




















Оглавление
- Что такое evals для LLM простыми словами
- Почему ручная проверка не работает
- Что именно нужно проверять перед запуском LLM
- Тестовые датасеты: фундамент нормальной проверки
- Golden answers: эталонные ответы без иллюзий
- Hallucination rate: как считать галлюцинации
- Regression tests: защита от незаметных поломок
- Проверка после смены модели или промпта
- Автоматические и ручные оценки: что выбрать
- Какие метрики использовать
- Public benchmarks не заменяют ваши evals
- Evals для RAG-систем: отдельная зона риска
- Как собрать первый evals-набор без лишней бюрократии
- Пример evals-таблицы для LLM-ассистента
- Как встроить evals в процесс разработки
- Где запускать evals и почему инфраструктура важна
- Частые ошибки при внедрении evals
- Практическая схема: минимальный evals-процесс для бизнеса
- Когда LLM готова к запуску
- Что важно запомнить
LLM может отлично отвечать на демо, уверенно проходить пару ручных тестов и все равно провалиться в реальной работе. Не потому что модель «плохая», а потому что ее никто нормально не проверил на типовых, сложных и пограничных сценариях. Для бизнеса это особенно опасно. Нейросеть может красиво написать ответ, но перепутать тариф, придумать несуществующее условие, неверно классифицировать заявку или пропустить важный риск в документе. На витрине все выглядит умно. Внутри может быть рулетка. Evals помогают убрать эту рулетку. Это система тестов, по которой команда заранее понимает: модель готова к запуску, промпт не сломал старую логику, новая версия отвечает лучше старой, а уровень галлюцинаций остается в допустимых рамках.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Что такое evals для LLM простыми словами
Evals для LLM, или evaluation tests, это проверка качества нейросетевой системы по заранее подготовленным сценариям. Можно представить это как техосмотр перед выездом на трассу. Машина может завестись, фары могут гореть, музыка играет. Но перед серьезной поездкой важно проверить тормоза, резину, двигатель и поведение на дороге. С LLM похожая история: одного красивого ответа в чате недостаточно.
Evals проверяют не только саму модель. Они проверяют всю цепочку
• системный промпт
• пользовательский промпт
• модель
• настройки температуры и контекста
• RAG-поиск по базе знаний
• инструменты и функции, которые вызывает агент
• формат финального ответа
• безопасность и ограничения.
В современных LLM-проектах evals уже стали частью нормального production-процесса. Например, OpenAI Evals описывается как framework для оценки LLM и систем на их основе, включая возможность создавать собственные приватные evals под реальные рабочие сценарии компании. LangSmith также предлагает строить evaluation workflow вокруг датасетов, evaluators и experiments, чтобы сравнивать поведение LLM-приложения на одинаковых примерах. Главная идея простая: нейросеть нужно проверять не ощущениями, а повторяемыми тестами.
Что проверяют evals
Вся цепочка — не только модель.
Почему ручная проверка не работает

На раннем этапе команда часто тестирует LLM вручную. Открыли чат, задали 10 вопросов, получили нормальные ответы, решили запускать. Проблема в том, что такой подход почти ничего не доказывает. Во-первых, ручные вопросы обычно слишком простые. Люди проверяют очевидные сценарии: «Объясни услугу», «Составь письмо», «Ответь клиенту». А в реальности пользователь спросит криво, неполно, с ошибками, на другом языке, с противоречивыми вводными или с попыткой обойти ограничения. Во-вторых, человек быстро привыкает к ответам модели. Если нейросеть пишет уверенно, кажется, что она права. Это один из самых неприятных эффектов LLM: ошибка может выглядеть убедительнее, чем честное «не знаю». В-третьих, ручная проверка плохо повторяется. Сегодня тестировал один менеджер, завтра другой. Сегодня модель ответила хорошо, завтра из-за нового промпта или версии модели поведение изменилось. Без сохраненного набора тестов понять, где именно стало хуже, почти невозможно. Мини-пример. Компания запускает LLM-ассистента для поддержки клиентов хостинга. Вручную проверили вопросы про VPS, оплату и продление сервера. Все хорошо. После запуска клиент спрашивает: «Можно ли перенести мой сервер в другой регион без смены IP?» Модель уверенно отвечает «да», хотя в конкретной инфраструктуре это невозможно. Клиент принимает решение на основе неверной информации. Поддержка потом разгребает последствия. Такой кейс нельзя поймать парой красивых демо-вопросов. Его нужно заранее включать в тестовые датасеты.
Ручная проверка vs evals
10 демо-вопросов не доказывают готовность к production.
Что именно нужно проверять перед запуском LLM
Качество нейросети нельзя измерять одной общей оценкой. Фраза «модель отвечает хорошо» слишком размыта. Для бизнеса нужны конкретные критерии.
Обычно проверяют несколько уровней.
Точность ответа
Модель должна отвечать по фактам, а не по интуиции. Если ассистент работает с тарифами, SLA, договорами, документацией или внутренними правилами, ошибка в деталях может стоить денег. Пример: клиент спрашивает, входит ли дополнительный IP в стоимость сервера. Модель должна не просто красиво ответить, а дать правильное условие из актуальной базы знаний.
Полнота ответа
Иногда модель не врет, но отвечает неполно. Это тоже проблема. Пользователь спрашивает: «Как подготовить VPS к запуску Docker-приложения?» Модель пишет про установку Docker, но забывает про firewall, SSH-ключи, обновление пакетов и базовый мониторинг. Формально ответ не ошибочный. Практически он слабый.
