



















Оглавление
- Почему API abuse - это не всегда атака в привычном смысле
- Что OWASP называет unrestricted resource consumption
- Почему одних rate limits недостаточно
- Дорогой запрос: как понять, что именно нужно ограничивать
- Rate limits: базовый слой защиты API
- Quotas: когда нужно ограничивать не скорость, а бюджет
- Weighted limits: не все запросы весят одинаково
- Защита CPU: таймауты, сложность операций и очереди
- Защита RAM: размер тела запроса, пагинация и потоковая обработка
- Защита bandwidth: трафик тоже стоит денег
- AI API и LLM: новая категория дорогих запросов
- GPU-ресурсы: защищаем не только сервер, но и очередь
- Внешние платные API: скрытая дыра в бюджете
- Параллельность: тихий убийца стабильности
- Pagination и filtering: защита начинается с дизайна API
- 429 Too Many Requests: ошибка, которая должна помогать
- Retry policy: как клиенты случайно устраивают DDoS
- Idempotency: защита от дублей и случайных расходов
- Кэширование: самый приятный запрос - тот, который не нужно выполнять
- Изоляция клиентов: один tenant не должен съедать всех
- Серверный уровень: где ставить ограничения
- Мониторинг: нельзя защитить то, что не измеряется
- Alerting: когда лимиты должны звать человека
- Как внедрять API abuse protection без боли
- Что важно документировать для разработчиков
- Частые ошибки при защите API от дорогих запросов
- API abuse protection для VPS и выделенных серверов
- Небольшой чек-лист для команды
- Главная мысль: защищайте не только вход, но и стоимость работы
API редко ломают «красиво». Чаще всё выглядит почти буднично: обычные запросы, корректные параметры, авторизованный пользователь, никаких подозрительных payload в духе классических атак. Но через час CPU уходит в потолок, база начинает задыхаться, очередь задач растёт, счёт за трафик неприятно округляется вверх, а GPU-сервер под AI API занят запросами, которые почти ничего не приносят бизнесу. Именно здесь начинается API abuse protection - защита не только от взлома, но и от перерасхода ресурсов. Не классический WAF, который ищет SQL-инъекции и XSS, а более практичный слой контроля: сколько один клиент, токен, IP, endpoint или workspace может потреблять CPU, RAM, bandwidth, запросов к базе, LLM-токенов и GPU-времени. Для SaaS, AI API и high-load-проектов это уже не «дополнительная настройка на потом». Это часть экономики сервиса. Если API умеет выполнять дорогие операции, значит, кто-то рано или поздно попробует выполнять их слишком часто.
Готовы перейти на современную серверную инфраструктуру?
В King Servers мы предлагаем серверы как на AMD EPYC, так и на Intel Xeon, с гибкими конфигурациями под любые задачи — от виртуализации и веб-хостинга до S3-хранилищ и кластеров хранения данных.
- S3-совместимое хранилище для резервных копий
- Панель управления, API, масштабируемость
- Поддержку 24/7 и помощь в выборе конфигурации
Результат регистрации
...
Создайте аккаунт
Быстрая регистрация для доступа к инфраструктуре
Почему API abuse - это не всегда атака в привычном смысле
Когда говорят о защите API, многие сразу представляют WAF, сигнатуры, блокировку подозрительных IP и борьбу с ботами. Всё это важно, но проблема шире. API может страдать не только от вредоносного запроса, но и от слишком дорогого легального запроса.
Например
• пользователь выгружает отчёт за 5 лет вместо 7 дней
• клиентский скрипт случайно уходит в бесконечный цикл и вызывает endpoint 300 раз в минуту
• мобильное приложение при плохом интернете агрессивно повторяет запросы
• партнёрская интеграция запускает тяжёлый поиск без фильтров
• AI API получает огромный контекст и просит сгенерировать длинный ответ
• endpoint обработки изображений массово загружает файлы большого размера.
Формально всё может быть разрешено. Пользователь авторизован, токен действительный, endpoint публичный, параметры проходят валидацию. Но серверу от этого не легче. Если провести бытовую аналогию, WAF проверяет, не пытается ли посетитель пронести в здание запрещённые предметы. А API abuse protection следит, чтобы один посетитель не занял весь лифт, все переговорки, весь кофе и половину электричества.
WAF vs API abuse protection
WAF ищет атаки; abuse protection — перерасход легальных запросов.
Что OWASP называет unrestricted resource consumption

В OWASP API Security Top 10 эта проблема выделена как API4:2023 Unrestricted Resource Consumption. Суть проста: API-запросы потребляют ресурсы, а если лимиты не заданы или заданы слишком мягко, эти ресурсы можно исчерпать. Речь не только о количестве HTTP-запросов в секунду. Запросы бывают разными. Один лёгкий GET к справочнику почти ничего не стоит. А один POST на генерацию PDF-отчёта, транскодирование видео, сложный SQL-запрос или LLM-инференс может стоить дороже тысячи простых запросов. OWASP в этом контексте говорит о bandwidth, CPU, memory, storage, времени выполнения, размере загрузки, количестве операций внутри одного запроса и других ограничениях. То есть безопасность API напрямую пересекается с инфраструктурной экономикой. Это важный сдвиг в мышлении. API защищают не только от кражи данных, но и от превращения сервера в бесплатный вычислительный автомат для чужих экспериментов.
OWASP API4:2023
Unrestricted Resource Consumption — лимиты на bandwidth, CPU, memory, время, размер.
Безопасность API = инфраструктурная экономика.
