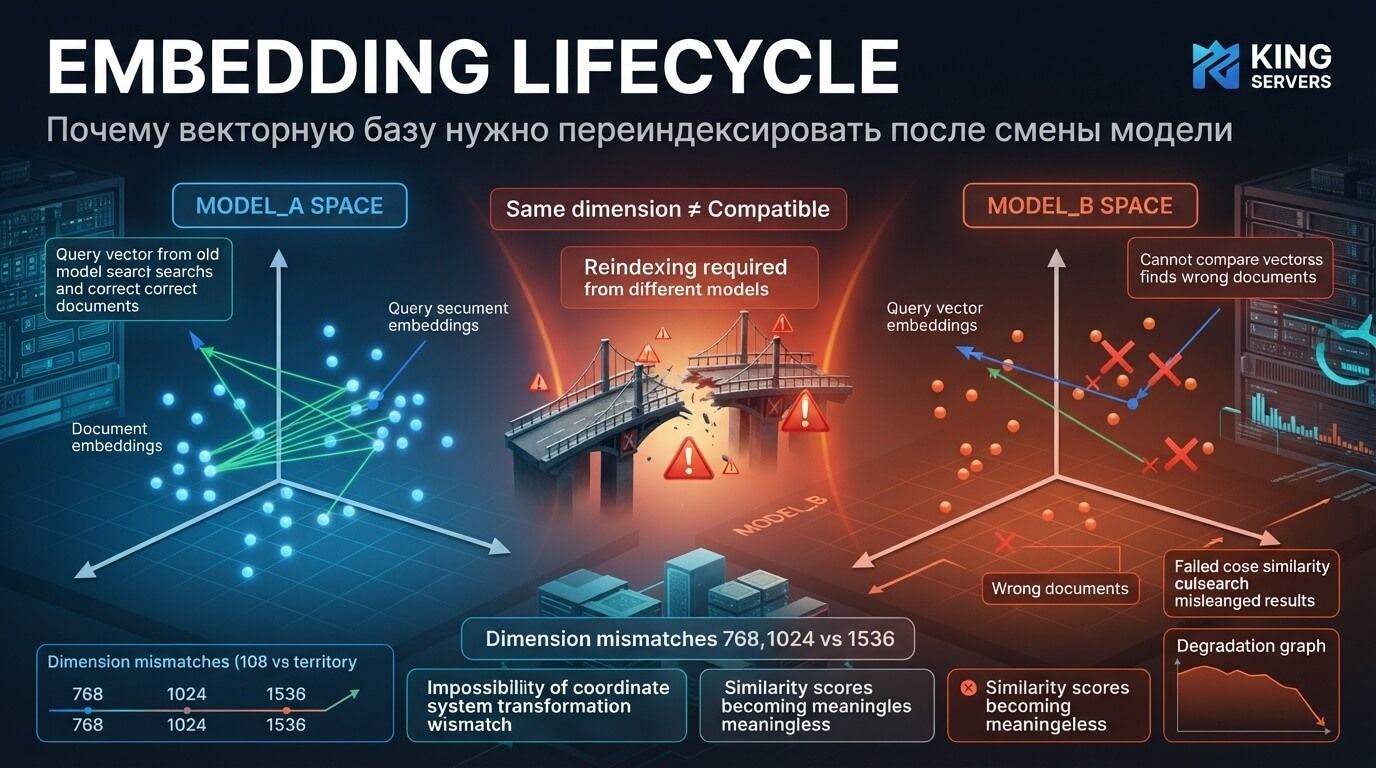
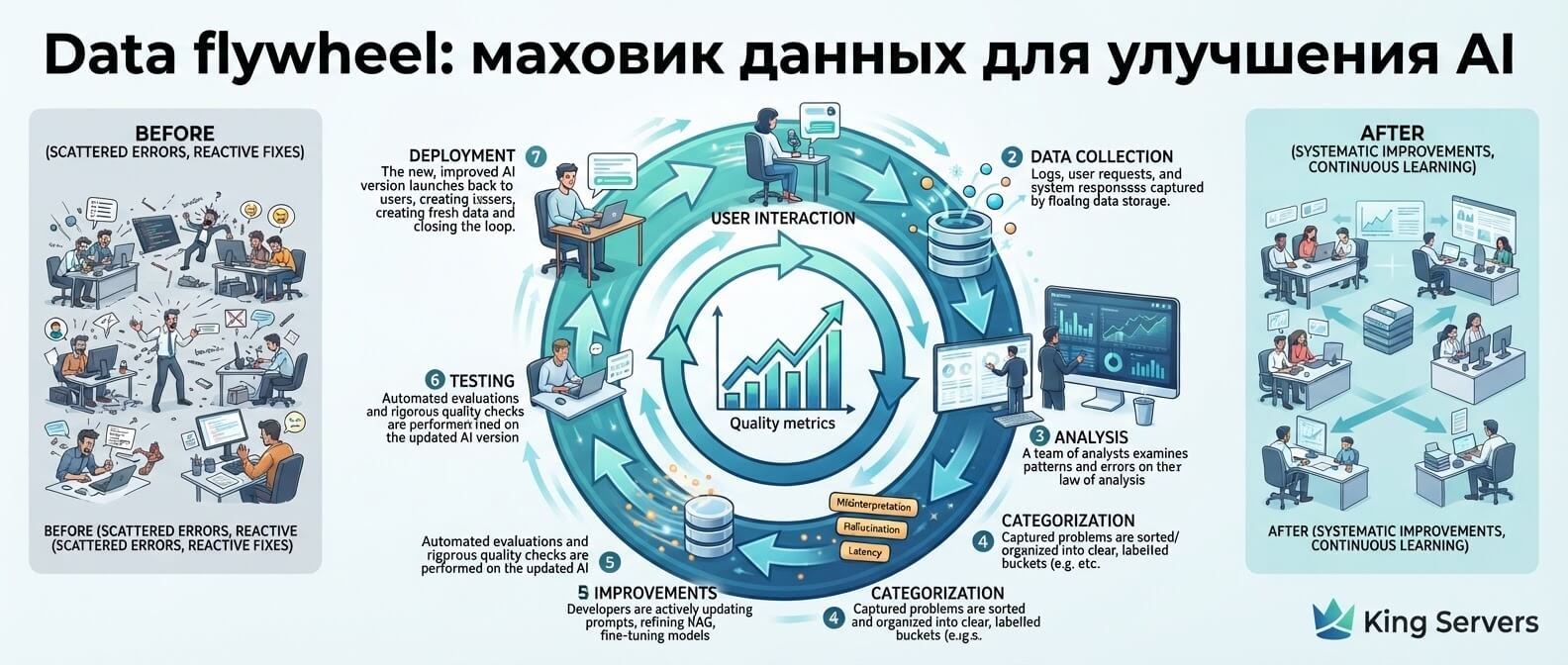
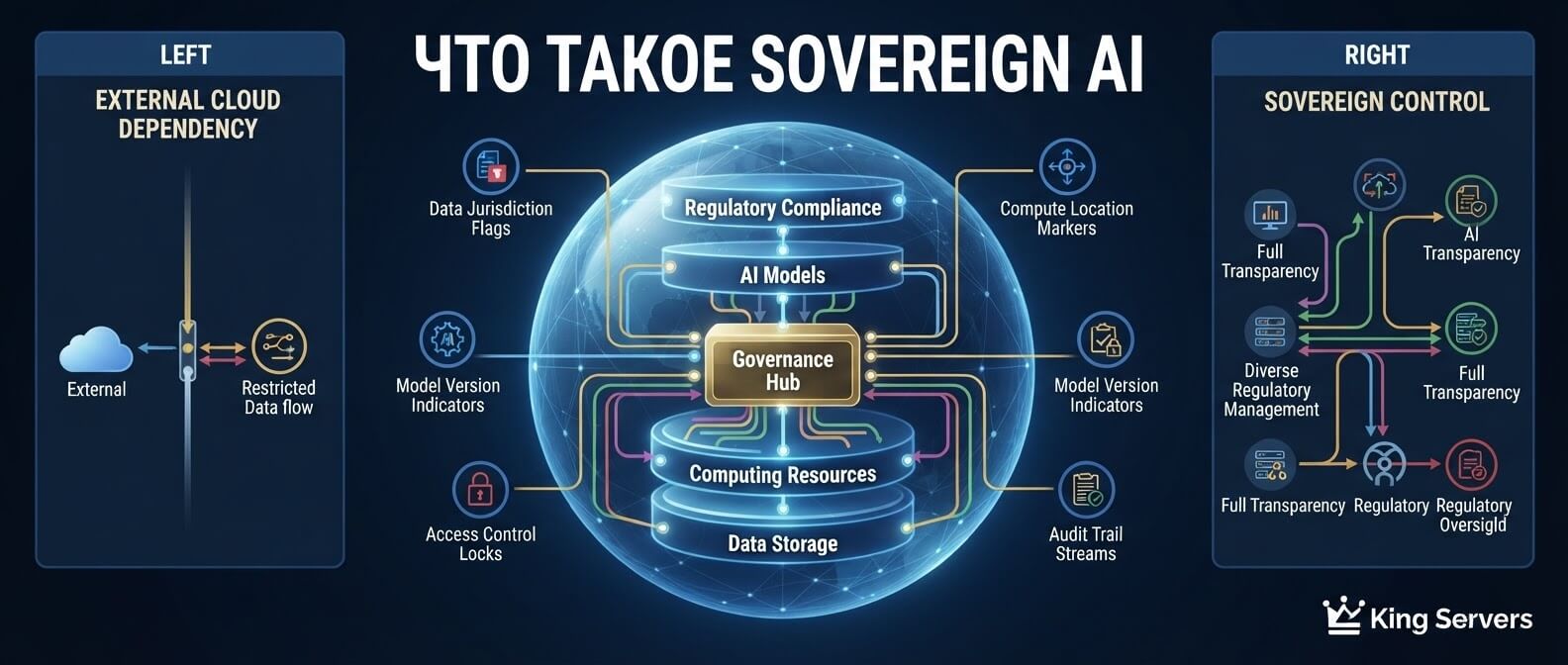
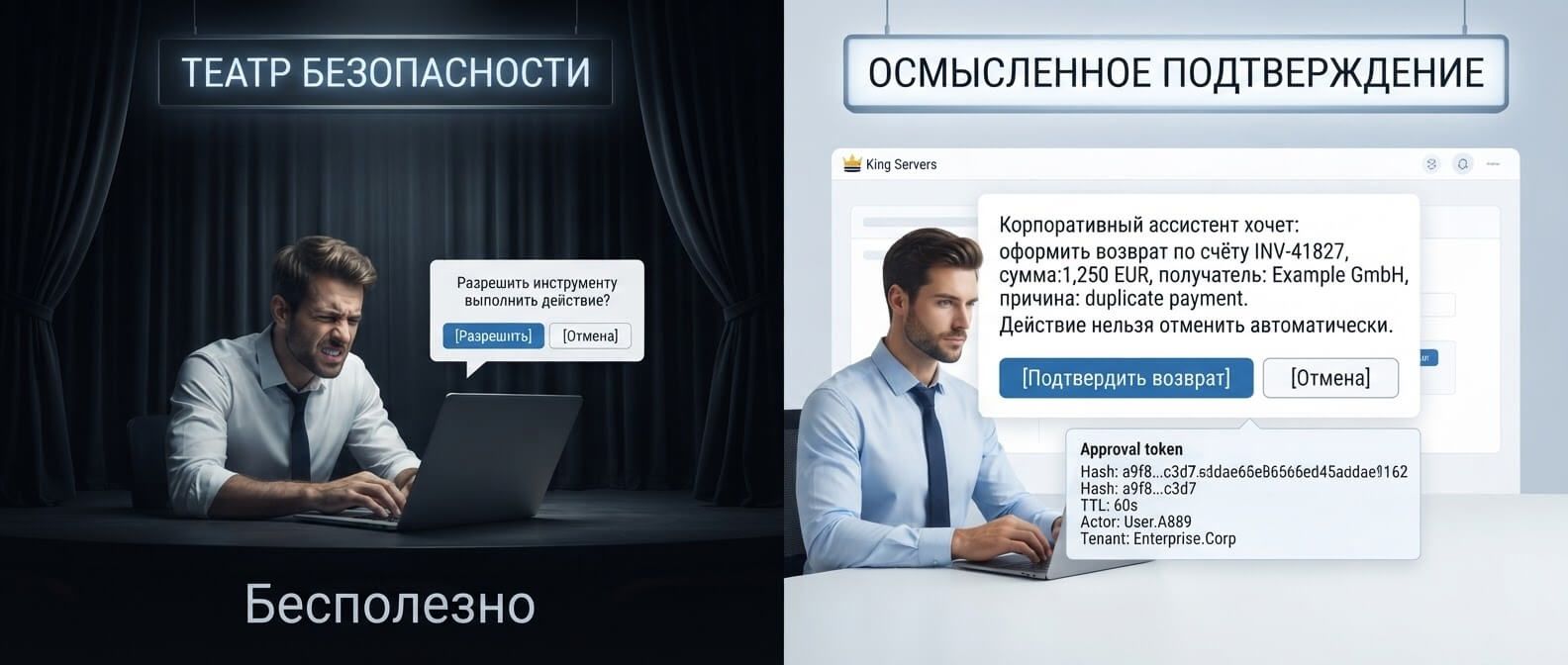
AI governance для компании: кто отвечает за нейросети, данные, риски и качество ответов
Практическое руководство по AI governance: роли и зоны ответственности, политики работы с данными, оценка поставщиков, контроль качества, аудит и пошаговое внедрение системы управления ИИ за 90 дней.
Андрей Минин, автор блога