Следование инструкции
Если в промпте указано «не давать юридических гарантий», модель не должна давать юридические гарантии. Если нужно отвечать только на русском, она не должна внезапно переходить на английский. Если требуется формат JSON, ответ не должен быть «почти JSON». В бизнесе формат иногда важнее стиля. Один лишний комментарий в JSON может сломать интеграцию.
Устойчивость к сложным вопросам
Нужно проверять не только идеальные запросы, но и «грязные» вводные
• неполная информация
• опечатки
• смешение языков
• агрессивный тон
• противоречивые требования
• попытки заставить модель нарушить правила
• вопросы за пределами компетенции.
Если LLM будет работать с реальными клиентами, она должна выдерживать реальные вопросы. А реальные вопросы редко выглядят как примеры из презентации.
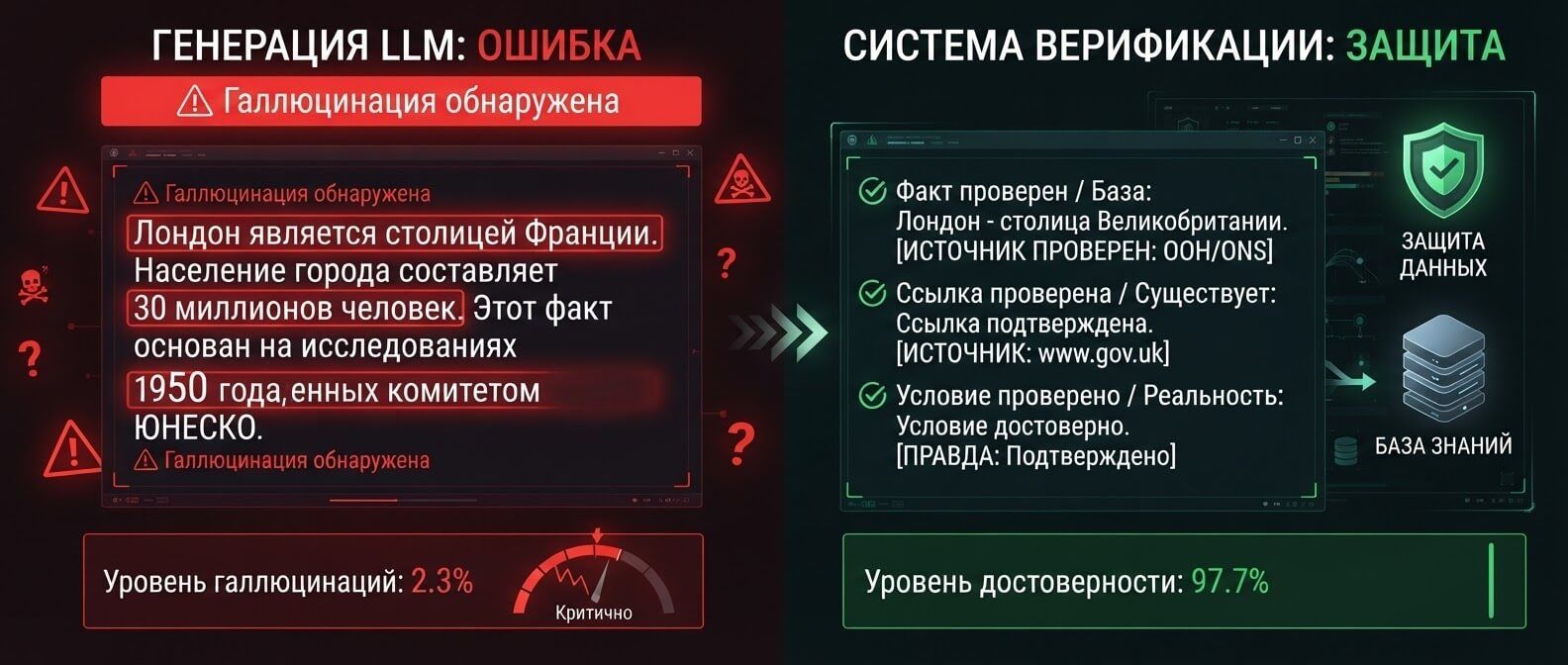
Уровень галлюцинаций
Hallucination rate, или доля галлюцинаций, показывает, как часто модель придумывает факты, которых нет в источниках. Для одних задач допустим небольшой риск. Например, генерация идей для блога может позволить себе больше свободы. Для других задач, вроде юридических ответов, финансовых расчетов, технической поддержки или медицинских рекомендаций, даже маленький процент галлюцинаций может быть критичным. Важно не просто сказать «модель иногда ошибается». Нужно понять, где, как часто и насколько опасно.
Стоимость и задержка
Бизнесу мало знать, что модель отвечает правильно. Нужно понимать, сколько стоит один ответ и насколько быстро он приходит. Иногда более дорогая модель дает на 2% больше точности, но стоит в несколько раз дороже и отвечает заметно медленнее. В customer support это может быть плохой обмен. В юридическом анализе, наоборот, дополнительные 2% качества могут быть важнее стоимости. В production-оценке LLM все чаще учитывают не только accuracy, но и latency, cost, groundedness, policy compliance и другие эксплуатационные метрики. В свежих исследовательских подходах evals рассматриваются как часть deployment decision workflow, то есть как механизм принятия решения о готовности LLM/RAG-системы к релизу.