Почему одних rate limits недостаточно
Rate limits - первый инструмент, который обычно приходит в голову. Например: не больше 100 запросов в минуту на пользователя. Звучит разумно. Но есть нюанс. Если все запросы примерно одинаковые по стоимости, простой rate limit работает неплохо. Так часто бывает с небольшими CRUD API: создать запись, получить список, обновить поле, удалить объект. Но в реальных SaaS и high-load-системах запросы сильно отличаются: /profile - дешёвый; /search?query=... - средний; /export?from=2020-01-01 - дорогой; /ai/generate - очень дорогой; /video/process - непредсказуемо дорогой. Если всем endpoint дать одинаковый лимит, получится странная картина. Пользователь может сделать 100 дешёвых запросов и почти не нагрузить систему. А может сделать 100 дорогих запросов и положить воркер, базу, хранилище или GPU. Поэтому защита API от дорогих запросов должна учитывать не только количество, но и стоимость операции. Именно здесь появляются quotas, weighted rate limits, лимиты на размер данных, ограничения параллельности, очереди, таймауты и бюджетирование ресурсов.
Стоимость endpoint
Одинаковый rate limit для /profile и /export не работает.
Дорогой запрос: как понять, что именно нужно ограничивать

Дорогой запрос - это не обязательно большой запрос. Иногда он выглядит скромно: несколько параметров, аккуратный JSON, короткий URL. Дороговизна проявляется внутри системы. Например, endpoint поиска может принять маленький запрос: GET /api/orders/search?q=a На входе всё невинно. Но если поиск идёт по миллионам строк, без нормальных индексов, с wildcard-фильтрами и сортировкой по вычисляемому полю, сервер получает маленький камень, который запускает большую лавину. То же самое с AI API. Пользователь отправляет один запрос, но внутри запускается токенизация, выбор модели, загрузка контекста, обращение к векторной базе, инференс на GPU и генерация длинного ответа. Для клиента это один HTTP call. Для инфраструктуры - полноценная рабочая смена.
Основные признаки дорогих API-запросов
Стоит отдельно проверить endpoint, если он
• делает сложные SQL-запросы или агрегации
• запускает export, import, report или backup
• работает с файлами, изображениями, аудио или видео
• вызывает внешние платные API
• отправляет SMS, email, push или webhook
• использует LLM, embeddings, OCR, speech-to-text или GPU-вычисления
• возвращает большие объёмы данных
• допускает глубокую пагинацию
• позволяет пользователю задавать слишком широкие фильтры
• выполняет цепочку внутренних операций в одном запросе.
Хороший вопрос для команды: «Что будет, если один клиент вызовет этот endpoint 1000 раз подряд?» Если ответ начинается с нервного молчания, endpoint точно требует лимитов.
Rate limits: базовый слой защиты API
Rate limits ограничивают частоту запросов. Это фундамент API abuse protection, но его нужно настраивать аккуратно. Самый простой вариант - лимит по IP. Например, не больше 60 запросов в минуту с одного адреса. Такой подход помогает против грубого флуда, но быстро упирается в ограничения. Во-первых, за одним IP может сидеть целый офис, NAT, мобильный оператор или корпоративный шлюз. Во-вторых, злоумышленник может распределить запросы по множеству IP. В-третьих, IP ничего не говорит о бизнес-контексте: кто именно делает запрос, на каком тарифе, к какому endpoint, с каким токеном. Поэтому зрелая схема rate limiting обычно учитывает несколько измерений.
По чему лимитировать запросы
Практичный набор выглядит так
• по IP - чтобы отсеивать грубый сетевой шум
• по API key или access token - чтобы контролировать конкретную интеграцию
• по user ID - чтобы ограничить пользователя в продукте
• по organization или tenant ID - важно для B2B SaaS
• по endpoint - потому что /status и /export не равны
• по HTTP method - POST и DELETE обычно требуют более осторожного контроля
• по географии или ASN - если есть выраженный риск abuse из определённых сетей
• по плану подписки - free, trial, business, enterprise.
Мини-пример: для публичного endpoint можно поставить 300 запросов в минуту на IP, но для endpoint генерации отчёта - 5 запросов в минуту на workspace и не больше 1 активного отчёта одновременно. Такой лимит уже не просто «режет трафик». Он защищает конкретный ресурс.
Алгоритмы rate limiting: token bucket, leaky bucket и sliding window

В реализации rate limits часто используют несколько классических алгоритмов. Token bucket хорошо подходит для API, где допустимы короткие всплески. У клиента есть «ведро» токенов. Каждый запрос тратит токен, токены постепенно пополняются. Если токены закончились, клиент ждёт или получает 429 Too Many Requests. Это удобно для реального продукта. Пользователь может сделать несколько запросов подряд, и система не будет раздражать его слишком жёстким контролем. Leaky bucket работает строже. Запросы как будто попадают в ведро с маленьким отверстием и выходят равномерно. Всплески сглаживаются, лишнее отбрасывается или ждёт в очереди. Sliding window помогает точнее считать запросы за последние N секунд или минут. Такой подход часто полезнее простого фиксированного окна, где клиент может сделать лимит в конце одной минуты и ещё лимит в начале следующей. На практике редко нужен один «идеальный» алгоритм для всего API. Для дешёвых endpoint подойдёт один подход, для дорогих операций - другой. Главное, чтобы лимит соответствовал цене запроса.
