи блочного вычисления и сбережения памяти, благодаря чему его производительность сопоставима с FlashAttention v2 (за счет схожего тильного алгоритма). Главное, что нужно понимать: fused attention ядра – это способ заставить вашу модель тратить больше времени на полезные умножения матриц на тензорных ядрах GPU и меньше – на бессмысленные перемещения данных. И результаты впечатляют. В недавнем обновлении PyTorch 2.2 интегрировали FlashAttention v2 прямо в стандартную функцию внимания, добившись двукратного ускорения по сравнению с предыдущей версией и достигая ~50–70% от теоретического предела производительности на A100. Для сравнения, первая версия FlashAttention использовала потенциал GPU лишь на 25–40% – так что прогресс налицо.
Еще немного цифр: FlashAttention-2 (вторая версия) переписана на низкоуровневых библиотеках Nvidia CUTLASS/CuTe и за счет лучшей распараллеливации дала еще +2х к скорости относительно FlashAttention-1. В абсолютных величинах на A100 это около 230 TFLOPs/s, что соответствует 72% загрузки вычислительных блоков GPU – весьма близко к “железному” потолку! И это достижимо без каких-либо специальных Tensor Core инструкций нового поколения – на тех же видеокартах, просто более продуманным кодом ядра. Таким образом, FlashAttention и родственные fused attention реализации превращают “тормоз” Transformer-а в его двигатель: внимание больше не ограничивает скорость модели так сильно, даже при длинных контекстах.
Аналогия: если обычный self-attention – это как читать огромную книгу, отвлекаясь после каждой страницы, чтобы сбегать в библиотеку за следующей главой, то FlashAttention берет сразу всю нужную главу и кладет к вам на стол. Вы читаете быстрее, потому что не делаете тысячи лишних движений. Именно поэтому FlashAttention и подобные ему ускорения стали столь важны в практике – они позволяют масштабировать модели (по длине контекста, по размеру батча) без взрывного роста времени ответа и потребления памяти.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Интеграция в вашу ML-инфраструктуру: просто как переключатель
Вы, вероятно, думаете: “Здорово, но насколько трудно внедрить эти ускорения? Нужно ли переписывать мой код на CUDA или покупать новые GPU?”. К счастью, ни того ни другого – не нужно. Современные фреймворки уже сделали тяжелую работу за нас. Рассказываем, как использовать FlashAttention и fused attention на практике, шаг за шагом.
PyTorch: внимание на максимальной скорости
Начиная с PyTorch 2.0, поддержка эффективного внимания встроена прямо в библиотеку. В PyTorch появилась функция torch.nn.functional.scaled_dot_product_attention (SDPA), которая под капотом умеет сама выбирать оптимальный бэкенд. Если ваша модель определена через стандартные слои типа nn.MultiheadAttention или TransformerEncoder, то в новых версиях фреймворка эти слои автоматически могут использовать fused attention ядра. Проще говоря, разработчики PyTorch включили FlashAttention “по умолчанию” – при условии, что вы запускаете модель на совместимом GPU и с подходящими тензорными типами. Например, для FP16/BF16 тензоров на NVIDIA GPU подходящей архитектуры PyTorch попытается использовать FlashAttention или Xformers (Memory-Efficient Attention) вместо наивной реализации.
По умолчанию движок сам решает, какой вариант быстрее для текущих данных, но вы можете и вручную управлять выбором. Например, с помощью контекстного менеджера torch.backends.cuda.sdp_kernel() можно явно включить или отключить FlashAttention и другие ядра. Так, если вы хотите убедиться, что используется именно FlashAttention, можно сделать:
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False): out = F.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=0.0)
Здесь мы принудительно включаем FlashAttention и отключаемfallback-реализацию (“math”) и xFormers. В реальности так делать почти не требуется – PyTorch сам выберет лучшее. Но иметь такую возможность полезно для отладки или бенчмарков. Также есть глобальные флаги torch.backends.cuda.enable_flash_sdp(True) и др., если нужно задать поведение на уровне всего процесса.
Важно: чтобы эти ускорения заработали, убедитесь, что вы используете актуальную версию PyTorch и подходящую сборку под вашу CUDA. Например, FlashAttention v2 полностью интегрирован с версии PyTorch 2.2 – обновление до нее может дать прирост скорости “из коробки”. Если же вы по каким-то причинам не можете обновиться, есть альтернативный путь: установка сторонней библиотеки flash-attention от DAO-AI Lab (авторы алгоритма). Она предоставляет готовые CUDA-ядра FlashAttention (v1 и v2) и удобные Python-обертки. После установки можно напрямую вызывать функцию внимания оттуда или патчить модель. Однако в большинстве случаев достаточно обновить PyTorch – и никаких дополнительных действий не потребуется, встроенный PyTorch attention уже ускорен.