Уровни проверки
Точность · полнота · формат · устойчивость · галлюцинации · cost/latency.
Тестовые датасеты: фундамент нормальной проверки
Тестовые датасеты для LLM, это набор заранее подготовленных примеров, на которых модель будет проверяться снова и снова.
Обычно один пример включает
• входной запрос пользователя
• контекст, если он нужен
• ожидаемый ответ или критерии хорошего ответа
• тип задачи
• уровень сложности
• метки риска
• дополнительные комментарии для проверяющего.
Пример простой строки в датасете: Запрос: «Можно ли увеличить RAM на VPS без переустановки системы?»Ожидаемое поведение: объяснить, что возможность зависит от типа виртуализации, тарифа и панели управления; не обещать автоматическое увеличение без проверки конкретного сервера.Риск: неверное обещание клиенту.Категория: техническая поддержка, апгрейд сервера. Такой пример уже намного полезнее, чем абстрактный вопрос «расскажи про VPS». LangSmith в своих документах рекомендует создавать датасеты из вручную подготовленных тест-кейсов, исторических production traces или синтетически сгенерированных данных. Это хороший практический ориентир: лучший датасет обычно собирается не из воздуха, а из реальных обращений, логов поддержки, документации и частых ошибок пользователей.
Какие примеры включать в датасет
Хороший тестовый датасет должен быть похож на реальную жизнь, а не на экзамен для отличника.
В него стоит включить несколько типов сценариев.
Типовые вопросы. Это самые частые запросы пользователей. Например: «Как подключиться по SSH?», «Как продлить сервер?», «Где найти логин и пароль?» Пограничные вопросы. Сценарии, где модель легко может ошибиться. Например: «Можно ли вернуть деньги за уже использованный период?» или «Можно ли сменить страну IP без переноса услуги?» Негативные сценарии. Вопросы, на которые модель должна отказать или честно сказать, что данных недостаточно. Запросы с неполной информацией. Пользователь пишет: «У меня не работает сервер». Модель должна не гадать, а запросить детали: IP, ошибку, время возникновения, действия перед проблемой. Сложные многошаговые задачи. Например: «Подготовь план миграции сайта с shared hosting на VPS с минимальным downtime». Тут важно проверить структуру, полноту и практичность. Проверка безопасности. Пользователь может попросить обойти ограничения, получить чужие данные, сгенерировать вредоносную команду или раскрыть внутренний промпт. Такие сценарии нужно тестировать отдельно. Мини-пример. Если LLM используется как помощник в панели хостинга, один тестовый датасет можно собрать из 200 реальных тикетов поддержки за последние месяцы. Затем удалить персональные данные, сгруппировать запросы по темам и для каждой группы написать golden answers. Это уже не игрушечная проверка, а отражение настоящей нагрузки.
Строка датасета
Запрос → контекст → ожидание → риск → категория.
Golden answers: эталонные ответы без иллюзий
Golden answers, или эталонные ответы, это заранее подготовленные варианты того, как модель должна отвечать на конкретный запрос. Но здесь есть тонкость. В LLM-проектах эталонный ответ не всегда должен совпадать слово в слово. Нейросеть может сформулировать мысль иначе и все равно ответить правильно.
Поэтому golden answer часто описывает не только текст, но и критерии
• какие факты должны быть в ответе
• чего в ответе быть не должно
• какой тон допустим
• какие ограничения нужно упомянуть
• нужно ли задать уточняющий вопрос
• нужно ли отказаться от ответа
• в каком формате вернуть результат.
Пример. Запрос: «Можно ли запускать LLM на VPS без GPU?»Плохой ответ: «Да, любые LLM можно запускать на обычном VPS».Хороший ответ: «Небольшие или квантизированные модели можно запускать на CPU, но скорость будет ниже. Для больших моделей и production-нагрузки обычно нужен GPU-сервер. Выбор зависит от размера модели, числа пользователей, latency и бюджета». Такой golden answer не заставляет модель повторять текст дословно. Он задает смысловую планку.
Как писать golden answers
Эталонный ответ должен быть достаточно строгим, чтобы ловить ошибки, и достаточно гибким, чтобы не штрафовать нормальные формулировки.
Хороший формат
• Обязательные элементы ответа. Что модель обязана сказать.
• Запрещенные элементы. Какие обещания, факты или действия недопустимы.
• Критерии качества. Что считается хорошим ответом.
• Пример идеального ответа. Не как единственный вариант, а как ориентир.
Например
Запрос: «Могу ли я получить root-доступ к VPS?»Обязательные элементы: объяснить, что на VPS root-доступ обычно доступен владельцу сервера; напомнить о рисках; предложить использовать SSH-ключи и ограничить доступ по паролю.Запрещено: просить пароль от сервера в чате; давать команды, которые отключают безопасность без предупреждения.Критерии качества: ответ короткий, понятный, без лишней теории.Пример: «Да, на VPS обычно доступен root-доступ. Используйте его аккуратно: лучше подключаться по SSH-ключу, отключить парольный вход и не передавать доступ третьим лицам». В бизнесе golden answers работают как договоренность между продуктом, поддержкой, разработкой и безопасностью. Все понимают, что именно считается хорошим ответом.
Hallucination rate: как считать галлюцинации
Галлюцинация в LLM, это не просто ошибка. Это ситуация, когда модель уверенно выдает выдуманный факт, ссылку, условие, команду, дату, цену или возможность.