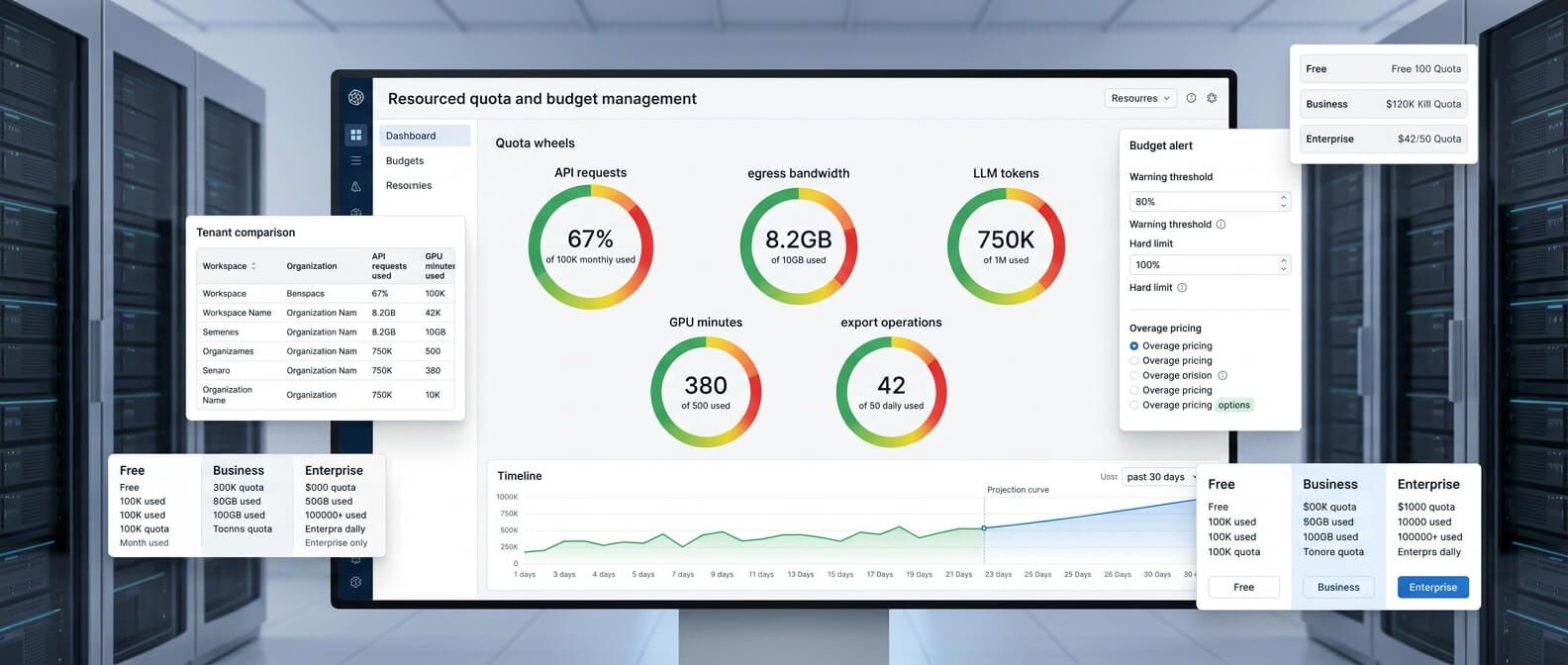
Quotas: когда нужно ограничивать не скорость, а бюджет
Rate limit отвечает на вопрос: «Как часто можно обращаться к API?» Quota отвечает на другой вопрос: «Сколько всего ресурсов можно потребить за период?» Для SaaS это особенно важно. Клиент может не нарушать минутные лимиты, но стабильно выжигать ресурсы весь день. Например, делать по одному тяжёлому запросу каждые 10 секунд. Формально всё спокойно. По счёту за инфраструктуру - уже нет.
Quotas помогают задавать дневные, недельные или месячные лимиты
• 100 000 API-запросов в месяц
• 50 export-операций в день
• 10 GB исходящего трафика на workspace
• 1 000 000 LLM-токенов в месяц
• 500 минут GPU-инференса
• 100 GB обработанных файлов
• 10 параллельных задач на организацию.
Это уже ближе к финансовому контролю. Команда не просто защищает сервер, а управляет себестоимостью продукта.
Soft quota и hard quota
Жёсткая quota полностью блокирует действие после достижения лимита. Например: «Лимит генераций на сегодня исчерпан». Мягкая quota предупреждает заранее или переводит клиента в ограниченный режим. Например: после 80% лимита отправить уведомление; после 100% замедлить выполнение; после 120% включить оплату overage; для enterprise-клиента не блокировать, а отправить alert менеджеру. В B2B-продуктах это особенно важно. Внезапно отключить крупного клиента из-за автоматического лимита - не всегда лучшая идея. Иногда правильнее защитить инфраструктуру, но оставить пространство для коммерческого решения.
Rate limit vs Quota
Частота vs бюджет за период.
Weighted limits: не все запросы весят одинаково
Обычный rate limit считает запросы штуками. Weighted limits считают условную стоимость.
Например
• GET /status - 1 unit
• GET /items - 2 units
• POST /search - 10 units
• POST /export - 100 units
• POST /ai/generate - 300 units.
Клиенту можно дать 1000 units в час. Тогда он сам выбирает, как их тратить: много дешёвых запросов или несколько дорогих. Это похоже на электрический щиток в офисе. Неважно, сколько устройств включено. Важно, сколько суммарной мощности они потребляют. Для API такой подход намного честнее. Он позволяет не душить нормальную активность и при этом не давать одному пользователю забрать весь CPU, RAM или GPU.
Как оценивать вес запроса
Не обязательно сразу строить сложную экономическую модель. Начать можно с приблизительных коэффициентов.
Смотрите на
• среднее время выполнения
• p95 и p99 latency
• CPU time
• потребление RAM
• количество SQL-запросов
• объём чтения и записи
• размер ответа
• egress bandwidth
• обращения к внешним сервисам
• стоимость LLM-токенов
• занятость GPU
вероятность ретраев. Первую версию весов можно назначить руками. Потом - уточнять по метрикам. Важно не стремиться к идеальной математике с первого дня. Даже грубая модель «дешёвый, средний, дорогой, очень дорогой» уже лучше, чем один общий лимит на всё API.
Защита CPU: таймауты, сложность операций и очереди
CPU часто страдает от запросов, которые запускают тяжёлую бизнес-логику. Это могут быть расчёты, фильтрация, сериализация больших объектов, генерация файлов, сложные regex, обработка изображений или неудачные алгоритмы с плохой асимптотикой. Первое правило - у каждого запроса должен быть таймаут. Если операция не уложилась в разумное время, её нужно остановить, а не надеяться, что «ещё чуть-чуть и закончит». Запрос без таймаута похож на дверь без замка: вроде бы удобно, пока кто-то не начнёт пользоваться этим слишком активно.