Hugging Face Transformers: ускорение одним вызовом
Если вы пользуетесь экосистемой Hugging Face, то для вас все тоже довольно просто. Библиотека Transformers уже включает интеграции как с PyTorch flash attention, так и с xFormers. Более того, есть удобный утилитарный метод, позволяющий превратить вашу модель в ускоренную версию одной строкой. Речь про функцию model.to_bettertransformer() из пакета 🤗 Accelerate (так называемый Better Transformers). Этот вызов преобразует слои вашей модели (например, BertSelfAttention или блоки GPT) в эквивалент, использующий scaled_dot_product_attention из PyTorch. То есть, по сути, включает FlashAttention там, где это поддерживается. После to_bettertransformer модель должна выдавать те же результаты, но работать быстрее – особенно на больших контекстах.
Другой вариант – использовать xFormers напрямую в Transformers. Разработчики Hugging Face добавили метод model.enable_xformers_memory_efficient_attention(), который переключает внимание модели на реализацию из библиотеки xFormers. Предварительно нужно установить сам пакет xformers (pip install xformers). Зато дальше – никакой возни: одна строчка включения, и вуаля – ускорение Transformer-модели в действии. Например:
from transformers import AutoModelForSeq2SeqLMmodel = AutoModelForSeq2SeqLM.from_pretrained("t5-large").to("cuda")model.enable_xformers_memory_efficient_attention()
После этого все вызовы `model(...)" под капотом будут использовать fused attention ядро из xFormers вместо стандартного матмуль+софтмакс.
Стоит отметить, что в новых версиях Transformers некоторые модели можно загружать сразу с указанной реализацией внимания. В конструкторе from_pretrained появился параметр attn_implementation, куда можно передать значения вроде "flash_attention" или "flash_attention_2" для моделей, поддерживающих FlashAttention v2. Например:
model = AutoModelForCausalLM.from_pretrained( "bigscience/bloomz-7b1", attn_implementation="flash_attention")
Это экспериментальная возможность, но она сигнализирует: Hugging Face активно внедряет fused attention в свои модели. Ведь выигрыш очевиден – как в скорости, так и в памяти.
Напоследок, если вы используете Inference API или Text Generation Inference (TGI) для деплоя моделей, там тоже добавили поддержку FlashAttention. Многие популярные модели на Hugging Face Hub имеют версии с припиской “-flash” – они сконфигурированы для использования FlashAttention при обслуживании запросов. Таким образом, даже на уровне готовых сервисов Hugging Face acceleration техники уже работают на благо скорости выводa.

Triton и свои ядра: для самых любознательных
В большинстве случаев вам не придется писать ничего самому – но мы упомянем и этот путь. Triton – это язык от OpenAI для написания пользовательских GPU-ядер на Python. В умелых руках Triton позволяет создавать высокопроизводительные fused ядра без знания CUDA. Некоторые реализации FlashAttention были переписаны на Triton, и энтузиасты экспериментировали с их оптимизацией. Например, в репозитории flash-attention есть опция собрать ядро на Triton вместо CUDA (особенно актуально для AMD GPU). Если у вашей команды есть экспертиза и специфичные потребности (скажем, особый вариант внимания), вы даже можете реализовать кастомное fused attention ядро сами, используя Triton. Однако это скорее экзотика. Куда проще – воспользоваться готовыми библиотеками: помимо вышеназванных, аналогичные оптимизации присутствуют в Nvidia FasterTransformer, Microsoft DeepSpeed и других ускоряющих инструментах. Многие из них “под капотом” тоже используют идеи FlashAttention или напрямую интегрируют его. Так что выбор богатый.
Но главный вывод этого раздела: внедрение FlashAttention не требует революции. Достаточно обновить версии библиотек и вызвать пару методов, чтобы ваши модели перешли на новую, быструю колею. Ни архитектуру, ни веса, ни привычный вам ML-пайплайн менять не придется. Это редкий случай в глубоком обучении, когда можно получить существенный прирост производительности, практически не прилагая усилий – грех не воспользоваться!

Быстрее, дешевле, лучше: что дают FlashAttention на практике
Слова словами, но давайте посмотрим на конкретные цифры и кейсы, подтверждающие эффективность этих оптимизаций. Ниже – несколько мини-историй о том, как FlashAttention и fused attention уже ускоряют модели и сокращают затраты.
- 2–4 раза быстрее, чем стандартный attention. Авторы FlashAttention в своем блоге показали впечатляющий прирост: благодаря сокращению операций с памятью первый вариант алгоритма давал 2–4× ускорение по сравнению с лучшими базовыми реализациями внимания. Это измерено на тренировке и инференсе модели GPT-стиля с длинным контекстом. И все это – безApproximation, то есть качество модели не изменилось.