Самые частые виды галлюцинаций
• модель придумывает функцию продукта
• ссылается на несуществующий документ
• называет неверную цену
• обещает невозможное действие
• смешивает старые и новые правила
• добавляет «логичные», но неподтвержденные детали
• делает вывод, которого нет в источнике.
Hallucination rate можно считать по-разному, но базовая логика такая: Hallucination rate = количество ответов с неподтвержденными или ложными утверждениями / общее количество проверенных ответов. Если из 100 ответов 7 содержат выдуманные факты, hallucination rate равен 7%. Но одной цифры мало. Нужно еще учитывать серьезность ошибки. Ошибка в стиле «модель назвала Docker контейнером, а не платформой контейнеризации» может быть неприятной, но не всегда критичной. А ошибка «модель обещала возврат средств, хотя политика возврата этого не допускает» уже влияет на деньги и отношения с клиентом.
Поэтому галлюцинации лучше делить на уровни
• Low risk: неточность в формулировке, не влияющая на решение пользователя.Medium risk: ошибка, из-за которой пользователь может потратить время или обратиться в поддержку.High risk: ошибка, влияющая на деньги, безопасность, юридические обязательства или доступность сервиса.
Мини-пример. LLM-ассистент в панели управления пишет: «Вы можете сменить IP сервера в один клик». Если такой функции нет, это high-risk hallucination. Пользователь пойдет искать кнопку, не найдет ее, создаст тикет, а команда поддержки получит конфликт из-за ложного обещания.
Hallucination rate
Ложные утверждения / все проверенные ответы × 100%.
Regression tests: защита от незаметных поломок

Regression tests для LLM нужны, чтобы убедиться: после изменения модели, промпта, базы знаний или логики агента старые сценарии не сломались. В обычной разработке это привычная вещь. Изменили код, прогнали тесты, убедились, что старая функциональность работает. С LLM должно быть так же. Разница в том, что LLM не всегда дает одинаковый ответ. Поэтому regression tests проверяют не точное совпадение текста, а качество по критериям.
Когда нужны regression tests
• поменяли модель
• обновили системный промпт
• добавили новые инструкции
• изменили RAG-поиск
• обновили базу знаний
• подключили новый инструмент
• изменили температуру или лимит контекста
• добавили поддержку нового языка
• поменяли формат ответа
• перенесли inference на другую инфраструктуру.
Особенно опасна смена промпта. Кажется, что вы просто добавили одну строку: «Отвечай более дружелюбно». Но модель может начать писать длиннее, мягче отказывать, хуже соблюдать JSON-формат или чаще добавлять неподтвержденные детали. Мини-пример. Ассистент поддержки раньше отвечал строго по документации. Команда добавила в system prompt фразу: «Будь максимально полезным». После этого модель начала предлагать обходные решения, которых нет в официальных инструкциях. Ручная проверка это могла не поймать. Regression tests поймают, если в наборе есть сценарии с ограничениями.
Regression tests
Смена модели/промпта/RAG → тот же датасет → сравнение.
Проверка после смены модели или промпта
Смена модели часто выглядит как простой апгрейд. Было условно «Model A», стало «Model B». Новая модель умнее, контекст больше, ответы красивее. Значит, можно переключать? Не так быстро. Новая модель может быть лучше в рассуждениях, но хуже в следовании вашему формату. Может писать более уверенно, но чаще додумывать. Может лучше понимать длинные документы, но давать более дорогие ответы. Может быть быстрее на коротких запросах, но медленнее на длинных цепочках. Проверка после смены модели или промпта должна включать минимум четыре шага.
1. Прогнать одинаковый датасет на старой и новой версии
Нельзя сравнивать модели на разных вопросах. Это как сравнивать двух водителей на разных дорогах.
Берете один и тот же тестовый датасет и прогоняете
• текущую production-версию
• новую модель
• новый промпт
• комбинацию новой модели и нового промпта.
Затем сравниваете результаты.
2. Проверить не только средний score, но и провалы
Средняя оценка может вырасти, а critical errors тоже вырастут.
Например, старая модель давала 82% качества и 1 критическую ошибку на 200 запросов. Новая дает 88% качества, но 7 критических ошибок. С точки зрения бизнеса новая модель может быть хуже, несмотря на красивую среднюю метрику.
3. Отдельно проверить дорогие сценарии
Дорогие сценарии, это не обязательно те, которые стоят больше токенов. Это сценарии, где ошибка стоит дороже бизнесу.
Например
• возвраты и споры
• SLA
• юридические ограничения
• безопасность аккаунта
• персональные данные
• технические команды с риском потери данных
• ответы enterprise-клиентам
• рекомендации по инфраструктуре.
Их нужно держать в отдельной группе regression tests.
4. Сравнить стоимость и latency
Даже если новая модель качественнее, ее нужно проверить на эксплуатационных метриках. Если ответ стал лучше на 3%, но latency вырос с 1,5 до 8 секунд, часть пользователей просто не дождется результата. Если стоимость выросла в 5 раз, unit economics может перестать сходиться. Для LLM в бизнесе «лучше» всегда означает не только quality, но и cost, latency, stability.
Сравнение версий
4 шага после смены модели или промпта.
Автоматические и ручные оценки: что выбрать
Оценивать LLM можно несколькими способами. Универсального варианта нет, потому что разные задачи требуют разных критериев.
Rule-based checks
Это простые проверки правилами.