Что ограничивать для CPU-heavy endpoint
Для CPU-защиты полезны: request timeout на уровне reverse proxy; timeout в приложении; timeout для запросов к базе; лимит сложности операции; ограничение количества элементов в одном запросе; запрет слишком широких фильтров; ограничение глубины сортировки и вложенности; перенос тяжёлых задач в очередь; отдельный worker pool для дорогих операций; circuit breaker при перегрузке. Например, генерацию отчёта лучше не выполнять синхронно внутри HTTP-запроса. Клиент отправляет задачу, получает job ID, а результат забирает позже. Так API остаётся отзывчивым, а тяжёлая работа управляется через очередь. Очередь - это не просто техническая деталь. Это клапан давления. Без него каждый пик нагрузки напрямую бьёт по приложению.
Защита RAM: размер тела запроса, пагинация и потоковая обработка
RAM часто расходуется незаметно. Один пользователь загрузил большой JSON. Второй попросил huge response. Третий открыл export на миллион строк. Четвёртый запустил batch-операцию. Через несколько минут garbage collector нервничает, контейнеры рестартятся, а команда ищет «утечку памяти», которой может и не быть. Иногда проблема не в leak, а в отсутствии лимитов.
Что помогает контролировать память
Базовые меры: ограничить maximum request body size; ограничить upload file size; проверять Content-Length до обработки; не читать большие файлы целиком в память; использовать streaming; ограничить page size; запретить неограниченную вложенность JSON; ограничить количество IDs в batch-запросе; задавать memory limits для контейнеров; разделять worker pools по типу нагрузки. Простой пример: endpoint принимает список ID для массового обновления. Если не поставить лимит, клиент может отправить 10 ID, 10 000 ID или 1 000 000 ID. Для бизнеса это «одна операция». Для сервера - совершенно разные сценарии. Нормальная защита начинается с вопроса: «Какой максимальный размер запроса мы готовы обработать без риска для соседних клиентов?»
Защита bandwidth: трафик тоже стоит денег
Bandwidth часто воспринимают как второстепенный ресурс. Пока не приходит счёт или пока канал не начинает забиваться большими ответами. API может тратить трафик на: большие JSON-ответы; выгрузки CSV, XLSX, PDF; скачивание файлов; изображения и видео; проксирование данных; webhooks; стриминг ответов AI API; повторные запросы клиентов при ошибках. Даже если CPU и RAM в порядке, bandwidth может стать узким местом. Особенно у продуктов с большим количеством интеграций или публичными endpoint.
Как снижать риск перерасхода трафика
Хороший минимум: лимитировать размер ответа; использовать пагинацию; не отдавать «все поля сразу» без необходимости; включать сжатие там, где это уместно; использовать CDN для статических файлов; отдавать большие файлы через signed URLs; ограничивать скорость скачивания для отдельных клиентов; учитывать egress traffic в quota; не разрешать бесконечные export без фильтров; кэшировать повторяемые ответы. Например, если клиент каждые 5 секунд забирает один и тот же большой справочник, это не проблема безопасности в классическом смысле. Но это проблема дизайна API. Тут помогут ETag, If-None-Match, cache headers и нормальная стратегия обновления данных.
AI API и LLM: новая категория дорогих запросов
С появлением AI API тема unrestricted resource consumption стала заметно острее. Раньше дорогой запрос обычно нагружал CPU, базу или storage. Теперь один запрос может напрямую тратить LLM-токены, GPU-время и деньги на внешнего провайдера. Проблема в том, что AI-запросы сложно оценивать только по факту HTTP-вызова. Два запроса к одному endpoint могут отличаться в десятки раз: короткий prompt на 200 токенов; длинный prompt на 30 000 токенов; RAG-запрос с поиском по векторной базе; генерация на 500 токенов; генерация на 8000 токенов; вызов дорогой модели вместо лёгкой; цепочка tool calls внутри агента. Для клиента это всё может выглядеть как «один запрос на генерацию». Для инфраструктуры - разные классы стоимости.
Что лимитировать в LLM API
Для AI API нужны отдельные ограничения: maximum input tokens; maximum output tokens; daily token quota; monthly token quota; лимит запросов к дорогим моделям; лимит параллельных генераций; очередь на GPU-инференс; timeout генерации; лимит tool calls; лимит документов в RAG-контексте; лимит размера загружаемых файлов; fallback на более дешёвую модель; кэширование повторяемых запросов; budget per user, workspace или API key. Особенно важно ограничивать max_tokens. Если дать клиенту самому выбирать длину ответа без верхней границы, он может случайно или намеренно запускать слишком длинные генерации. В AI-продуктах rate limits без token quotas похожи на охранника, который считает посетителей, но не замечает, что каждый выносит по серверной стойке.
GPU-ресурсы: защищаем не только сервер, но и очередь
GPU отличается от обычного CPU тем, что перегрузка часто проявляется через очередь. Запросы не всегда падают сразу. Они ждут. Потом ждут ещё. Потом клиенты начинают повторять запросы, очередь растёт быстрее, latency взлетает, и система сама усиливает проблему. Для AI API и ML-сервисов важно ограничивать не только количество запросов, но и concurrency.
Например
• не больше 2 активных GPU-задач на пользователя
• не больше 10 активных задач на workspace
• отдельная очередь для free-плана
• приоритетная очередь для платных клиентов
• ограничение длины очереди
• отмена задач при disconnect клиента
• дедупликация одинаковых задач
• backpressure вместо бесконечного накопления.
Backpressure - это когда система честно говорит: «Сейчас слишком много работы, попробуйте позже», вместо того чтобы молча принимать задачи до полного истощения. Для API это нормальное поведение. Ответ 429 или 503 с понятным Retry-After лучше, чем зависший запрос, таймаут на клиенте и повторная атака ретраями.
GPU: очередь усиливает проблему
Клиенты ретраят → очередь растёт → latency взлетает.
Внешние платные API: скрытая дыра в бюджете
Иногда сервер почти не нагружается, но запрос всё равно дорогой. Почему? Потому что внутри API вызывает платный внешний сервис.