- FlashAttention v2 – еще в 2 раза быстрее v1. Улучшив алгоритм (меньше лишних операций, лучше распараллеливание вычислений между потоками), команда ускорила внимание еще примерно вдвое. Например, на A100 GPU FlashAttention-2 показал ~1.3× ускорение конца-в-конец обучения GPT-3 с контекстом 8k токенов поверх уже оптимизированной версии с FlashAttention-1. В числах: модель GPT-3 2.7B с контекстом 8k разогналась с ~80 TFLOPs/s до 175 TFLOPs/s с FA1 и до 225 TFLOPs/s с FA2. Потенциал роста более чем в 2.5 раза! Конечно, в ваших задачах цифры могут отличаться, но тренд очевиден.
- Мгновенный выигрыш в реальном инференсе LLM. Теория – хорошо, а как насчет практики на прикладной модели? В недавнем примере от Hugging Face взяли 15-миллиардную модель-кодогенератор (OctoCoder) и прогнали запрос с длинным контекстом. Результат: время генерации ответа сократилось примерно с 11 секунд до 3 секунд при включении FlashAttention. Трехкратное ускорение отклика! При этом пиковое потребление памяти снизилось с ~37.7 ГБ до ~32.6 ГБ – экономия ~5 ГБ, благодаря чему длинный запрос стал обходиться почти как обычный короткий контекст. Пользователь разницы в качестве ответа не заметил, а разницу в скорости – еще как.
- Ускорение Diffusion-моделей в продакшене. Не только языковые модели выигрывают от fused attention. Компания Photoroom применила memory-efficient attention из xFormers в пайплайне Stable Diffusion для генерации изображений – и добилась драматического прироста скорости. Ниже показана их сравнительная таблица производительности на разных GPU:
На разных поколениях GPU ускоренные ядра внимания (xFormers Memory-Efficient Attention) дают прирост throughput при генерации изображений Stable Diffusion. Например, на Nvidia A10G пропускная способность выросла с ~8.9 до ~15.6 итераций/с (почти +100% скорость). Даже на старых картах вроде T4 улучшение заметно (~57%). Данные: Photoroom.
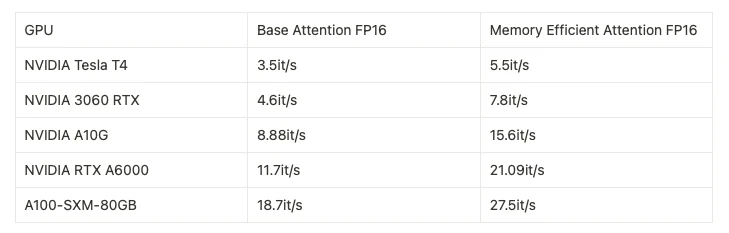
Как видим, ускорение Transformer inference speed напрямую снижает затраты на GPU для тех же задач. В случае Photoroom обновление кода позволило удвоить скорость вывода на облачных GPU A10G. Проще говоря, та же видеокарта теперь справляется с генерированием в 2 раза большего числа изображений в секунду. В пересчете на деньги это означает почти двукратное снижение стоимости обслуживания одного запроса. И всё это – просто заменой операции внимания на ее fused-версию, без тренировки модели с нуля.
Примерно такие же истории происходят повсюду, где внедряют FlashAttention. Если у вас GPT-подобная модель отвечала за 100 мс, можно ожидать сокращения до десятков миллисекунд. Если большой чат-бот тратил 10 секунд на развёрнутый ответ – с оптимизированным вниманием он может уложиться в 3–5 секунд. В производственных масштабах быстрее отклик модели → меньше суммарное GPU-время → снижение затрат на GPU и более довольные пользователи. Стоит подчеркнуть: здесь нет никакого трюка с качеством. Вы не жертвуете ни точностью, ни сложностью модели – она просто работает эффективнее, используя ресурсы железа оптимальным образом.
Заключение
Индустрия машинного обучения стремительно движется вперед, и ускорение Transformer-моделей – яркий тому пример. Еще вчера все смирялись с тем, что внимание – дорогой компонент, а сегодня FlashAttention и прочие fused attention ядра делают его легким и быстрым. Для ML-инженеров и технических директоров это отличная возможность: без апгрейда оборудования получить существенный буст производительности и снизить издержки.
Что особенно приятно, путь к этому апгрейду прост. Большинство популярных фреймворков уже поддерживают нужные оптимизации. Достаточно обновиться до актуальной версии PyTorch или установить xFormers, включить парочку флагов – и ваша модель словно пересела с грузовика на спортивный болид. Практическая выгода очевидна, а риски минимальные.
В заключение хочется отметить: FlashAttention и связанные с ним техники ускорения – это не разовая вспышка, а новый стандарт. Скоростные трансформеры прокладывают дорогу к более долгим контекстам, интерактивным приложениям и снижению барьеров по затратам. Если вы еще не испытали их в деле, самое время попробовать. Дайте вашим моделям фору в скорости – и они ответят вам сторицей, радуя пользователей мгновенными откликами и экономя ваше время и бюджет. Вперед, к оптимизированному будущему Transformer-моделей!