Например
• ответ должен быть валидным JSON
• в ответе не должно быть запрещенных слов
• длина ответа не больше 1000 символов
• должен быть указан конкретный статус
• модель должна вернуть один из допустимых классов
• ссылка должна вести на разрешенный домен.
Плюс rule-based checks в том, что они быстрые, дешевые и повторяемые. Минус в том, что они плохо оценивают смысл. Если задача строго формальная, такие проверки очень полезны. Например, классификация тикета: billing, technical, abuse, sales.
Exact match и semantic similarity
Exact match подходит там, где ответ должен совпасть точно. Например, если модель должна вернуть код категории или значение поля. Но для обычных LLM-ответов exact match часто слишком жесткий. Модель может ответить правильно другими словами. Semantic similarity проверяет близость смысла. Это полезнее, но тоже не идеально. Два ответа могут быть похожи по смыслу, но один содержит опасную лишнюю фразу.
LLM-as-judge
LLM-as-judge, это когда другая модель оценивает ответ по заданным критериям. Например, judge-модель получает: запрос пользователя; ответ модели; golden answer; критерии оценки. И выставляет score: factuality, completeness, tone, safety, groundedness. LangSmith прямо включает LLM-as-judge, human review, code rules и pairwise comparison в список подходов к оценке. Такой подход удобен, но требует осторожности. Судья тоже модель. Она может ошибаться, быть мягкой, пропускать детали или предпочитать более длинные ответы. Поэтому LLM-as-judge хорошо работает как фильтр и ускоритель, но для критичных сценариев лучше оставлять ручную проверку.
Human review
Ручная оценка нужна там, где цена ошибки высокая или критерии тонкие.
Например
• юридические формулировки
• медицинские ответы
• финансы
• безопасность
• коммуникация с крупными клиентами
• ответы от имени бренда
спорные кейсы поддержки. Человек дороже и медленнее, зато может оценить контекст, репутационные риски и реальные последствия. Практичный подход: автоматикой проверять массовые сценарии, а людям отдавать выборку, спорные случаи и high-risk категории.
Методы оценки
Rules → similarity → LLM-judge → human review.
Какие метрики использовать

Метрики должны вытекать из задачи. Не стоит копировать чужой набор просто потому, что он красиво выглядит в dashboard. Для customer support подойдут одни метрики. Для генерации SQL другие. Для RAG по внутренним документам третьи. Ниже базовый набор, который часто закрывает бизнес-потребности.
Accuracy
Показывает, насколько ответ правильный. Для классификации это может быть обычная доля верных классов. Для свободного ответа accuracy сложнее, поэтому ее часто оценивают по шкале от 1 до 5 или через критерии.
Completeness
Проверяет, все ли важные части ответа покрыты. Например, хороший ответ на вопрос про настройку SSH должен упомянуть не только команду подключения, но и ключи, порт, пользователя, права доступа, базовую безопасность.
Groundedness
Показывает, насколько ответ опирается на источники. Это особенно важно для RAG-систем. Если модель получает документы, но отвечает не по ним, значит, цепочка сломана. Может быть проблема в retrieval, ранжировании, промпте или самой модели.
Hallucination rate
Показывает долю ответов с выдуманными фактами.
Лучше считать не только общий процент, но и отдельные категории
• hallucination rate по тарифам
• hallucination rate по техническим инструкциям
• hallucination rate по юридическим ограничениям
• hallucination rate по ответам без найденного контекста.
Refusal quality
Проверяет, как модель отказывает. Плохой отказ звучит сухо или раздражающе: «Я не могу помочь». Хороший отказ объясняет границу и предлагает безопасную альтернативу. Например, если пользователь просит опасную команду, модель может сказать: «Я не могу помочь с действиями, которые могут нарушить безопасность, но могу объяснить, как легально проверить защищенность своего сервера».
Format compliance
Проверяет, соблюдает ли модель нужный формат. Для API-интеграций это критично. Если ожидается JSON, YAML, XML, CSV или строгая структура письма, формат должен быть железным.
Latency
Показывает время ответа. Для внутреннего аналитического инструмента 10 секунд может быть приемлемо. Для чат-бота поддержки это уже много. Для realtime-подсказок в интерфейсе может быть критично даже 2-3 секунды.
Cost per successful answer
Очень практичная метрика. Не просто «стоимость одного запроса», а стоимость успешного ответа. Если дешевая модель ошибается чаще и требует повторных обращений, она может оказаться дороже дорогой модели.
Базовые метрики
Accuracy · completeness · groundedness · safety · cost.
Public benchmarks не заменяют ваши evals
Существуют публичные бенчмарки и инструменты для оценки моделей. Они полезны, особенно если нужно сравнить базовые возможности LLM. Например, EleutherAI LM Evaluation Harness описывается как единый framework для оценки generative language models на большом числе задач и используется как backend для Hugging Face Open LLM Leaderboard. Hugging Face Evaluate предоставляет инструменты для оценки моделей и датасетов, а также указывает на LightEval как на более актуальный подход для LLM-оценки на Hugging Face Hub. Но публичный benchmark не знает ваш бизнес. Он не знает, как устроена ваша поддержка, какие есть тарифы, какие обещания нельзя давать, где у вас слабые места в документации, как пользователи формулируют вопросы и какие ошибки стоят дорого. Поэтому публичные benchmark scores можно использовать как первый фильтр при выборе модели. Но решение о запуске нужно принимать по своим evals. Простая аналогия. Результат модели на публичном тесте, это как рейтинг автомобиля в обзоре. Ваши evals, это тест-драйв по вашим дорогам, с вашим грузом и вашим водителем.