Это может быть
• SMS-провайдер
• email-сервис
• геокодинг
• проверка документов
• антифрод
• распознавание изображений
• платежный провайдер
• LLM-платформа
• сервис биометрии
обогащение данных. Без quotas такой endpoint превращается в открытую кассу. Пользователь делает запросы к вашему API, а платите вы - внешнему поставщику. Мини-пример: endpoint /send-verification-code без лимитов может отправлять SMS снова и снова. Даже если злоумышленник не получает доступ к аккаунтам, он способен создать прямые расходы. Для таких endpoint нужны особенно строгие правила: лимит отправок на номер телефона; лимит на пользователя; лимит на IP; cooldown между попытками; CAPTCHA или risk-based challenge при подозрительном поведении; budget на tenant; алерты по стоимости; блокировка повторной отправки одинакового действия. Важно считать не только технический риск, но и цену каждого вызова.
Параллельность: тихий убийца стабильности
Даже если каждый отдельный запрос безопасен, много параллельных запросов могут создать проблему. Представьте endpoint, который выполняется 5 секунд и потребляет умеренно много памяти. Один запрос - нормально. Десять - терпимо. Тысяча - уже пожар. Поэтому rate limits нужно дополнять concurrency limits.
Где особенно нужны лимиты параллельности
Они критичны для
• export и report задач
• AI generation
• обработки файлов
• видео и аудио
• массовых операций
• тяжёлых поисковых запросов
• web scraping
• миграций
• batch import
запросов к медленным внешним API. Concurrency limit отвечает на вопрос: «Сколько таких операций один клиент может держать активными одновременно?» Это сильно отличается от rate limit. Клиент может сделать всего 5 запросов в минуту, но если каждый выполняется 10 минут, через час у вас уже длинный хвост активных задач.
Pagination и filtering: защита начинается с дизайна API
Многие проблемы resource consumption закладываются ещё на этапе проектирования endpoint. Классический пример - список объектов без нормальной пагинации: GET /api/events На тестовой базе всё быстро. На production через год этот endpoint возвращает сотни тысяч строк, сериализует огромный JSON и тянет за собой связанные сущности. Правильнее сразу проектировать API так, чтобы «получить всё» было невозможно или хотя бы явно ограничено.
Практичные правила
Для списков
• limit должен иметь максимум
• default limit должен быть разумным
• offset pagination не стоит использовать для очень глубоких страниц без контроля
• cursor pagination часто лучше для больших данных
• сортировка должна быть ограничена разрешёнными полями
• фильтры должны быть индексируемыми
• wildcard-поиск нужно контролировать
поля ответа лучше выбирать явно или через safe presets.
Для batch endpoint
• ограничьте количество объектов в одном запросе
• валидируйте размер payload
• возвращайте частичный результат аккуратно
• тяжёлые batch-операции выносите в async jobs
не смешивайте быстрые и тяжёлые операции в одном endpoint. Хороший API не заставляет клиента угадывать, где граница допустимого. Он показывает эту границу заранее.
429 Too Many Requests: ошибка, которая должна помогать

Когда лимит срабатывает, важно не просто отказать. Нужно объяснить клиенту, что произошло и когда можно повторить запрос. Плохой ответ: Error Нормальный ответ: 429 Too Many Requests С телом: { "error": "rate_limit_exceeded", "message": "Too many requests for this endpoint. Please retry later.", "limit": 100, "window": "60s", "retry_after": 27} И заголовками: Retry-After: 27X-RateLimit-Limit: 100X-RateLimit-Remaining: 0X-RateLimit-Reset: 1710000000 Для разработчика, который интегрируется с API, это не мелочь. Хорошие ошибки уменьшают количество тикетов, неправильных retry-циклов и случайной нагрузки. Если клиент понимает правила, он легче пишет корректную интеграцию.
Retry policy: как клиенты случайно устраивают DDoS
Одна из самых неприятных причин API abuse - агрессивные ретраи. Сервис немного замедлился. Клиент не дождался ответа. Повторил запрос. Потом ещё раз. Потом параллельно. Если таких клиентов много, перегрузка усиливается. Это похоже на пробку: каждый водитель пытается быстрее проскочить, но в итоге все стоят дольше. Чтобы этого избежать, API должен не только ограничивать запросы, но и подсказывать правильное поведение: использовать Retry-After; документировать exponential backoff; добавлять jitter; поддерживать idempotency keys; не выполнять повторно уже принятую дорогую операцию; возвращать статус async job вместо повторного запуска; ограничивать количество повторов. Idempotency key особенно полезен для платных или тяжёлых операций. Если клиент повторил запрос из-за сетевой ошибки, сервер может вернуть результат уже созданной операции, а не запускать её заново.
Idempotency: защита от дублей и случайных расходов
Idempotency означает, что повтор одного и того же запроса не создаёт повторный эффект. Для API это критично в операциях вроде: создание платежа; запуск генерации; отправка SMS; создание export; запуск ML-задачи; массовое обновление данных. Клиент отправляет Idempotency-Key, сервер сохраняет связанный результат. Если запрос повторяется с тем же ключом, API возвращает прежний результат. Это защищает и пользователя, и инфраструктуру. Без idempotency один timeout может превратиться в несколько одинаковых задач. Особенно больно это в AI API: клиент не получил ответ за 30 секунд, повторил запрос, а первая генерация всё ещё выполняется на GPU.
Кэширование: самый приятный запрос - тот, который не нужно выполнять
Кэш не заменяет rate limits и quotas, но отлично снижает нагрузку. Если endpoint часто возвращает одинаковые данные, его стоит кэшировать. Если AI API получает повторяемые prompt, можно кэшировать часть результата или промежуточные вычисления. Если RAG-система каждый раз извлекает одни и те же документы, можно кэшировать retrieval.
Кэширование особенно полезно для
• справочников
• публичных данных
• expensive read operations
• результатов поиска
• metadata
• feature flags
• embeddings
• повторяемых AI-запросов
precomputed reports. Но кэш должен быть безопасным. Нельзя случайно отдать данные одного tenant другому. Ключ кэша должен учитывать пользователя, workspace, права доступа, параметры запроса и версию данных. Правильно настроенный кэш - это как короткая дорога через парк. Главное, чтобы она не вела через чужой двор.
Изоляция клиентов: один tenant не должен съедать всех
В multi-tenant SaaS один клиент может повлиять на других. Это одна из самых неприятных ситуаций: платёжеспособный спокойный клиент страдает из-за чужой интеграции, которая ушла в цикл. Поэтому важно вводить per-tenant isolation: отдельные quotas для tenant; отдельные очереди; лимиты concurrency на workspace; приоритеты по тарифам; fair scheduling; лимиты на background jobs; лимиты на storage и bandwidth; отдельные worker pools для крупных клиентов. На инфраструктурном уровне иногда помогает физическое или логическое разделение: отдельные VPS, выделенные серверы, контейнерные лимиты, разные базы или очереди для крупных нагрузок. Это особенно актуально, когда клиентские профили сильно различаются. Один использует API пару раз в день, другой гоняет high-load-интеграцию 24/7.
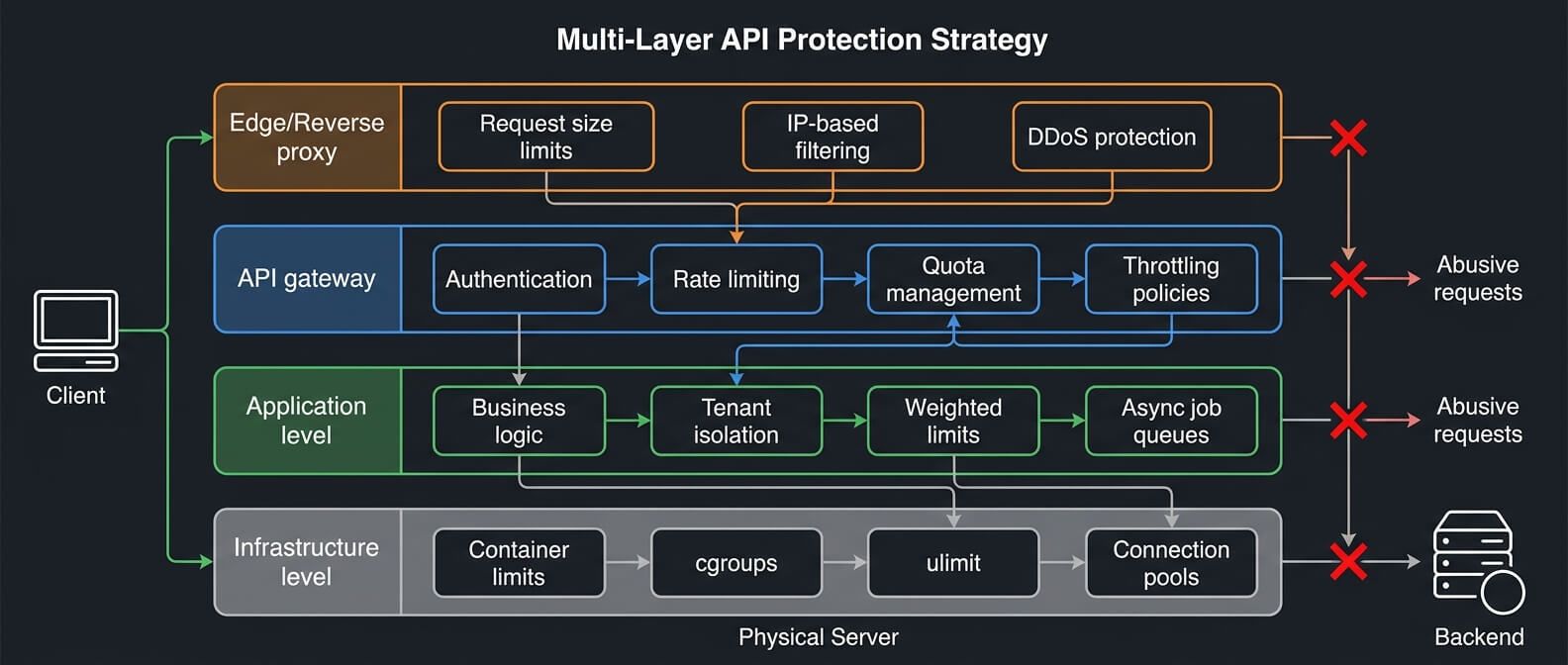
Серверный уровень: где ставить ограничения
API abuse protection нельзя строить только в приложении. Защита должна быть многослойной. Часть лимитов лучше ставить на edge или reverse proxy. Часть - в API gateway. Часть - в приложении, где доступен бизнес-контекст. Часть - на уровне базы, очередей, контейнеров и операционной системы.
На уровне reverse proxy
Например, Nginx или другой reverse proxy может ограничивать
• размер тела запроса
• скорость запросов
• количество соединений
• время ожидания
• upload timeout
• response timeout
базовую частоту обращений по IP. Это быстрый внешний контур. Он не знает всех деталей продукта, но хорошо отсекает грубые перегрузки.
На уровне API gateway
API gateway может учитывать
• API key
• тарифный план
• endpoint
• route group
• authentication context
• usage plan
• quotas
• throttling
• заголовки rate limit.
Это удобное место для централизованной политики.
На уровне приложения
Только приложение обычно понимает, что именно делает запрос.
Оно знает
• сколько объектов пользователь пытается обработать
• какой tenant делает запрос
• какая модель выбрана
• какой тариф активен
• сколько токенов будет потрачено
• насколько тяжёлый фильтр
• можно ли выполнить задачу асинхронно
нужно ли включить дополнительную проверку. Поэтому самые точные лимиты почти всегда живут в приложении.
На уровне инфраструктуры
Инфраструктура должна ставить последнюю линию обороны
• cgroups и container memory limits
• CPU limits
• ulimit
• лимиты file descriptors
• connection pool limits
• database statement timeout
• worker process limits
• queue length limits
• autoscaling policies
отдельные серверы для тяжёлых задач. Даже если приложение ошиблось, инфраструктура не должна позволять одному процессу забрать всё.
Многослойная защита
Proxy → gateway → приложение → инфраструктура.