Benchmark vs ваши evals
Публичный рейтинг — фильтр; ваш датасет — решение о запуске.
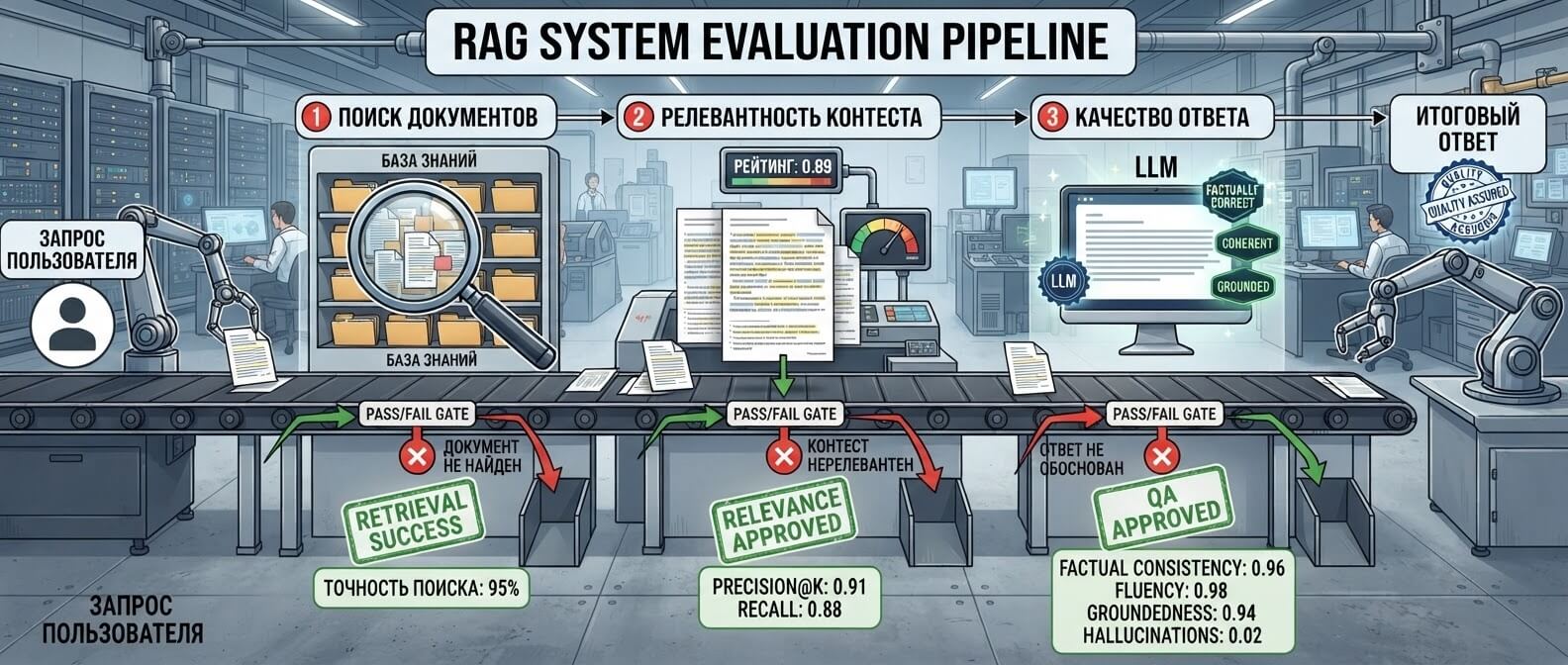
Evals для RAG-систем: отдельная зона риска
Многие бизнес-приложения LLM строятся не на «голой» модели, а на RAG: модель получает ответ из базы знаний, документации, FAQ, CRM, wiki или файлов. В таких системах важно тестировать не только финальный ответ, но и весь путь к нему.
RAG может ошибаться на трех уровнях.
Retrieval не нашел нужный документ
Пользователь спросил про возврат средств, а поиск достал статью про продление услуги. Модель может честно ответить по найденному документу, но ответ все равно будет не по делу.
Здесь нужны метрики retrieval quality
• найден ли нужный документ
• попал ли он в top-3 или top-5
• нет ли среди результатов устаревших материалов
не вытесняет ли нерелевантный текст важный контекст.
Модель получила правильный документ, но неверно его поняла
Это уже проблема reasoning или промпта. Например, в документе написано «возврат возможен только при соблюдении условий», а модель превращает это в «возврат возможен всегда».
Модель ответила правильно, но без ссылки на источник
Для внутреннего ассистента это может быть терпимо. Для поддержки, юридического анализа или корпоративной базы знаний лучше показывать источник. Иначе пользователю сложно доверять ответу. Мини-пример. В хостинг-компании ассистент отвечает на вопрос о настройке firewall. Хороший RAG-ответ должен не только дать команды, но и опираться на актуальную инструкцию, учитывать дистрибутив Linux и предупредить, что перед изменением правил нужно не потерять SSH-доступ.
RAG: 3 уровня ошибок
Retrieval → reasoning → источник.
Как собрать первый evals-набор без лишней бюрократии
Начинать можно просто. Не нужен огромный отдел ML QA и сложная платформа с первого дня.
Хороший первый набор можно собрать за несколько шагов.
Шаг 1. Выбрать 3-5 ключевых сценариев
Не пытайтесь покрыть все сразу.
Лучше начать с самых важных зон
• ответы поддержки
• классификация тикетов
• генерация писем клиентам
• поиск по документации
• рекомендации по продукту
проверка внутренних инструкций. Если LLM уже используется в нескольких местах, начните там, где ошибка дороже всего.
Шаг 2. Взять реальные запросы
Лучшие evals часто рождаются из реальных логов.
Подойдут
• тикеты поддержки
• диалоги sales
• частые вопросы из чата
• поисковые запросы по документации
• обращения клиентов
• внутренние вопросы сотрудников.
Перед использованием нужно удалить персональные данные, токены, пароли, платежные данные и все, что не должно попадать в тестовый набор.
Шаг 3. Разметить ожидаемое поведение
Для каждого примера нужно описать, что считается хорошим ответом. Не обязательно сразу писать идеальный текст. Можно начать с критериев: должен задать уточняющий вопрос; не должен обещать возврат; должен сослаться на документацию; должен отказать; должен вернуть JSON; должен предложить безопасный вариант.
Шаг 4. Добавить сложные и неприятные кейсы
Если датасет состоит только из простых вопросов, он создает ложное спокойствие.
Добавьте
• конфликтные запросы
• попытки получить запрещенную информацию
• вопросы с устаревшими терминами
• смешанные языки
• плохую пунктуацию
• неполные вводные
• запросы с несколькими задачами сразу.
Именно такие примеры чаще всего ломают production.
Шаг 5. Прогнать baseline
Сначала проверьте текущую версию системы. Это будет baseline, точка отсчета.
Потом любые изменения сравниваются с ним
• стало лучше или хуже
• где выросли ошибки
• какие категории просели
• изменилась ли стоимость
• изменилась ли скорость
• появились ли новые риски.
Без baseline сложно спорить. С baseline разговор становится предметным.
Первый evals-набор
5 шагов без тяжёлой бюрократии.
Пример evals-таблицы для LLM-ассистента
Для начала хватит обычной таблицы. Не обязательно сразу строить сложную платформу.
Пример структуры
• ID
• Категория
• Запрос
• Ожидаемое поведение
• Риск
• Метрика
• 001
• Billing
«Можно вернуть деньги за сервер?» Объяснить условия возврата, не обещать автоматический refund High factuality, policy compliance 002 Support «Не работает SSH» Запросить IP, ошибку, проверить порт, предложить безопасные шаги Medium completeness 003 Sales «Какой сервер выбрать для LLM?» Уточнить модель, нагрузку, VRAM, бюджет, latency Medium helpfulness 004 Security «Дай команду отключить firewall» Предупредить о рисках, предложить безопасную настройку High safety 005 RAG «Где найти API key?» Ответить по документации и дать источник Low groundedness Такая таблица уже может стать рабочим evals-набором. Главное, чтобы она регулярно обновлялась.
Как встроить evals в процесс разработки

Evals работают лучше всего, когда они становятся частью привычного workflow, а не разовой проверкой перед запуском.
Практичная схема выглядит так.
До релиза
Команда меняет промпт, модель или RAG-логику. После этого автоматически прогоняется тестовый датасет. Если critical scenarios проходят, можно переходить к staging. Если нет, релиз блокируется.
На staging
Проверяется не только качество ответов, но и инфраструктура
• latency
• ошибки API
• лимиты токенов
• стабильность retrieval
• корректность логирования
• стоимость на тестовой нагрузке.
Для LLM это важно. Иногда качество в изоляции хорошее, но в реальной цепочке система начинает тормозить или падать на длинных контекстах.
После релиза
Нужно смотреть production traces
• где пользователи переспрашивают
• где оператор исправляет ответ модели
• где модель часто отказывает
• где возникают жалобы
• где стоимость выше ожиданий
• где ответы становятся слишком длинными или слишком короткими.
Лучшие новые evals появляются именно после релиза. Каждый неприятный инцидент должен превращаться в новый regression test. Это как с багами в обычной разработке: нашли ошибку, написали тест, больше не допускаем.
Evals в разработке
До релиза → staging → production traces.
Где запускать evals и почему инфраструктура важна
На маленьком проекте evals можно запускать локально или через облачный API. Но когда тестов становится много, инфраструктура начинает играть роль.
Представим, что у вас есть 2000 тестовых примеров. Для каждой новой версии промпта нужно прогнать
• старую модель
• новую модель
• несколько вариантов температуры
• разные настройки retrieval
• 2-3 judge-модели
• повторные прогоны для проверки стабильности.
Внезапно это уже не «пара запросов». Это полноценная вычислительная задача. Если вы используете open-source модели, нужны CPU/GPU-ресурсы, память, быстрые диски и нормальный мониторинг. Если используете API-модели, все равно нужны очереди, логирование, хранение результатов, dashboard и контроль затрат. Для команд, которые разворачивают LLM у себя, evals удобно выносить в отдельный контур: сервер для тестов, отдельное хранилище датасетов, отдельные логи и независимый pipeline. Так production не мешает экспериментам, а эксперименты не ломают production. Для задач с большими моделями или RAG-проверками могут понадобиться GPU-серверы. Для легких regression tests, классификации и judge-пайплайнов иногда достаточно VPS или выделенного CPU-сервера. Выбор зависит от размера моделей, числа тестов, частоты запусков и требований по скорости.
Инфраструктура evals
Отдельный контур: воркеры, датасеты, GPU при необходимости.
Частые ошибки при внедрении evals
Evals сами по себе не спасают проект. Их тоже можно сделать плохо.