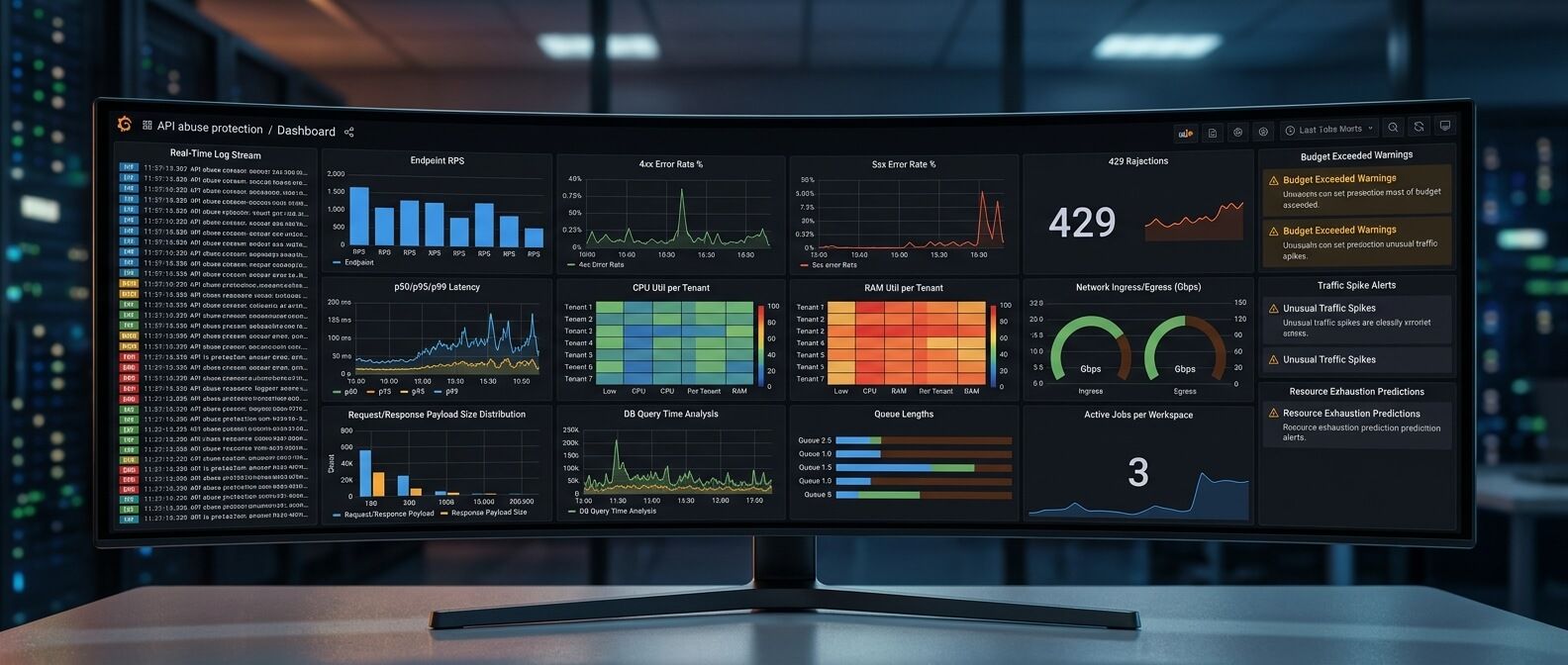
Мониторинг: нельзя защитить то, что не измеряется

API abuse protection без мониторинга быстро превращается в набор догадок. Нужно видеть не только общий RPS, но и стоимость нагрузки. Иначе можно пропустить ситуацию, когда запросов немного, а ресурсов они потребляют слишком много.
Какие метрики отслеживать
Полезный набор
• requests per second по endpoint
• 4xx и 5xx по endpoint
• количество 429
• latency p50, p95, p99
• CPU usage
• memory usage
• network ingress и egress
• размер request и response
• database query time
• slow queries
• queue length
• job duration
• active jobs per tenant
• API usage per key
• token usage для LLM
• GPU utilization
• GPU queue time
• cost per user или tenant
• external API calls
cache hit ratio. Особое внимание - разрезам по tenant, API key и endpoint. Средняя температура по больнице бесполезна, если один клиент аккуратно сжигает половину инфраструктуры.
Alerting: когда лимиты должны звать человека
Автоматические лимиты хороши, но не все ситуации нужно решать блокировкой. Иногда нужен alert.
Например
• конкретный tenant резко увеличил потребление
• endpoint стал в 10 раз медленнее
• 429 выросли после релиза
• расходы на LLM за день превысили норму
• GPU queue держится дольше 5 минут
• egress traffic растёт необычно быстро
• один API key делает нетипичные запросы
количество export-задач выше обычного. Такие сигналы помогают поймать проблему до того, как клиент пожалуется или счёт за инфраструктуру испортит утро. Хорошая практика - строить алерты не только по техническим метрикам, но и по бизнесовым бюджетам. Например: «этот workspace потратил 80% месячной token quota за 3 дня».
Как внедрять API abuse protection без боли
Не обязательно за один спринт построить идеальную систему лимитов. Лучше идти постепенно.
Шаг 1. Найти самые дорогие endpoint
Сначала составьте карту API. Отметьте endpoint, которые: работают долго; часто падают по timeout; возвращают большие ответы; вызывают внешние сервисы; запускают background jobs; используют AI или GPU; создают расходы; уже становились причиной инцидентов. Обычно 20% endpoint создают 80% риска.
Шаг 2. Ввести базовые технические лимиты
Минимальный набор: request body size; upload size; timeout; page size; batch size; max response size; connection limits; database statement timeout; worker concurrency. Это не ломает продуктовую логику, но закрывает самые очевидные дыры.
Шаг 3. Добавить rate limits по ключевым измерениям
Начните с: IP; API key; user ID; tenant ID; endpoint group. Для дорогих endpoint лимиты должны быть отдельными. Не смешивайте /health, /profile и /ai/generate в одну корзину.
Шаг 4. Ввести quotas
Затем добавьте дневные или месячные quotas: requests; exports; uploaded data; downloaded data; AI tokens; GPU minutes; external API calls. Quotas лучше привязать к тарифам и документации. Клиент должен понимать, что входит в его план.
Шаг 5. Настроить наблюдаемость
Пока нет метрик, лимиты будут спором мнений. С метриками разговор становится предметным. Смотрите, кто потребляет ресурсы, какие endpoint дорожают, где latency растёт, какие клиенты чаще упираются в лимиты.
Шаг 6. Улучшать UX ошибок
Лимит - не наказание. Это правило движения.
Покажите клиенту
• какой лимит сработал
• когда можно повторить запрос
• как уменьшить нагрузку
• где посмотреть текущий usage
как перейти на другой тариф или запросить увеличение лимита. Так защита не выглядит внезапной стеной. Она становится частью нормального API-контракта.
Что важно документировать для разработчиков

Публичная документация по лимитам экономит много времени support-команде и клиентам.
Стоит указать
• общие rate limits
• endpoint-specific limits
• quotas по тарифам
• правила расчёта дорогих операций
• максимальный размер payload
• максимальный размер файла
• максимальный page size
• лимиты для batch-запросов
• лимиты для AI API
• формат 429
• заголовки rate limit
• retry policy
• рекомендации по backoff
• правила idempotency
• контакты для запроса повышенных лимитов.
Если API используется партнёрами, документация становится частью защиты. Разработчик на стороне клиента может написать аккуратную интеграцию только тогда, когда правила понятны заранее.
Частые ошибки при защите API от дорогих запросов
Ошибка 1. Один общий лимит на всё API
Это проще настроить, но почти всегда недостаточно. Дешёвые и дорогие endpoint требуют разных правил.
Ошибка 2. Лимит только по IP
IP-лимит полезен, но он не понимает пользователей, тарифы, tenant и API keys. Для SaaS этого мало.
Ошибка 3. Нет лимитов внутри одного запроса
Даже при строгом rate limit один запрос может попросить слишком много: большой файл, огромный batch, глубокую пагинацию, длинный LLM-контекст.
Ошибка 4. Синхронное выполнение тяжёлых задач
Если export, ML-processing или генерация отчёта выполняются прямо в HTTP-запросе, система становится хрупкой. Очереди и async jobs часто решают проблему элегантнее.
Ошибка 5. Нет контроля внешних расходов
Если endpoint вызывает платный сервис, он должен иметь quota и budget alert. Иначе технически лёгкий запрос может оказаться финансово тяжёлым.
Ошибка 6. Непонятные ошибки для клиента
Если API просто возвращает 403 или пустой 500, клиенты начинают повторять запросы, писать в поддержку и усиливать нагрузку. Хороший 429 снижает хаос.
Ошибка 7. Лимиты не пересматриваются
Продукт растёт, клиенты меняются, endpoint становятся тяжелее. Лимиты нужно периодически проверять по реальным данным.
API abuse protection для VPS и выделенных серверов
Если проект работает на VPS или выделенных серверах, контроль ресурсов особенно важен. У вас есть конкретный объём CPU, RAM, диска и сетевого канала. Даже если сервер мощный, он не бесконечный. Хорошая новость: при грамотной настройке VPS или dedicated server даёт понятную и управляемую среду. Можно точно видеть нагрузку, отделять сервисы, выносить тяжёлые задачи на отдельные машины, настраивать очереди, мониторинг и лимиты под свой продукт.
Например
• API-приложение работает на одном сервере
• Redis используется для rate limiting и очередей
• PostgreSQL вынесен отдельно
• worker для export-задач работает отдельно от web-процесса
• AI inference запускается на сервере с GPU
• мониторинг собирает метрики CPU, RAM, bandwidth и latency
• алерты предупреждают о росте 429 или очередей.
Такая архитектура не обязательно сложная. Главное - не складывать все типы нагрузки в одну корзину без ограничений.
VPS / dedicated: разделение нагрузок
Web, workers, GPU, Redis rate limit — не одна корзина.
Небольшой чек-лист для команды
Перед релизом нового API endpoint полезно пройти короткий список вопросов:
• Сколько CPU может потребить один запрос?
• Сколько RAM он может занять?
• Какой максимальный размер request body?
• Какой максимальный размер response?
• Есть ли page size limit?
• Есть ли batch size limit?
• Есть ли timeout?
• Можно ли выполнить операцию асинхронно?
• Вызывает ли endpoint внешние платные API?
• Использует ли endpoint LLM, GPU или ML-модель?
• Есть ли rate limit на endpoint?
• Есть ли quota на пользователя, tenant или API key?
• Есть ли concurrency limit?
• Что получит клиент при превышении лимита?
• Видим ли мы usage по этому endpoint в мониторинге?
Если на несколько вопросов нет ответа, endpoint ещё не готов к реальной нагрузке.
Главная мысль: защищайте не только вход, но и стоимость работы
API abuse protection - это не про недоверие к пользователям. Это про зрелую инженерную гигиену. Любой API, который выполняет полезную работу, потребляет ресурсы. CPU считает, RAM хранит, bandwidth передаёт, база ищет, очередь ждёт, GPU генерирует, внешний сервис выставляет счёт. Если этим не управлять, даже легальные запросы могут стать проблемой. Rate limits помогают контролировать частоту. Quotas - общий бюджет. Weighted limits - реальную стоимость операций. Таймауты, ограничения размеров, очереди, idempotency, кэширование и мониторинг превращают API из хрупкой двери в нормальный промышленный шлюз. И чем раньше эти правила появляются в архитектуре, тем спокойнее растёт продукт. Серверы работают стабильнее, клиенты получают предсказуемый API, команда меньше тушит пожары, а инфраструктурные расходы становятся управляемыми. Начать можно с малого: найдите самые дорогие endpoint, поставьте базовые лимиты, добавьте понятный 429 и начните смотреть на API не только как на набор URL, а как на систему потребления ресурсов. Это уже большой шаг к устойчивой инфраструктуре.