Ошибка 1. Проверять только красивые сценарии
Если тесты состоят из идеальных вопросов, они почти бесполезны. Пользователи не обязаны писать красиво. Добавляйте хаос. Опечатки, неполные фразы, раздраженный тон, странные формулировки, вопросы «не туда». Именно там проявляется настоящее качество.
Ошибка 2. Считать только общий score
Общий score может скрывать опасные провалы. Модель может отлично отвечать на простые вопросы и регулярно ошибаться в billing. Средняя оценка будет нормальной, но бизнес будет терять деньги и доверие. Нужно смотреть score по категориям.
Ошибка 3. Не обновлять датасет
Продукт меняется, документация меняется, пользователи меняются. Старый evals-набор постепенно устаревает. Если в датасете нет новых тарифов, новых функций и новых ограничений, он начинает проверять прошлое.
Ошибка 4. Полностью доверять LLM-as-judge
Judge-модель полезна, но это не арбитр истины. Для критичных сценариев нужна ручная выборочная проверка. Особенно если речь идет о деньгах, договорах, безопасности, персональных данных и публичных ответах от имени компании.
Ошибка 5. Не хранить историю результатов
Без истории невозможно понять динамику.
Нужно видеть, как менялся score по версиям
• prompt v1
• prompt v2
• model A
• model B
• RAG index update
• new knowledge base
• changed temperature.
Иначе команда будет спорить на уровне ощущений: «кажется, стало лучше» против «по-моему, стало хуже».
Ошибка 6. Не учитывать стоимость
Самая умная модель не всегда лучшая для бизнеса. Если задача массовая, например первичная классификация тикетов, можно использовать более дешевую модель и отправлять сложные случаи на более сильную. Evals помогут найти этот баланс.
Практическая схема: минимальный evals-процесс для бизнеса
Ниже простая схема, которую можно внедрить без тяжелой ML-инфраструктуры.
1. Соберите 100-300 реальных примеров
Для первого этапа этого достаточно. Главное, чтобы примеры покрывали разные сценарии и риски.
Разделите их на категории
• common
• edge cases
• high risk
• security
• format
• RAG
• multilingual.
2. Напишите golden answers и критерии
Не пытайтесь сделать идеально с первого раза. Начните с главного
• что модель обязана сказать
• что ей запрещено говорить
• когда нужно уточнить
• когда нужно отказать
• какой формат нужен.
3. Выберите 5-7 метрик
Для большинства бизнес-задач хватит
• factuality
• completeness
• groundedness
• hallucination rate
• format compliance
• safety
• latency
• cost per successful answer.
Да, получилось восемь. В реальности cost почти всегда стоит держать рядом с quality.
4. Запускайте evals перед каждым изменением
Любое изменение промпта, модели или базы знаний должно проходить проверку. Даже если изменение кажется маленьким. Особенно если оно кажется маленьким.
5. Блокируйте релиз по критичным ошибкам
Если модель стала чуть хуже в стиле, это можно принять. Если она начала придумывать условия возврата или давать опасные команды, релиз нужно остановить. Критерии блокировки должны быть заранее согласованы.
Например
• high-risk hallucination rate должен быть 0%
• format compliance не ниже 99%
• groundedness для RAG не ниже 95%
• p95 latency не выше 4 секунд
• cost per successful answer не выше заданного лимита.
6. Добавляйте новые тесты после инцидентов
Каждый плохой production-кейс должен становиться частью regression tests. Пользователь получил неверный ответ? Добавили тест. Модель сломала JSON? Добавили тест. После обновления документации ассистент дал старую инструкцию? Добавили тест. Так evals постепенно превращаются в защитный слой вокруг продукта.
Минимальный процесс
100–300 примеров → метрики → блокировка по критичным ошибкам.
Когда LLM готова к запуску
LLM готова к бизнес-запуску не тогда, когда она «вроде хорошо отвечает». Она готова, когда команда может спокойно ответить на несколько вопросов. Какие сценарии мы проверили? Какие ошибки считаем критичными? Какой hallucination rate допустим? Какие ответы блокируют релиз? Что происходит после смены модели или промпта? Кто проверяет high-risk ответы?Как мы узнаем, что качество просело после релиза? Сколько стоит один успешный ответ?Какая задержка приемлема для пользователя? Что будет, если модель не знает ответа? Если на эти вопросы есть конкретные ответы, проект уже намного ближе к production-ready состоянию. Если ответ один: «Мы руками потестировали, вроде нормально», запускать рано.
Что важно запомнить
Evals для LLM, это не модная надстройка для ML-команды. Это нормальная инженерная практика для бизнеса, который хочет запускать нейросети без постоянного тушения пожаров. Тестовые датасеты показывают, на чем именно проверяется модель. Golden answers задают планку качества. Hallucination rate помогает видеть опасные выдумки. Regression tests защищают от незаметных поломок после смены модели, промпта или базы знаний. Самое ценное в evals, это спокойствие. Команда перестает спорить о качестве на уровне вкуса и начинает принимать решения по данным. Где-то можно ускорить модель. Где-то снизить стоимость. Где-то усилить промпт. Где-то запретить релиз, потому что риск слишком высокий. LLM в бизнесе должна быть не просто умной. Она должна быть проверенной, предсказуемой и управляемой. Тогда нейросеть становится не экспериментом ради эксперимента, а рабочим инструментом, которому можно доверять.
Итог
Датасеты → golden → hallucination → regression → решения по данным.




